Download as PDF, PPTX









![Markov Decision Process (MDP)
Definizione:
S: Insieme di stati
A: Insieme di azioni
Pr(st|st-1,at): probabilità di transitare nello
stato st trovandoci nello stato st-1 e effettuando
azione at
rt : Funzione di Reward
Discount factor μ ∈ [0,1]
○ Controlla l’importanza di rewards futuri , o =
reward immediati, 1 = tutti i reward egualmente
Ambienti deterministici vs ambienti
stocastici
Meglio 100 euro adesso o 1000 euro in 1000 anni?](https://image.slidesharecdn.com/deepreinforcementlearning-dentamaro-180923143958/85/Deep-Reinforcement-Learning-11-320.jpg)







![Q Learning
Model free
● Qualità dell’azione che si è deciso di intraprendere trovandosi in un determinato stato
● Bellman equation →
Q'[s, a] = (1 - α) · Q[s, a] + α · (r + γ · Q[s', argmax_a'(Q[s', a'])])
α = learning rate per variare il peso delle nuove esperienze rispetto i valori passati
r = è il reward immediato per aver intrapreso l’azione a trovandosi nello stato s
γ = è il fattore di sconto (discount factor) usato per scontare progressivamente i valori futuri.
s’ = è lo stato in cui finiamo
argmax_a’(Q[s’,a’]) = è l’azione risultante, che massimizza la Q-Value rispetto a tutte le possibili
azioni a’ nello stato s’.](https://image.slidesharecdn.com/deepreinforcementlearning-dentamaro-180923143958/85/Deep-Reinforcement-Learning-19-320.jpg)

![alpha = 0.5
gamma = 0.9
episodes = 10000
epsilon = 0.5
epsilon_decay = 0.99
best_q = None
previous_reward = -10000
# Episodes
for episode in range(episodes):
# Refresh state
state = env.reset()
done = False
t_reward = 0
# Run episode
for i in range(episodes):
if done:
break
current = state
rnd = np.random.uniform(0,1)
action = np.argmax(Q[current])
#choose a greedy action with 1-epsilon
if epsilon >= rnd:
#random action
action = np.random.randint(0, env.action_space.n)
epsilon = epsilon * epsilon_decay
else:
state_action = Q[current]
action = np.argmax(state_action)
if exploration == 'greedy':
if np.random.uniform() < epsilon:
action = np.random.random_integers(0, env.action_space.n - 1)
action = np.argmax(Q[current, :] + np.random.randn(1, env.action_space.n) * (1 / float(episode + 1)))
state, reward, done, info = env.step(action)
t_reward += reward
Q[current, action] += alpha * (reward + gamma * np.max(Q[state, :]) - Q[current, action])
rewards.append(t_reward)
if(t_reward > previous_reward):
previous_reward = t_reward
iterations.append(i)
Q-LEARNING
R. Sutton dice che Q learning converge se ogni stato è visitato indefinitamente
spesso.](https://image.slidesharecdn.com/deepreinforcementlearning-dentamaro-180923143958/85/Deep-Reinforcement-Learning-21-320.jpg)
![env = gym.make("Taxi-v2")
# Q-function
Q = defaultdict(lambda : 0.) # Q-function
n = defaultdict(lambda : 1.) # number of visits
actionspace = range(env.action_space.n)
greedy_action = lambda s : max(actionspace, key=lambda a : Q[(s,a)])
max_q = lambda sp : max([Q[(sp,a)] for a in actionspace])
import random
epsilon = 0.1
gamma = 0.9
max_episodes = 30000
max_steps = 1000
# Simulation
episodescores = []
for _ in range(max_episodes):
nextstate = env.reset()
currentscore = 0.
for _ in range(max_steps):
state = nextstate
# Epsilon-Greedy
if epsilon > random.random() :
action = env.action_space.sample()
else :
action = greedy_action(state)
nextstate, reward, done, info = env.step(action)
currentscore += reward
# Q-learning
if done :
Q[(state,action)] = Q[(state,action)] + 1./n[(state,action)] * ( reward - Q[(state,action)] )
break
else :
Q[(state,action)] = Q[(state,action)] + 1./n[(state,action)] *
( reward + gamma * max_q(nextstate) - Q[(state,action)] )
Q-LEARNING
LA VERSIONE TABULARE VA BENE SEMPRE?](https://image.slidesharecdn.com/deepreinforcementlearning-dentamaro-180923143958/85/Deep-Reinforcement-Learning-22-320.jpg)


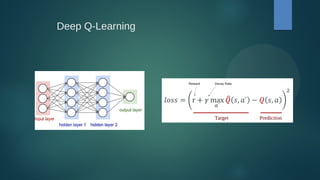





![Bibliografia
[1] SUTTON, Richard S., et al. Reinforcement learning: An introduction. MIT press,
1998. Anche versione 2 Draft https://goo.gl/3Hz88y
[2] N. Nikovski, Daniel, 1999/02/20, Fast Reinforcement Learning in Continuous
Action Spaces
[3]Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Alex Graves, Ioannis
Antonoglou, Daan Wierstra, and Martin A. Riedmiller. Playing atari with deep
reinforcement learning. CoRR, abs/1312.5602, 2013.
[4] VAN HASSELT, Hado; GUEZ, Arthur; SILVER, David. Deep Reinforcement
Learning with Double Q-Learning. In: AAAI. 2016. p. 2094-2100.
[5]Matiisen Tambet, Demystifying Deep Reinforcement Learning, December 22
2015, Intel AI.
CONTATTI
Vincenzo Dentamaro
Email vincenzodentamaro@gmail.com o
v.dentamaro@nextome.net oppure
vincenzo@gatech.edu
Linkedin
https://www.linkedin.com/in/vincenzodentamaro/](https://image.slidesharecdn.com/deepreinforcementlearning-dentamaro-180923143958/85/Deep-Reinforcement-Learning-34-320.jpg)

Il documento illustra i concetti di apprendimento supervisionato, non supervisionato e per rinforzo, con focus sull'apprendimento per rinforzo e il processo decisionale di Markov. Vengono descritti vari algoritmi, come il Q-learning e le tecniche di policy iteration, nonché l'importanza dell'esplorazione e sfruttamento. Infine, si accenna all'uso del deep reinforcement learning in diversi campi, tra cui robotica e medicina.










































