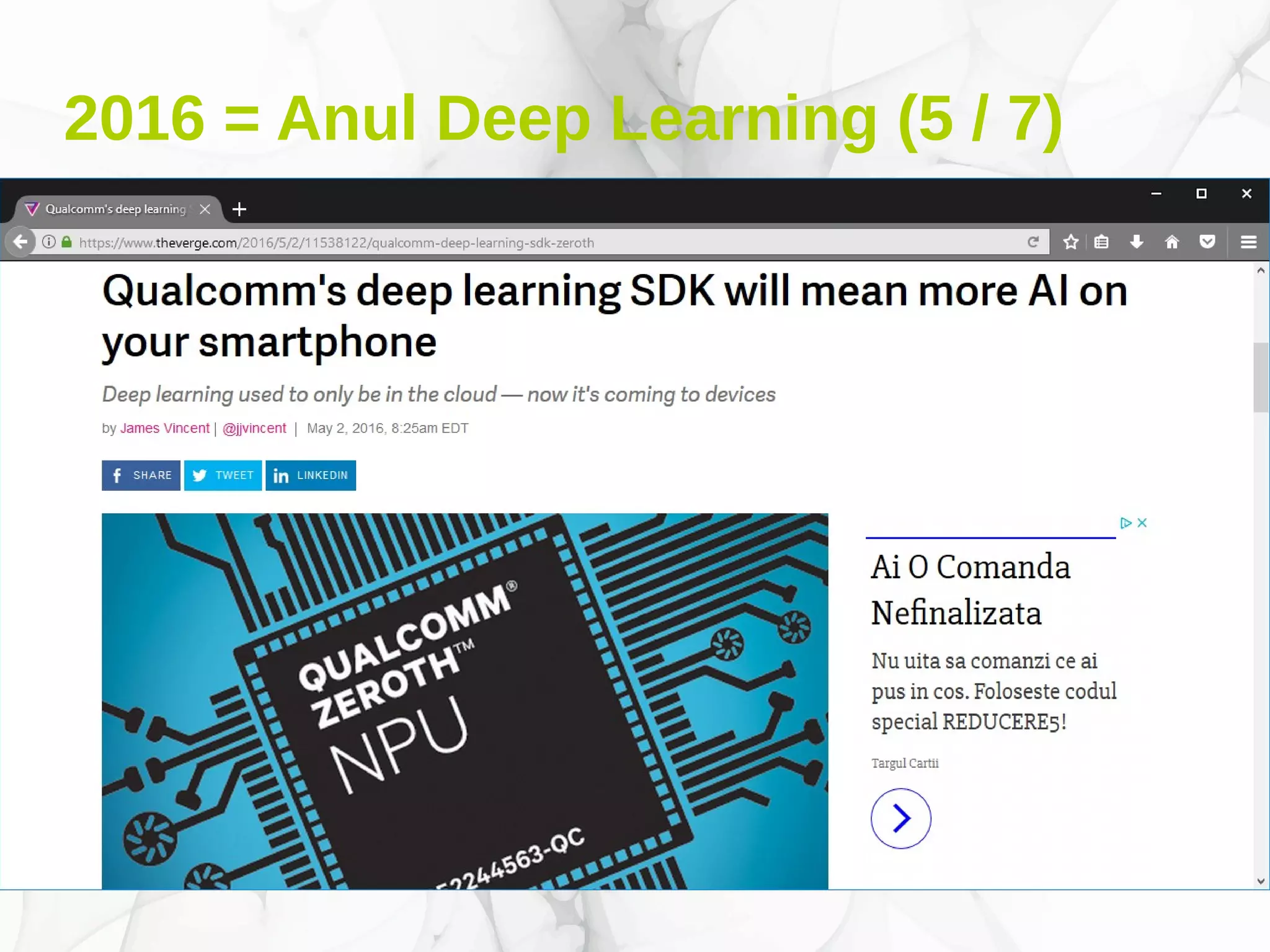
