Download as PDF, PPTX











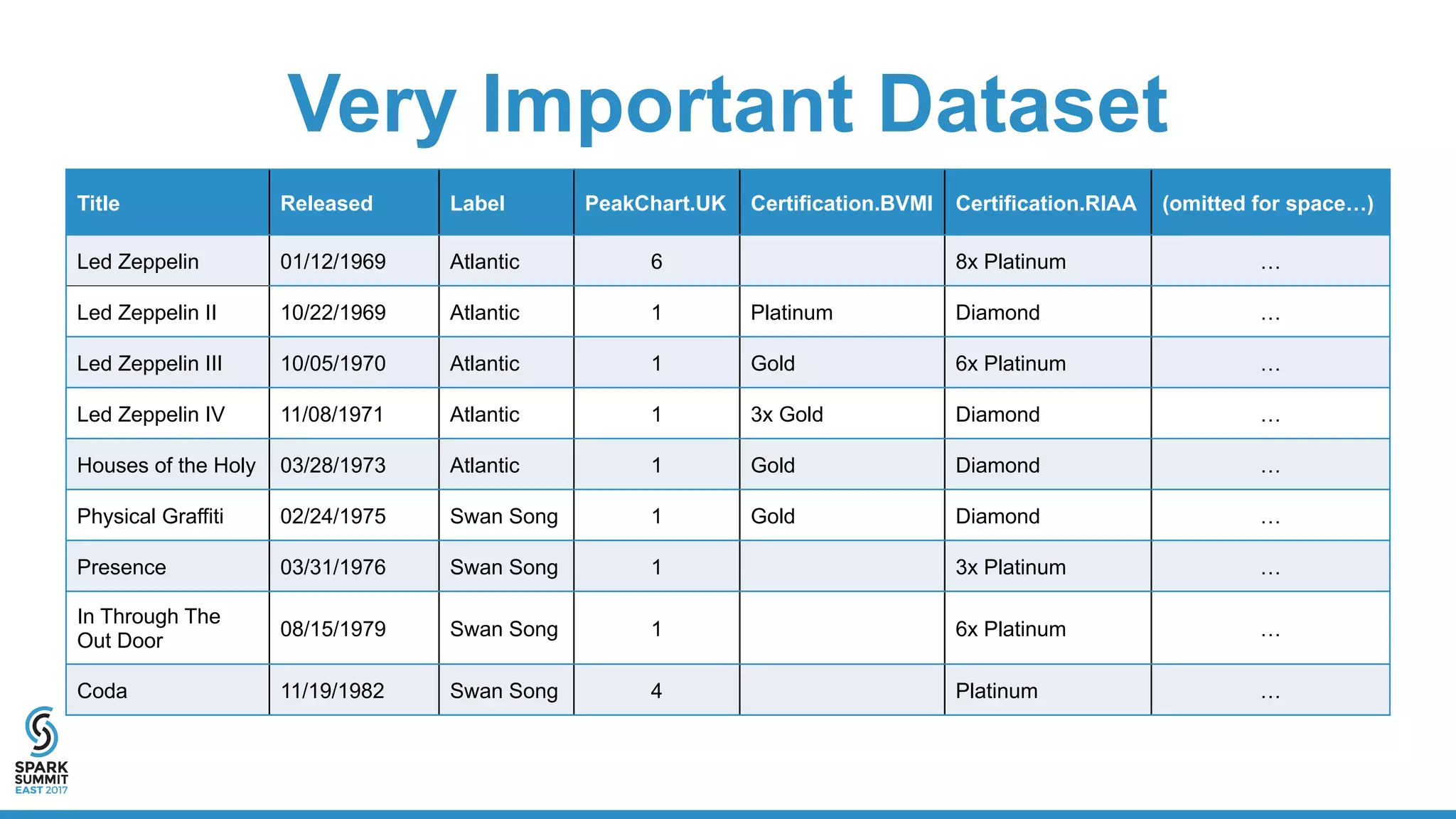




![Writing To Parquet: Flat Schema
/*Oh crap, the Ints are gonna get pulled in as Strings unless we transform*/
case class LedZeppelinFlat(
Title: Option[String],
Released: Option[String],
Label: Option[String],
UK: Option[Int],
AUS: Option[Int],
US: Option[Int],
ARIA: Option[String],
BPI: Option[String],
BVMI: Option[String],
CRIA: Option[String],
IFPI: Option[String],
NVPI: Option[String],
RIAA: Option[String],
SNEP: Option[String]
)](https://image.slidesharecdn.com/6bcurtinstrickland-170215222253/75/Spark-Parquet-In-Depth-Spark-Summit-East-Talk-by-Emily-Curtin-and-Robbie-Strickland-21-2048.jpg)


















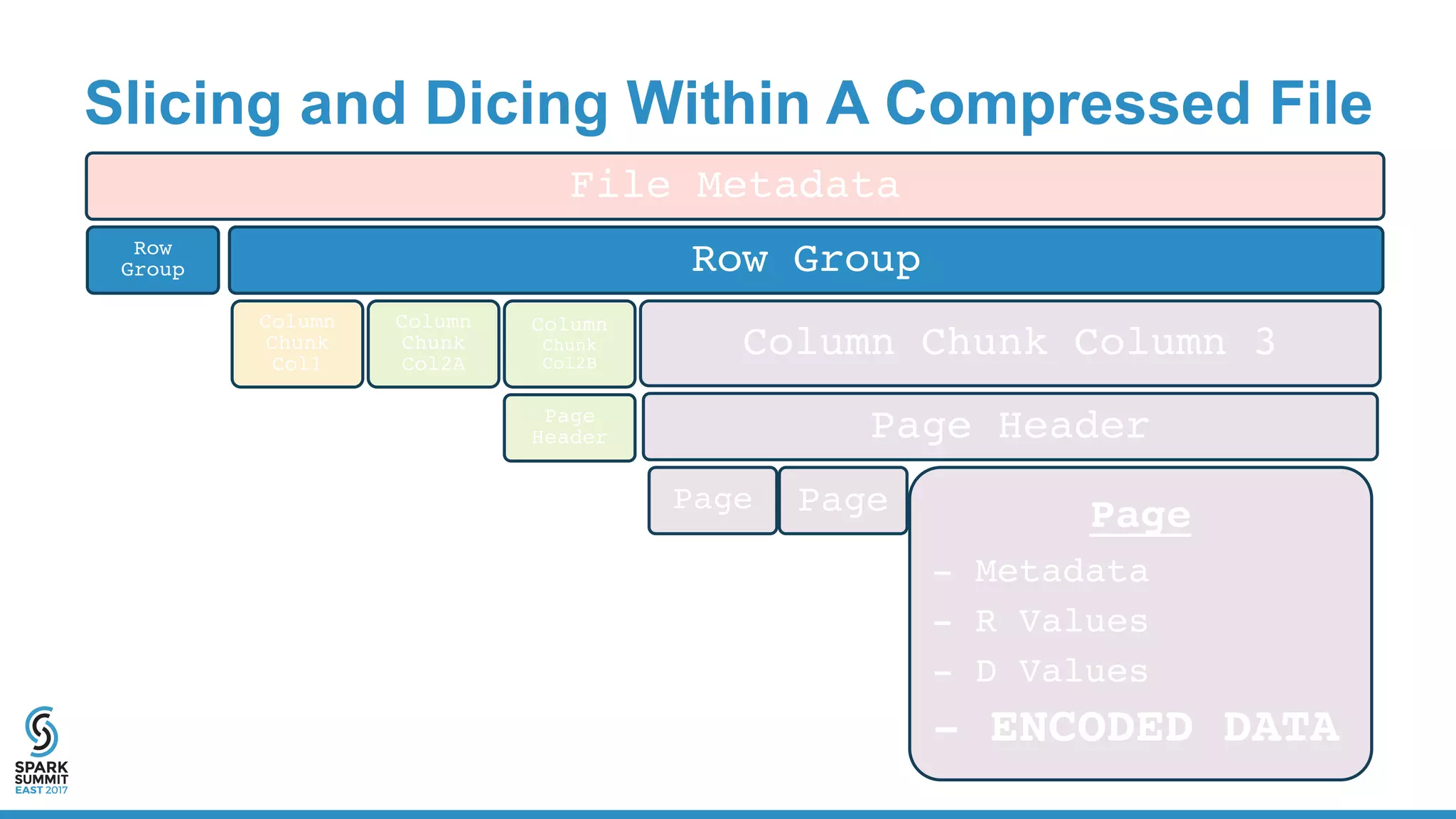
