




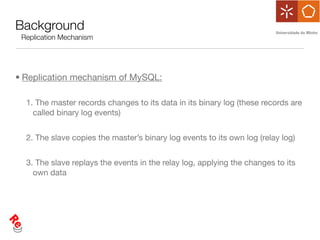
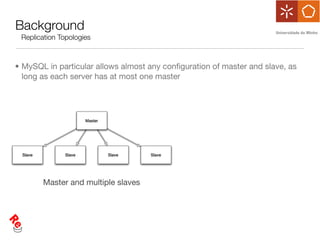
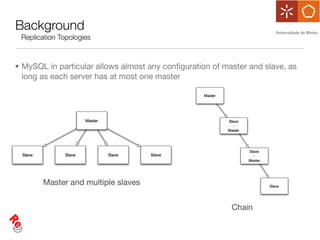
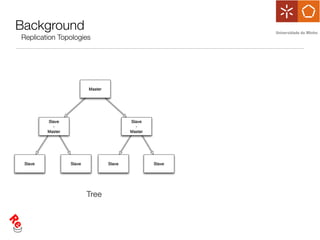
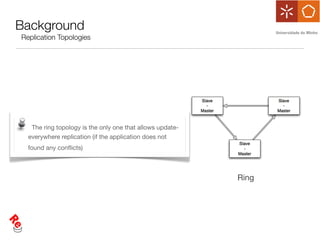






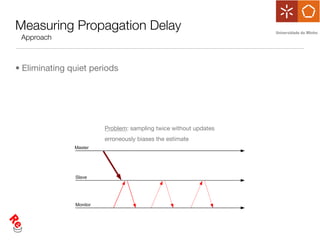




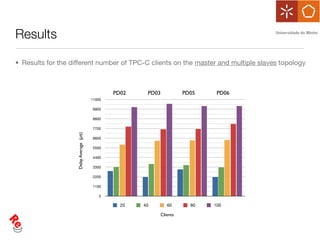
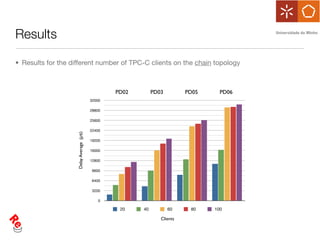




The document discusses the evaluation of data freshness in large-scale replicated databases, particularly focusing on MySQL replication mechanisms. It outlines different replication protocols, the impact of replication topology on scalability, and presents an experimental approach to measuring propagation delay and data freshness. Results indicate that delay in data freshness increases with workload, number of replicas, and hops, highlighting limitations in MySQL's scalability concerning data freshness.



























![[INSIGHT OUT 2011] A23 database io performance measuring planning(alex)](https://cdn.slidesharecdn.com/ss_thumbnails/insightout2011a23databaseioperformancemeasuringplanningalex-111114181900-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)















