Download to read offline











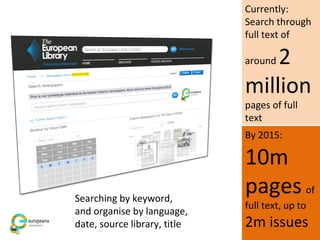

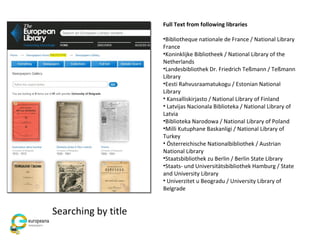
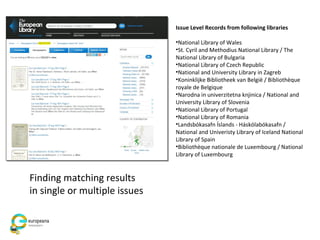














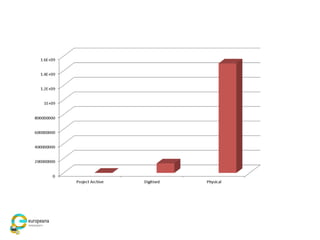





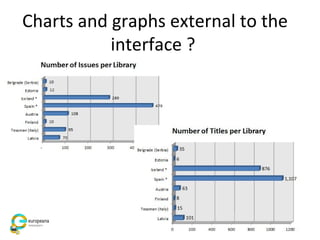



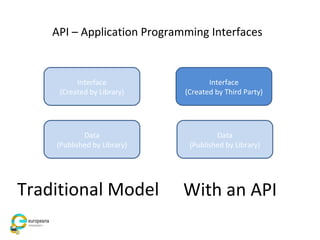


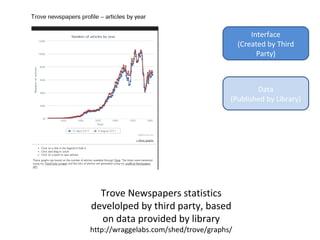







The document discusses the Europeana Newspapers project, focusing on a digital archive of historical newspapers and its impact on accessibility and usability in research. It highlights user feedback on the site's features, such as geographical search and frustrations regarding the lack of download options. The project aims to expand its digital library, improve user interface, and address various technical and licensing issues.







































































