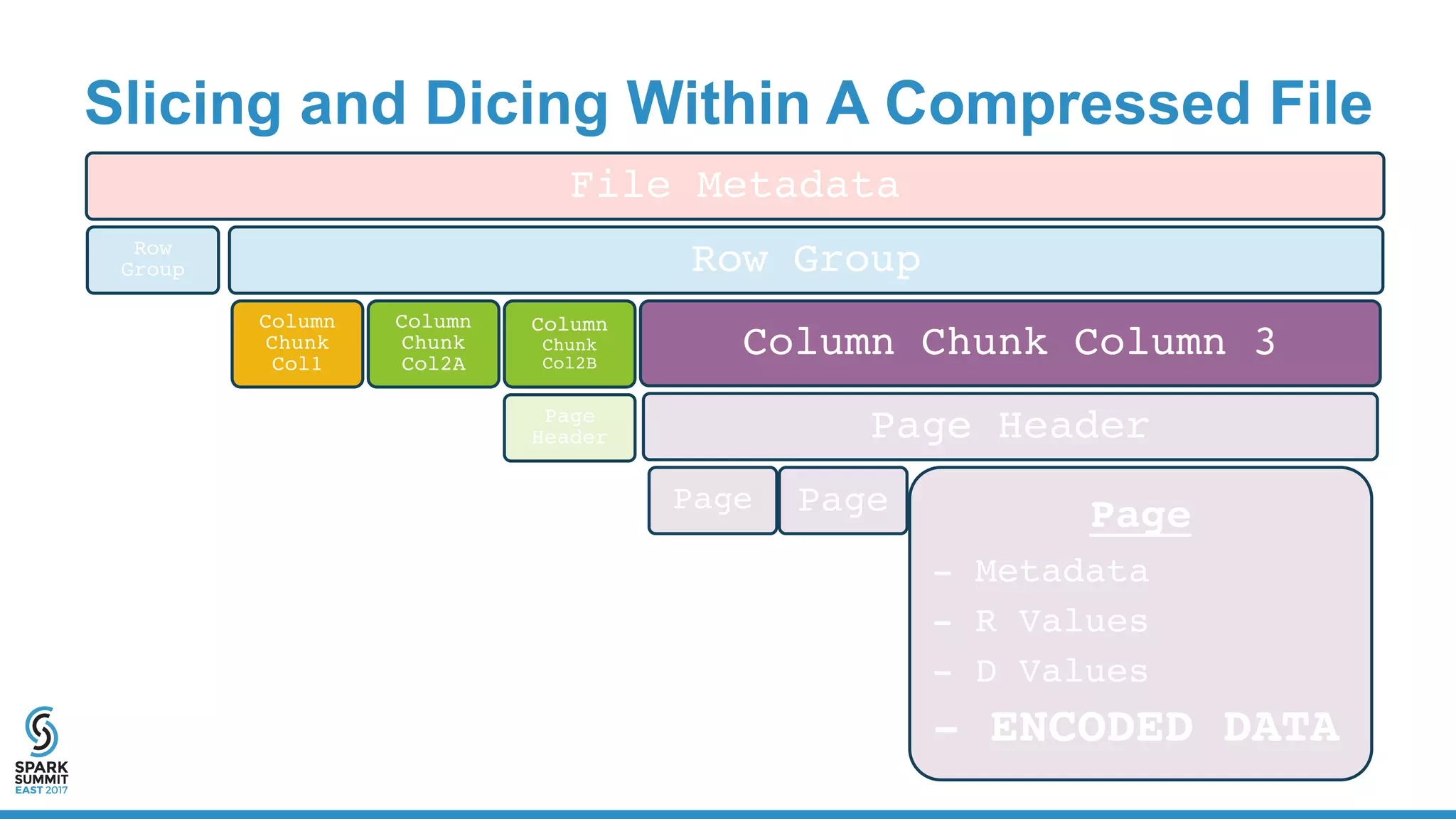
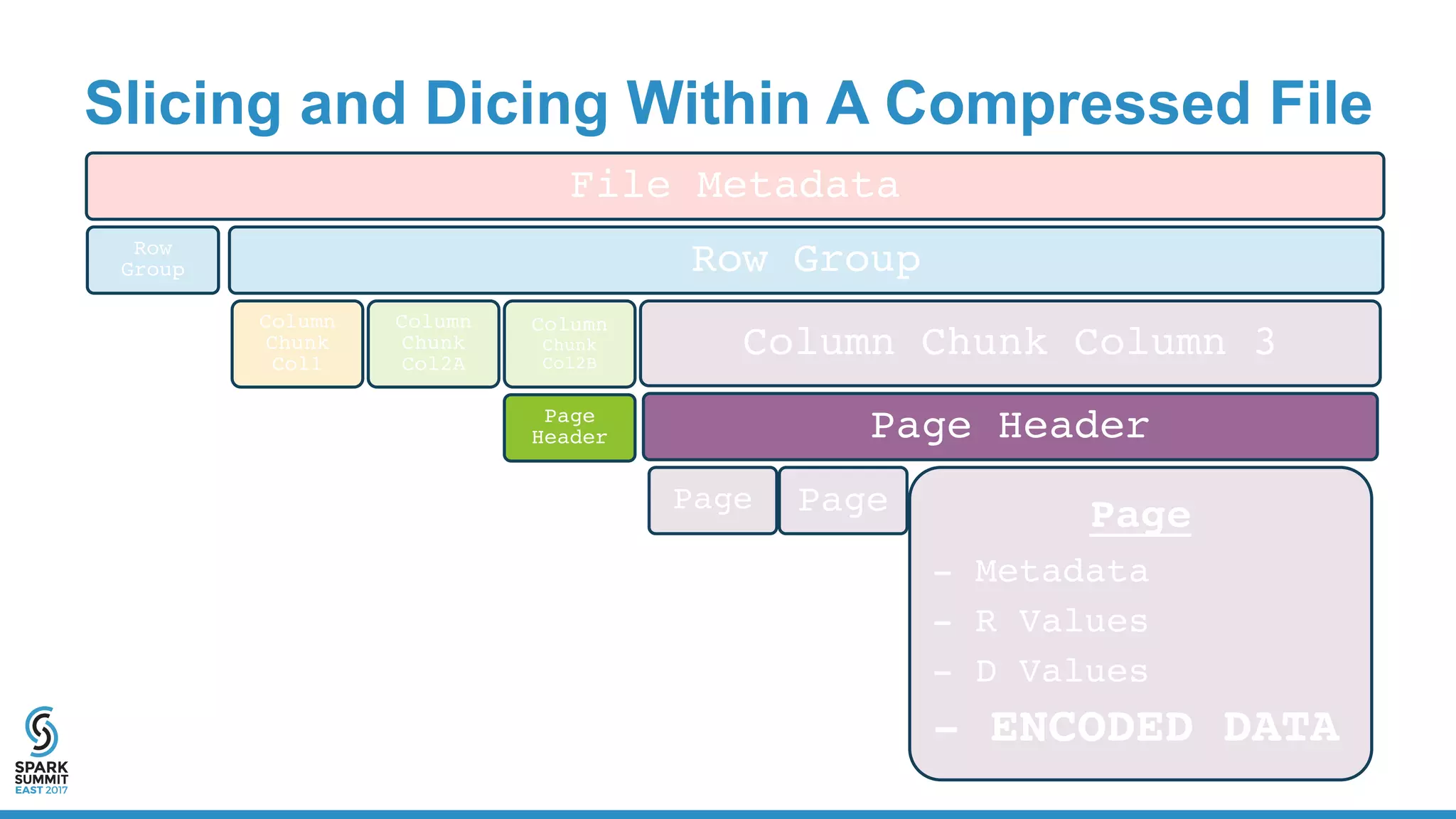
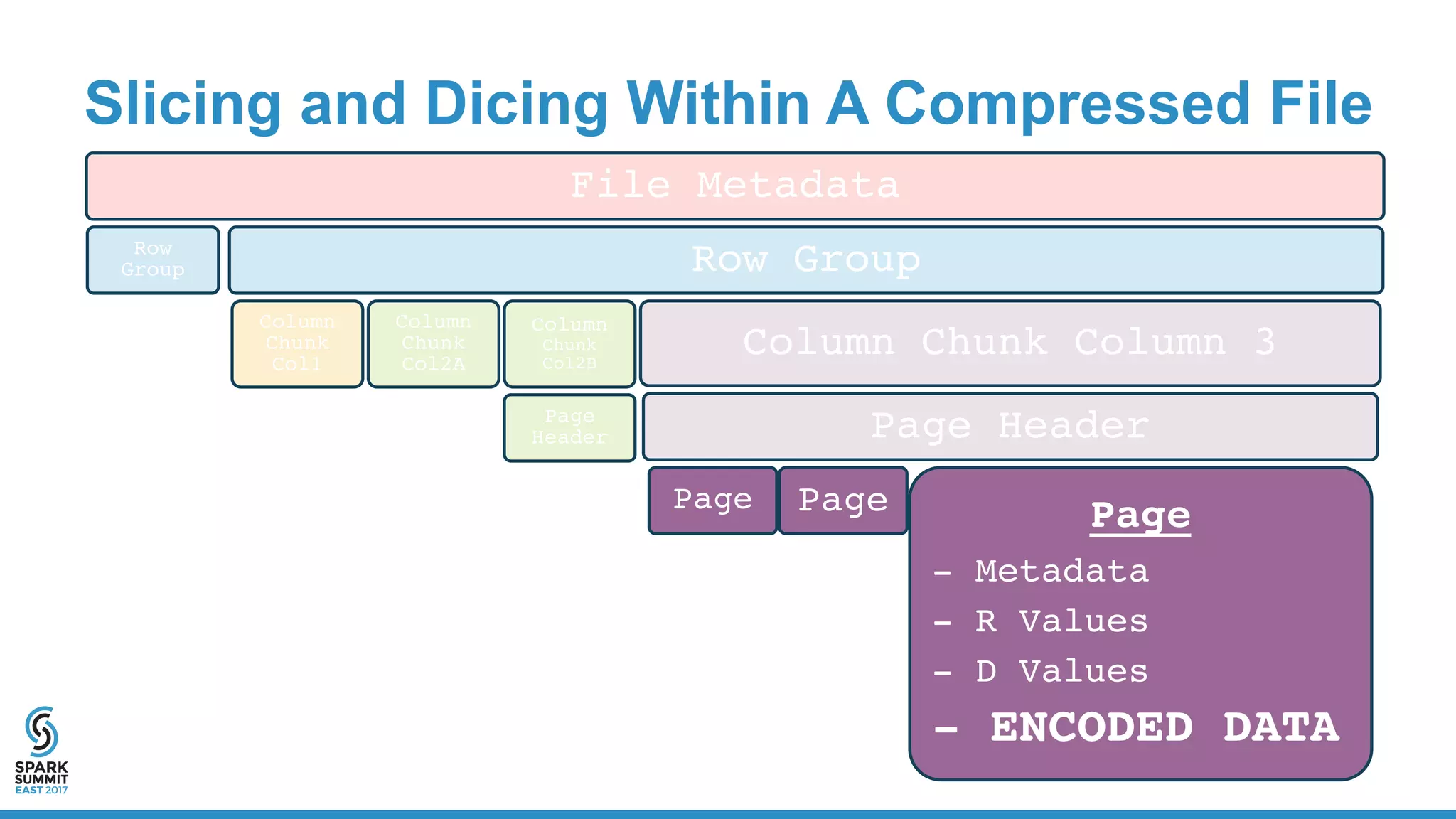




![Physical Plan for Reading CSV
[ Scan
CsvRelation(hdfs://rhel10.cisco.com/user/spark/hadoopds1000g/date_dim/*,false,|,",null,PERMISS
IVE,COMMONS,false,false,StructType(StructField(d_date_sk,IntegerType,false),
StructField(d_date_id,StringType,false), StructField(d_date,StringType,true),
StructField(d_month_seq,LongType,true), StructField(d_week_seq,LongType,true),
StructField(d_quarter_seq,LongType,true), StructField(d_year,LongType,true),
StructField(d_dow,LongType,true), StructField(d_moy,LongType,true),
StructField(d_dom,LongType,true), StructField(d_qoy,LongType,true),