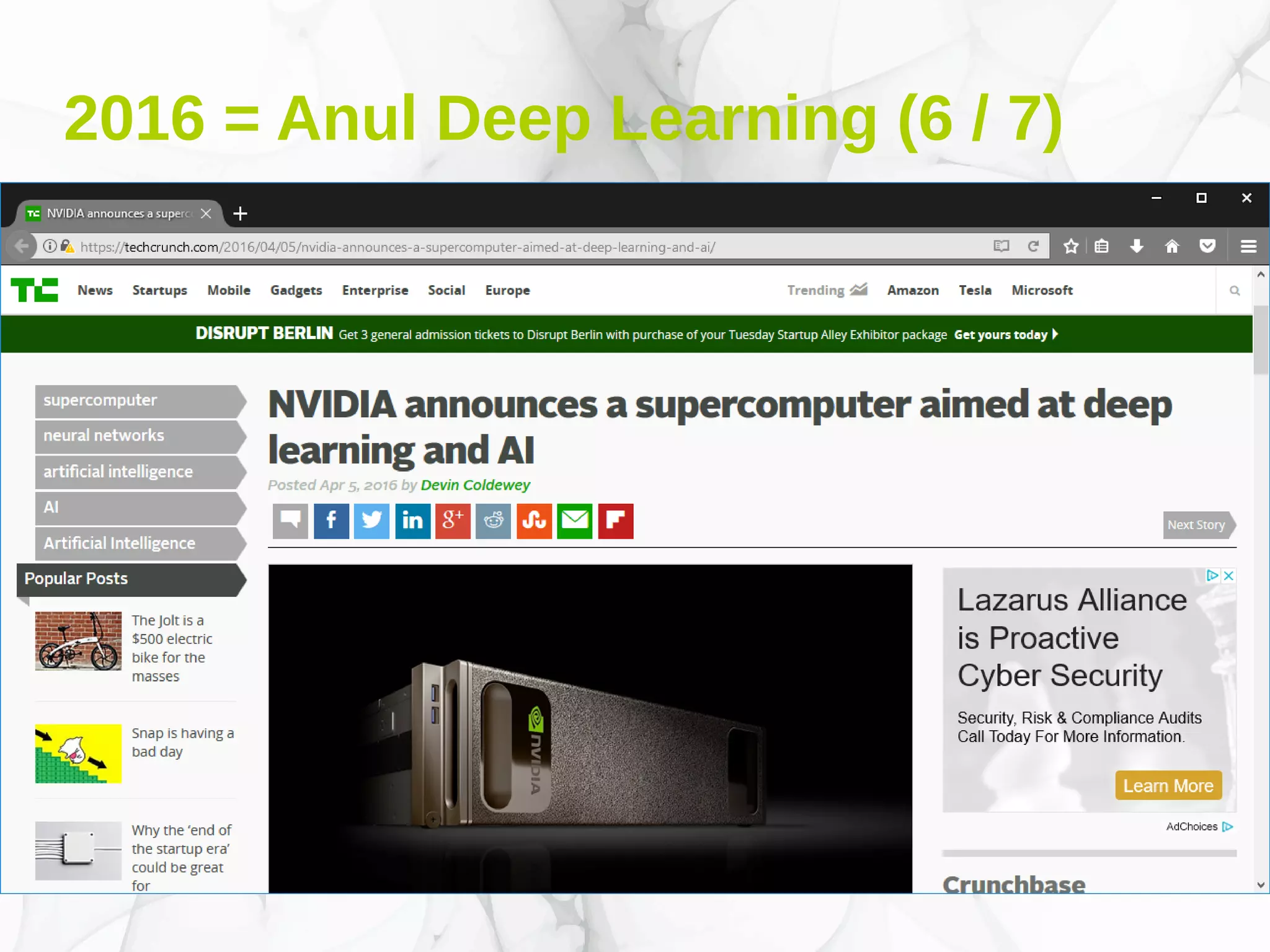
