Download as PDF, PPTX
















































![...
def test_format
# test format using emit and expect_format
end
def test_write
d = create_driver
t = emit_documents(d)
# return a result of write method
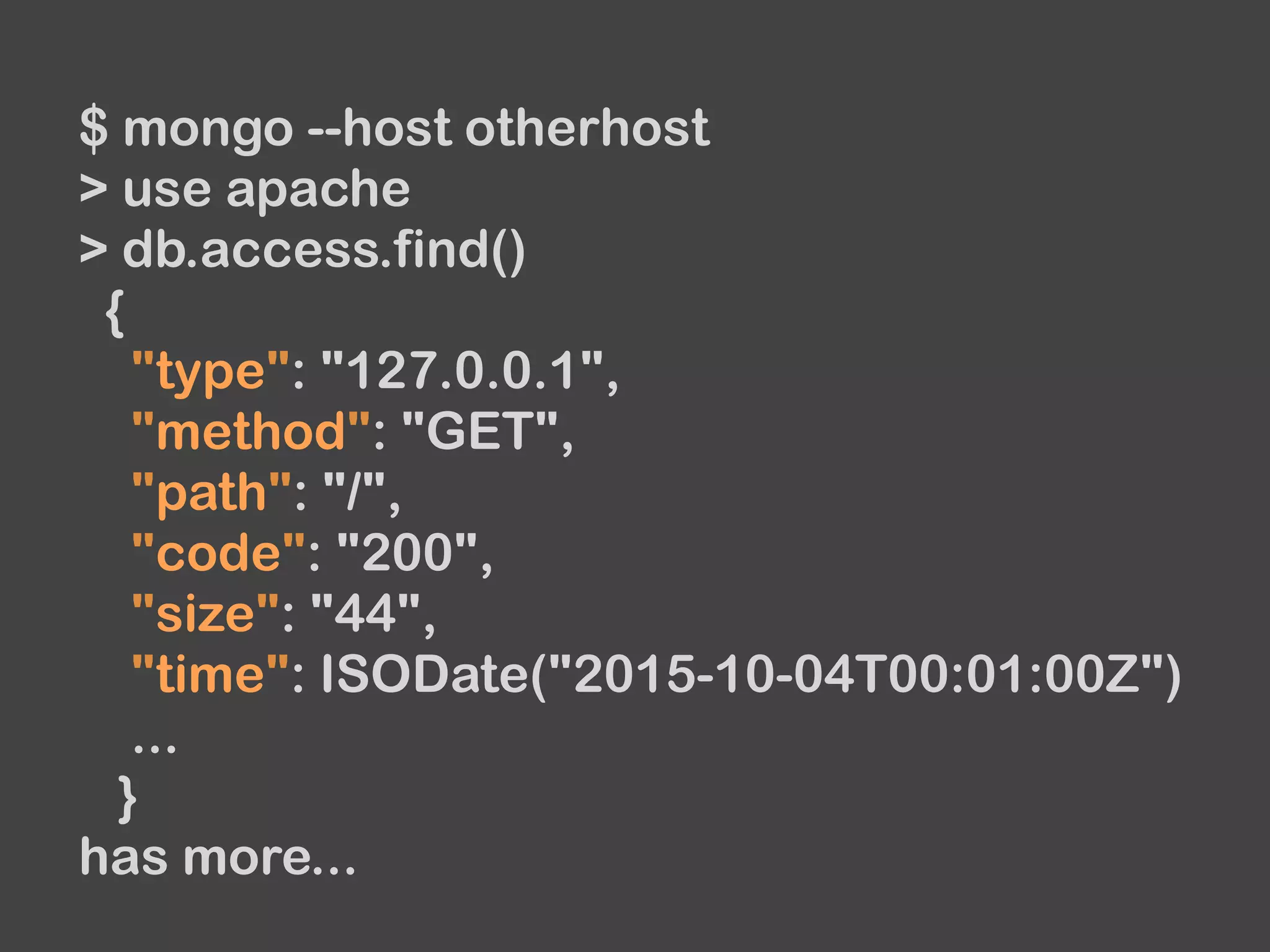
collection_name, documents = d.run
assert_equal([{...}, {...}, ...], documents)
assert_equal('test', collection_name)
end
...
end](https://image.slidesharecdn.com/diveintofluentdpluginv0-151005105435-lva1-app6891/75/Dive-into-Fluentd-plugin-v0-12-68-2048.jpg)