StructField(d_fy_year,LongType,true), StructField(d_fy_quarter_seq,LongType,true),
StructField(d_fy_week_seq,LongType,true), StructField(d_day_name,StringType,true),
StructField(d_quarter_name,StringType,true), StructField(d_holiday,StringType,true),
StructField(d_weekend,StringType,true), StructField(d_following_holiday,StringType,true),
StructField(d_first_dom,LongType,true), StructField(d_last_dom,LongType,true),
StructField(d_same_day_ly,LongType,true), StructField(d_same_day_lq,LongType,true),
StructField(d_current_day,StringType,true), StructField(d_current_week,StringType,true),
StructField(d_current_month,StringType,true), StructField(d_current_quarter,StringType,true),
StructField(d_current_year,StringType,true)))[d_date_sk#141,d_date_id#142,d_date#143,d_month_s
eq#144L,d_week_seq#145L,d_quarter_seq#146L,d_year#147L,d_dow#148L,d_moy#149L,d_dom#150L,d_qoy#
151L,d_fy_year#152L,d_fy_quarter_seq#153L,d_fy_week_seq#154L,d_day_name#155,d_quarter_name#156
,d_holiday#157,d_weekend#158,d_following_holiday#159,d_first_dom#160L,d_last_dom#161L,d_same_d
ay_ly#162L,d_same_day_lq#163L,d_current_day#164,d_current_week#165,d_current_month#166,d_curre
nt_quarter#167,d_current_year#168]]
Example From: https://developer.ibm.com/hadoop/2016/01/14/5-reasons-to-choose-parquet-for-spark-sql/](https://image.slidesharecdn.com/6bcurtinstrickland-170215222253/75/Spark-Parquet-In-Depth-Spark-Summit-East-Talk-by-Emily-Curtin-and-Robbie-Strickland-56-2048.jpg)
![Physical Plan For Reading Parquet