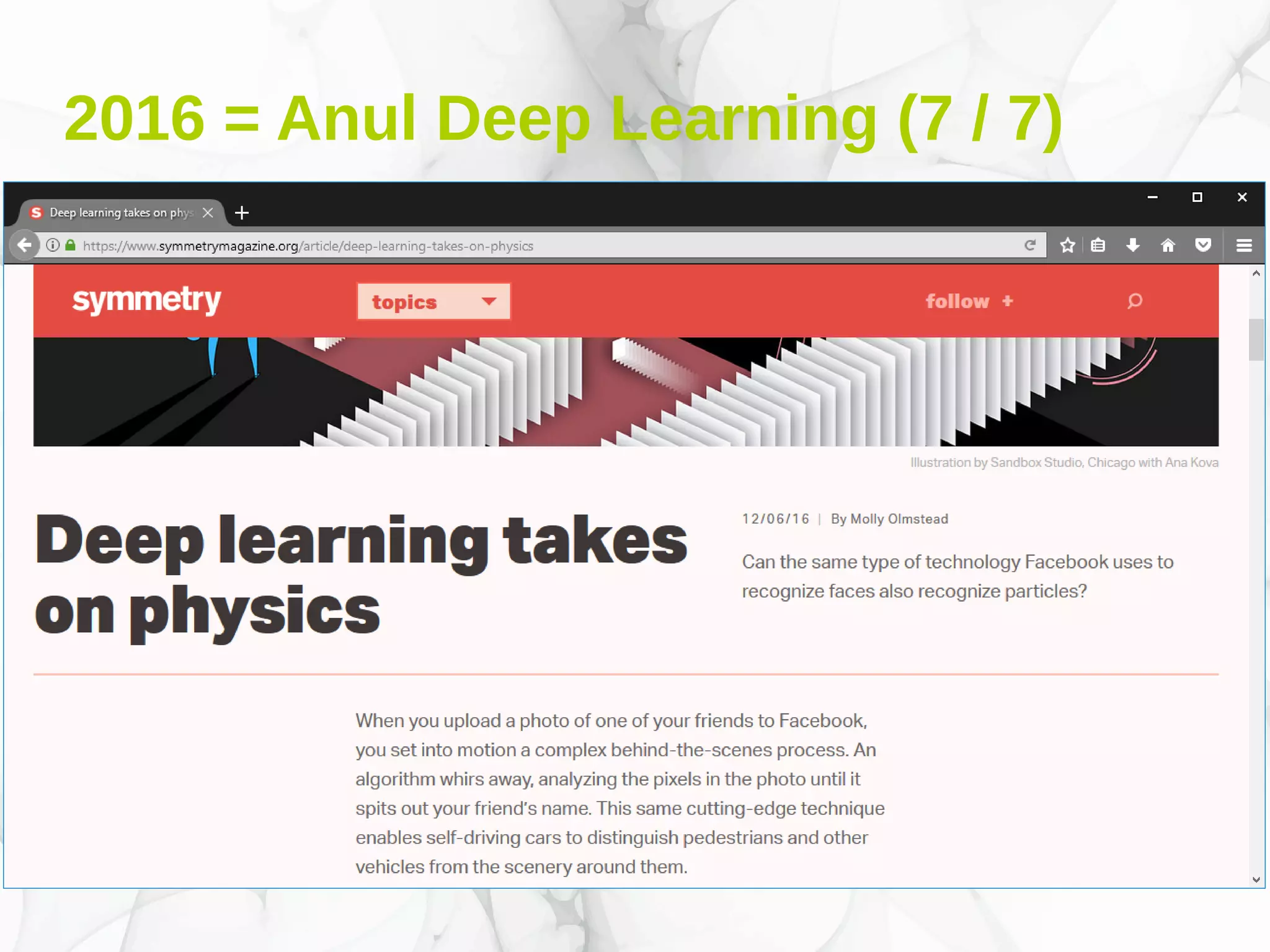