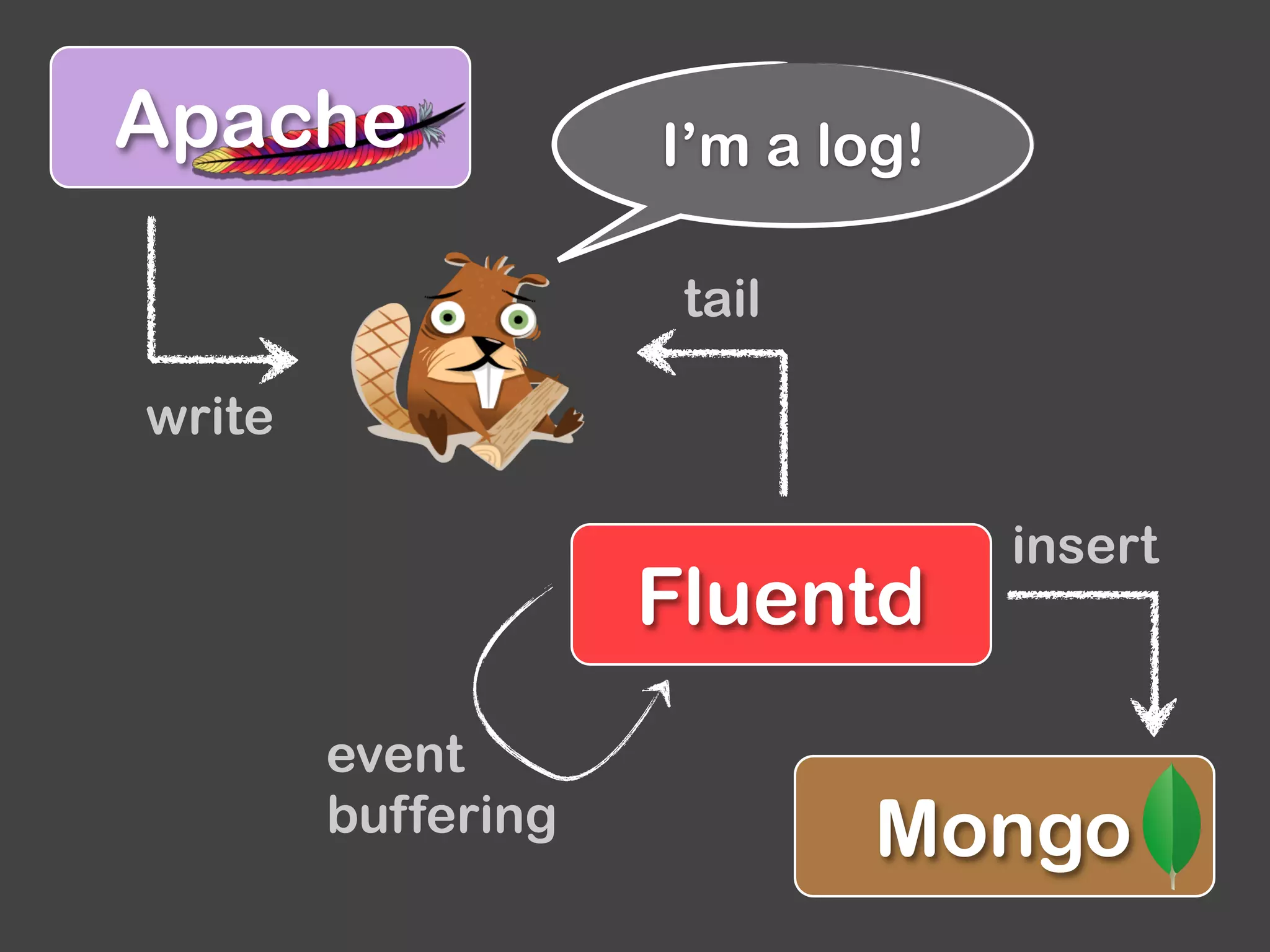
The document provides an overview of Fluentd and its plugin architecture, detailing input, filter, output, and buffer mechanisms. It includes examples of configuring Fluentd with plugins, particularly fluent-plugin-mongo, and discusses visualization tools, testing methods, and third-party plugins. The guide highlights the use of Ruby for development, the importance of message serialization, and best practices for plugin integration and data handling.












































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)