+- Scan ParquetRelation[d_date_sk#141,d_month_seq#144L] InputPaths:
hdfs://rhel10.cisco.com/user/spark/hadoopds1tbparquet/date_dim/_SUCCESS,
hdfs://rhel10.cisco.com/user/spark/hadoopds1tbparquet/date_dim/_common_metadata
, hdfs://rhel10.cisco.com/user/spark/hadoopds1tbparquet/date_dim/_metadata,
hdfs://rhel10.cisco.com/user/spark/hadoopds1tbparquet/date_dim/part-r-00000-
4d205b7e-b21d-4e8b-81ac-d2a1f3dd3246.gz.parquet,
hdfs://rhel10.cisco.com/user/spark/hadoopds1tbparquet/date_dim/part-r-00001-
4d205b7e-b21d-4e8b-81ac-d2a1f3dd3246.gz.parquet, PushedFilters:
[GreaterThanOrEqual(d_month_seq,1200),
LessThanOrEqual(d_month_seq,1211)]]
Example From: https://developer.ibm.com/hadoop/2016/01/14/5-reasons-to-choose-parquet-for-spark-sql/](https://image.slidesharecdn.com/6bcurtinstrickland-170215222253/75/Spark-Parquet-In-Depth-Spark-Summit-East-Talk-by-Emily-Curtin-and-Robbie-Strickland-57-2048.jpg)













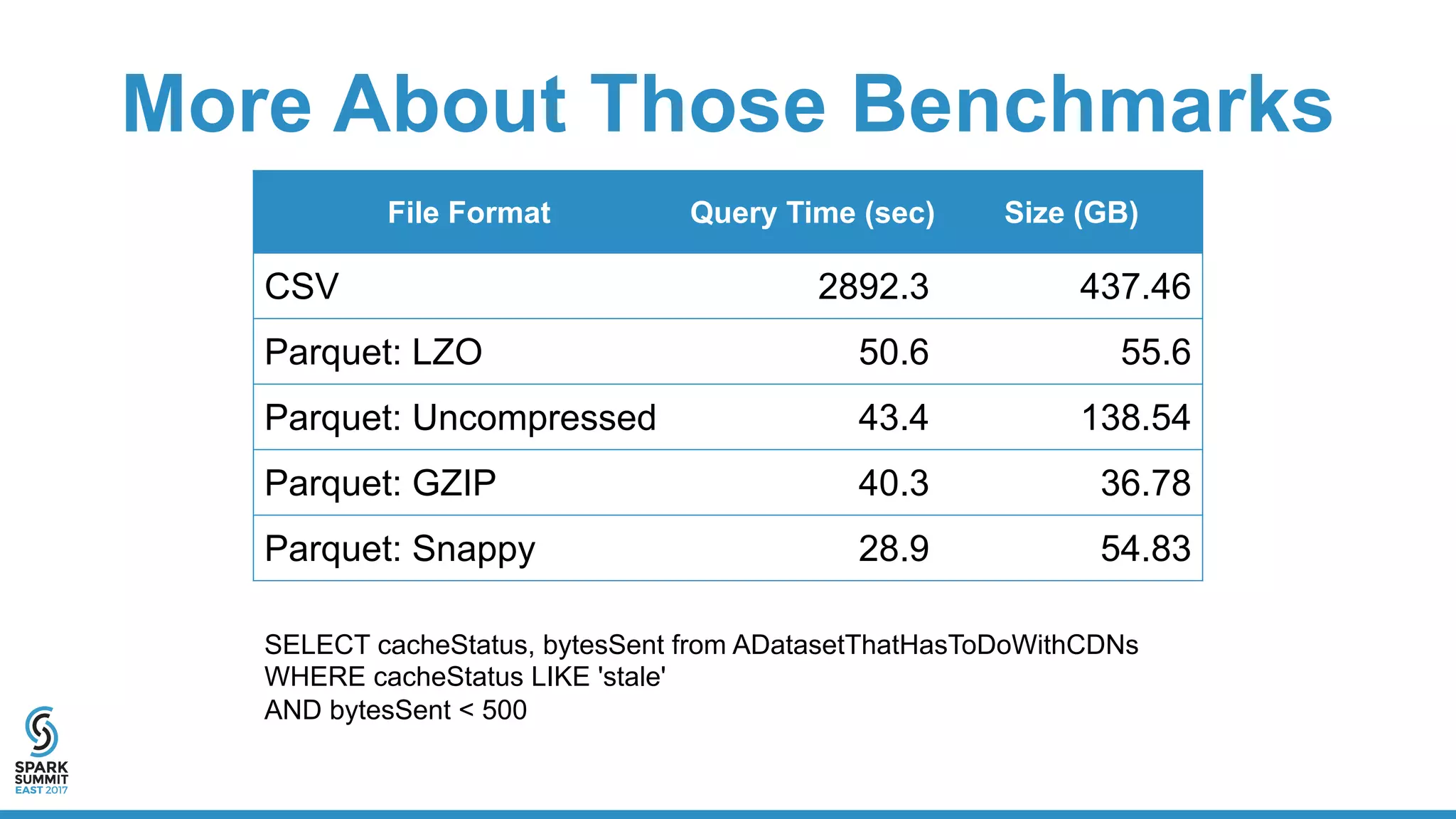






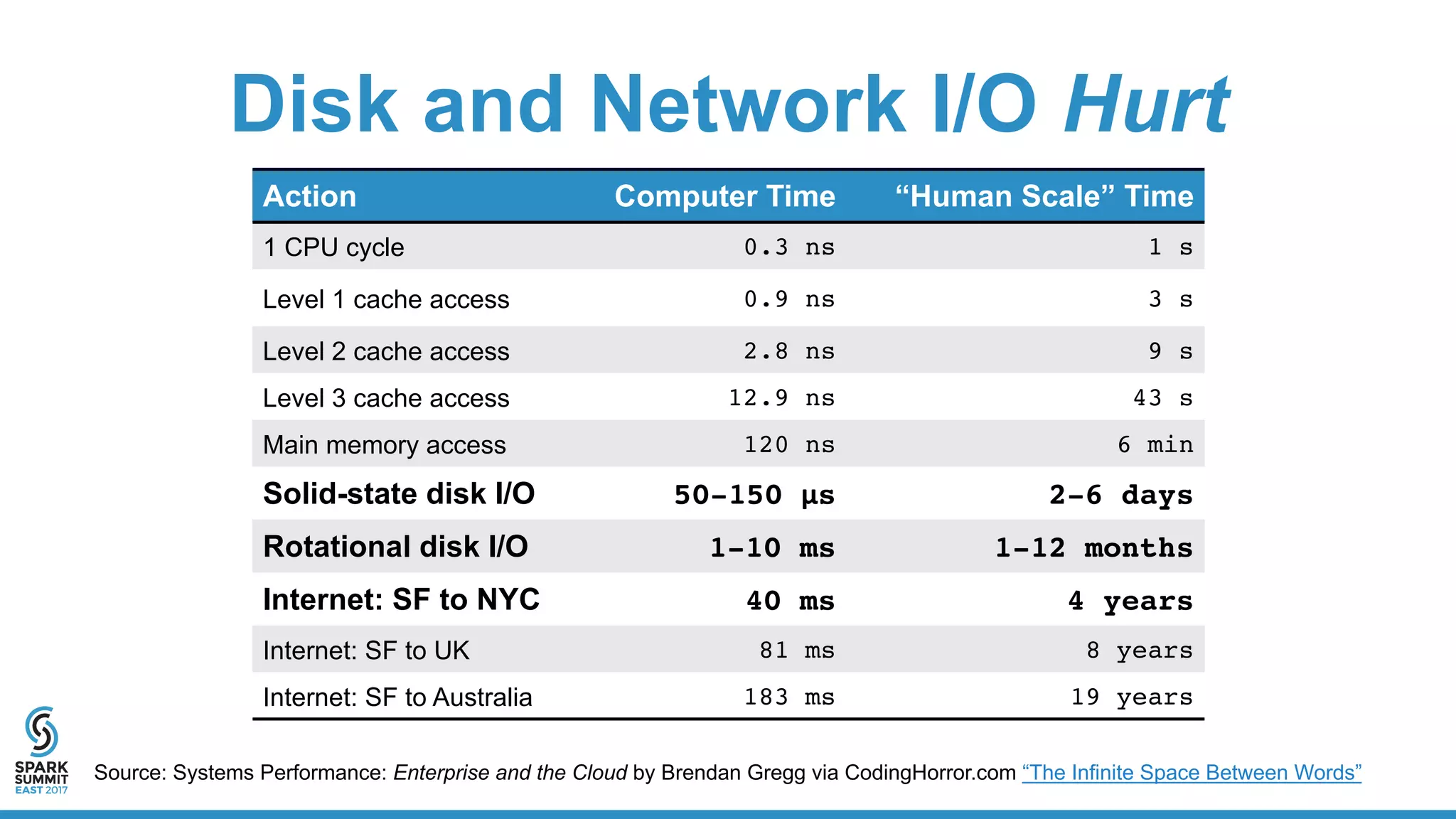
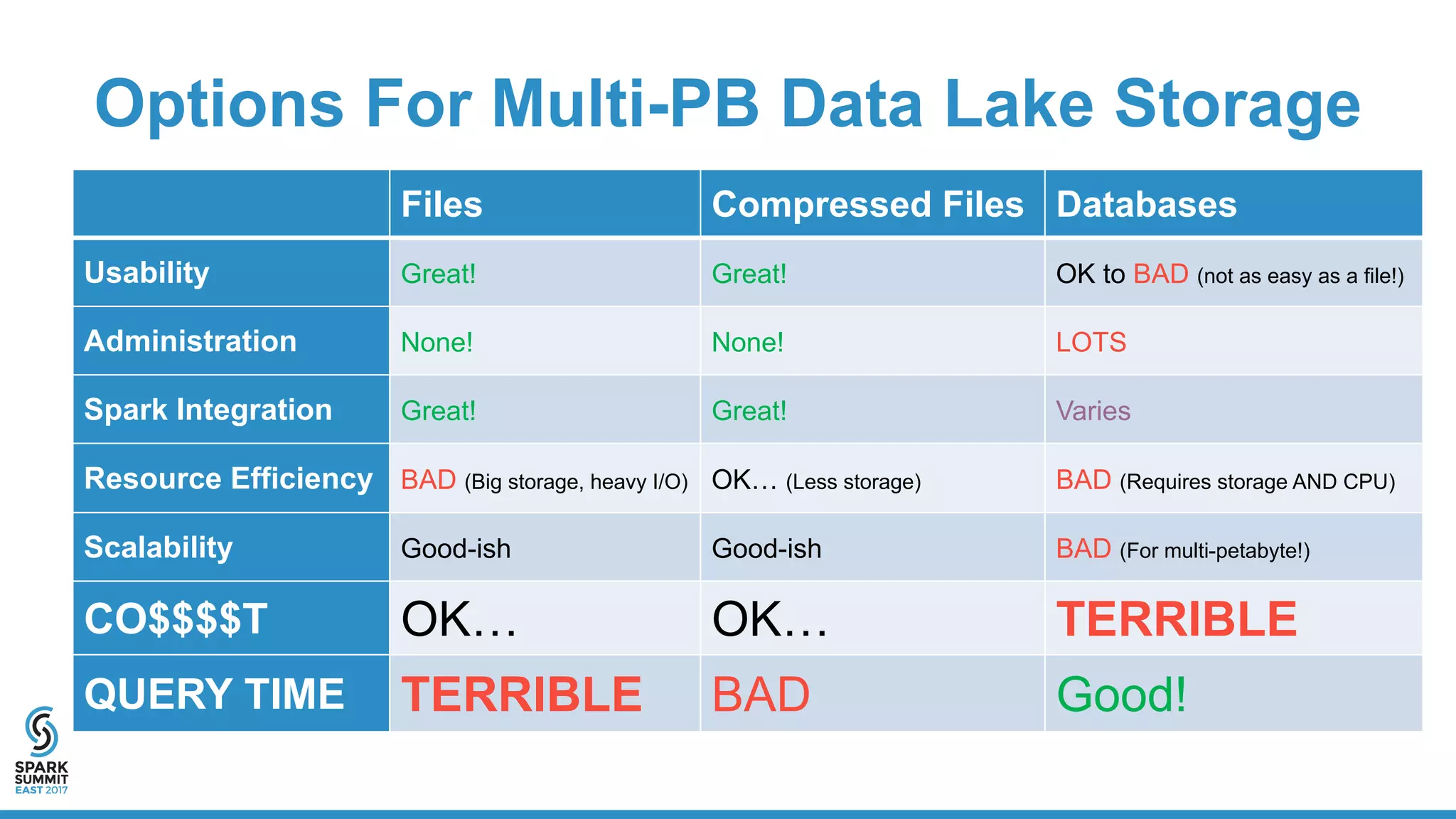
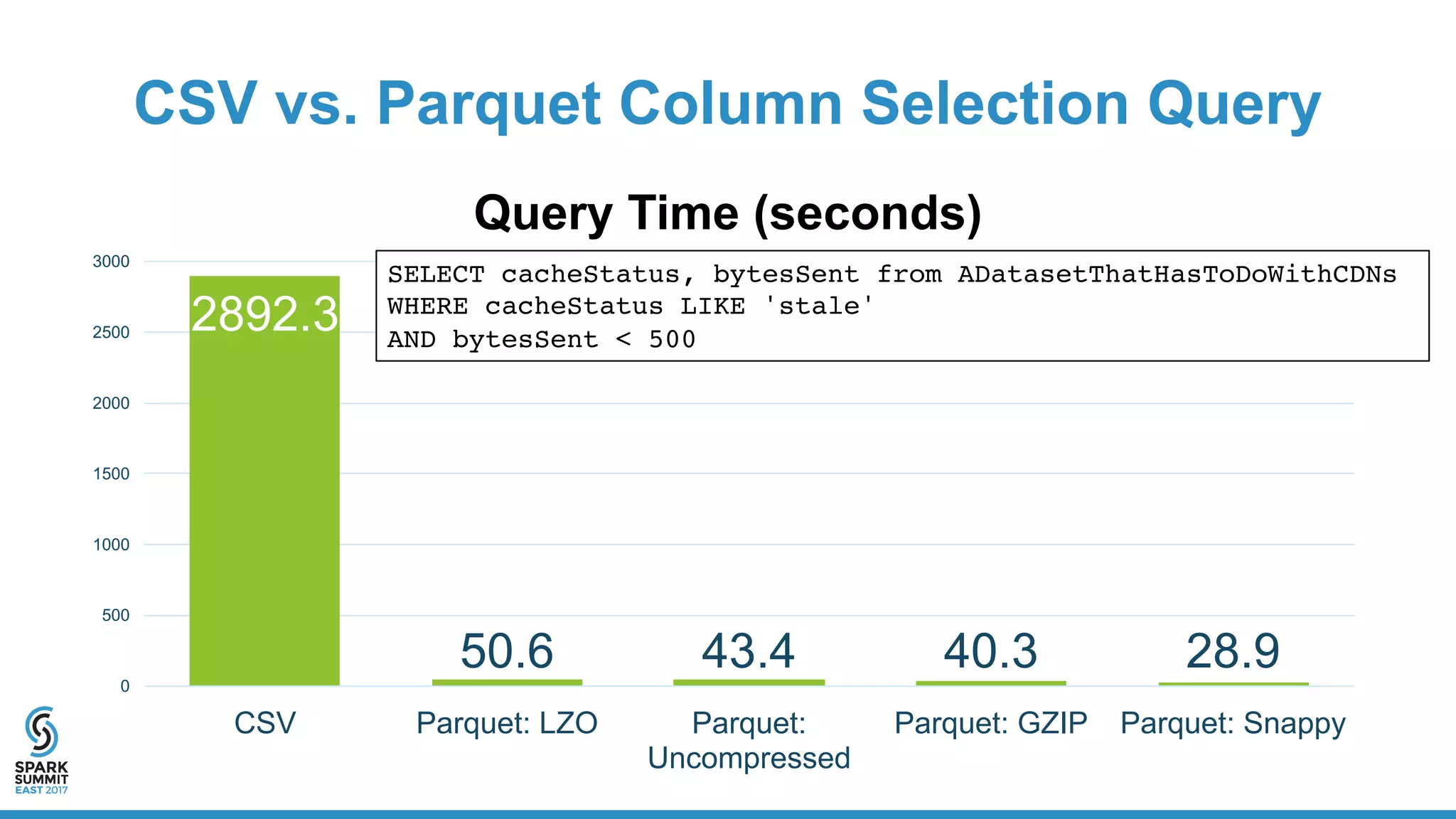
The document discusses the benefits and workings of using Apache Parquet with Spark for efficient data storage and processing in data lakes. Key topics include usability, resource efficiency, cost factors, and performance metrics of Parquet versus CSV formats, showcasing examples of data structures and query performance. It also provides code snippets for writing and querying