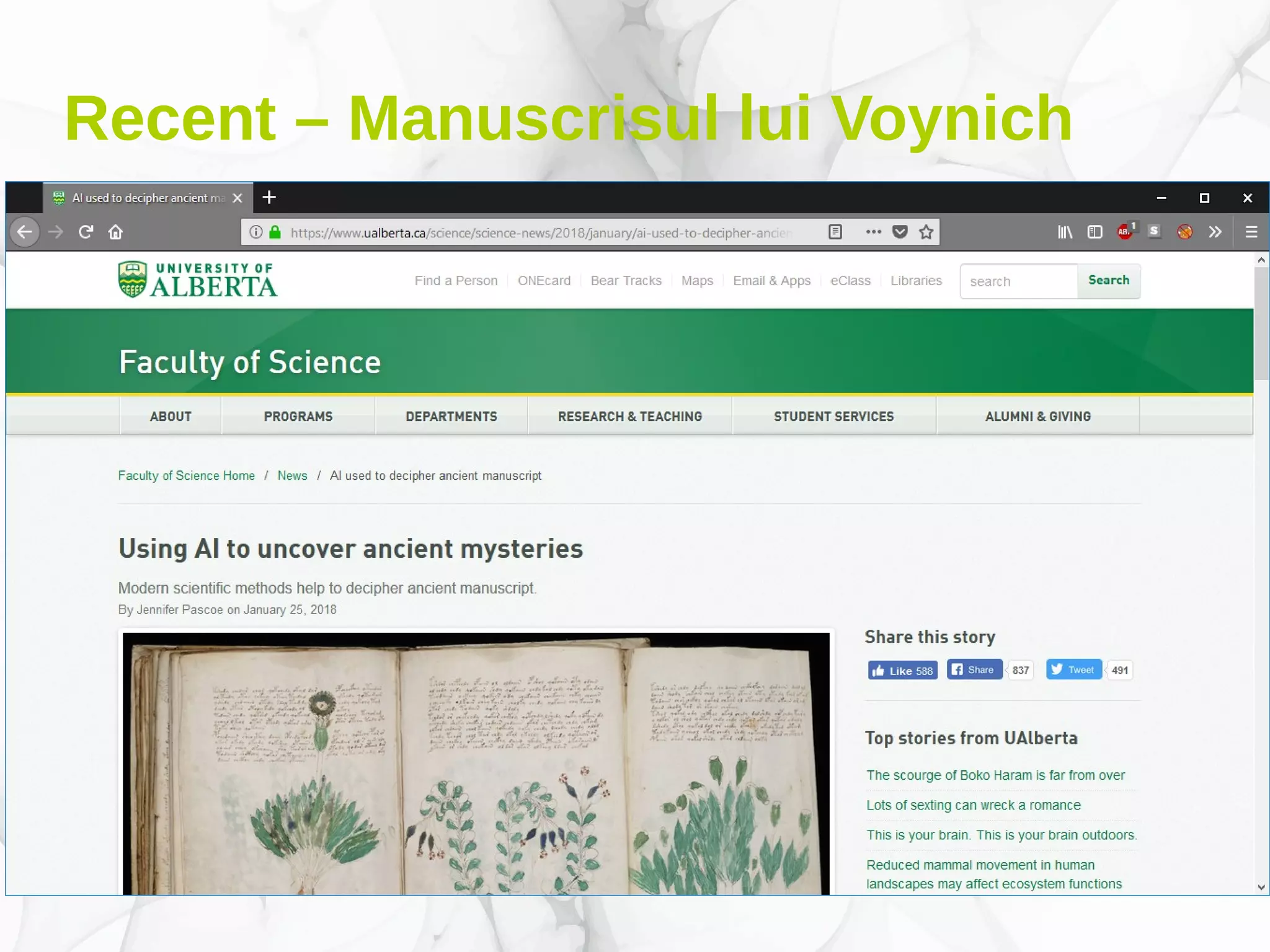