Parquet files using Spark, highlighting the advantages of columnar storage in managing large datasets.





























































































![[DSC Europe 25] Andy Cotgreave - Nothing is new in analytics.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/mba4vzcurvoh5lfrd5zw-6-251205194645-341bbbbe-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dragana Ilic - AI for Big Data in Astronomy.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/8palya86qaatvjhva1ms-2-dragana-ilic-ai-ilic-251208151906-652b819c-thumbnail.jpg?width=640&height=640&fit=bounds)








![[DSC Europe 25] Max Talanov - Non digital NNs.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/wif8tr3gtua74qvtopke-non-digital-nns-251205090438-26b0eea6-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Vid Stimac - Policy Parsimony: Between Oversimplifying and Ov...](https://cdn.slidesharecdn.com/ss_thumbnails/eqlepagzqp2rhg3gbluh-dsc-stimac-251120-251205090438-059e7f54-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Dragan Vucic - Building the Learning Organization - How AI Tr...](https://cdn.slidesharecdn.com/ss_thumbnails/8brigo2sbu6qur6gxrra-7-251205085715-6ae07d24-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Bogdan Daniel Maruneac - AI - It starts with you.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/odov3snhrcqs9hx5ny2n-4-251205085715-f1daacfe-thumbnail.jpg?width=640&height=640&fit=bounds)