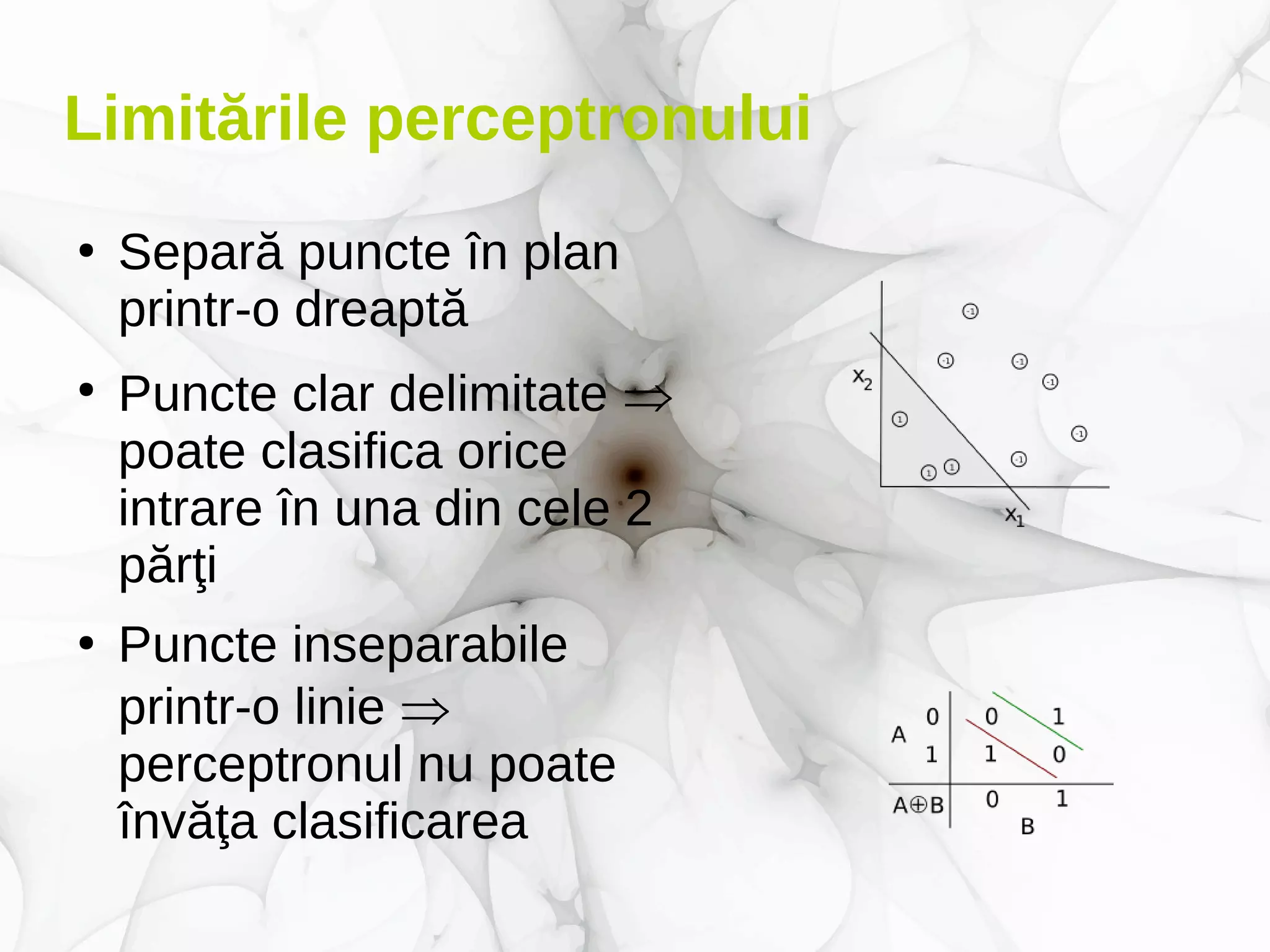
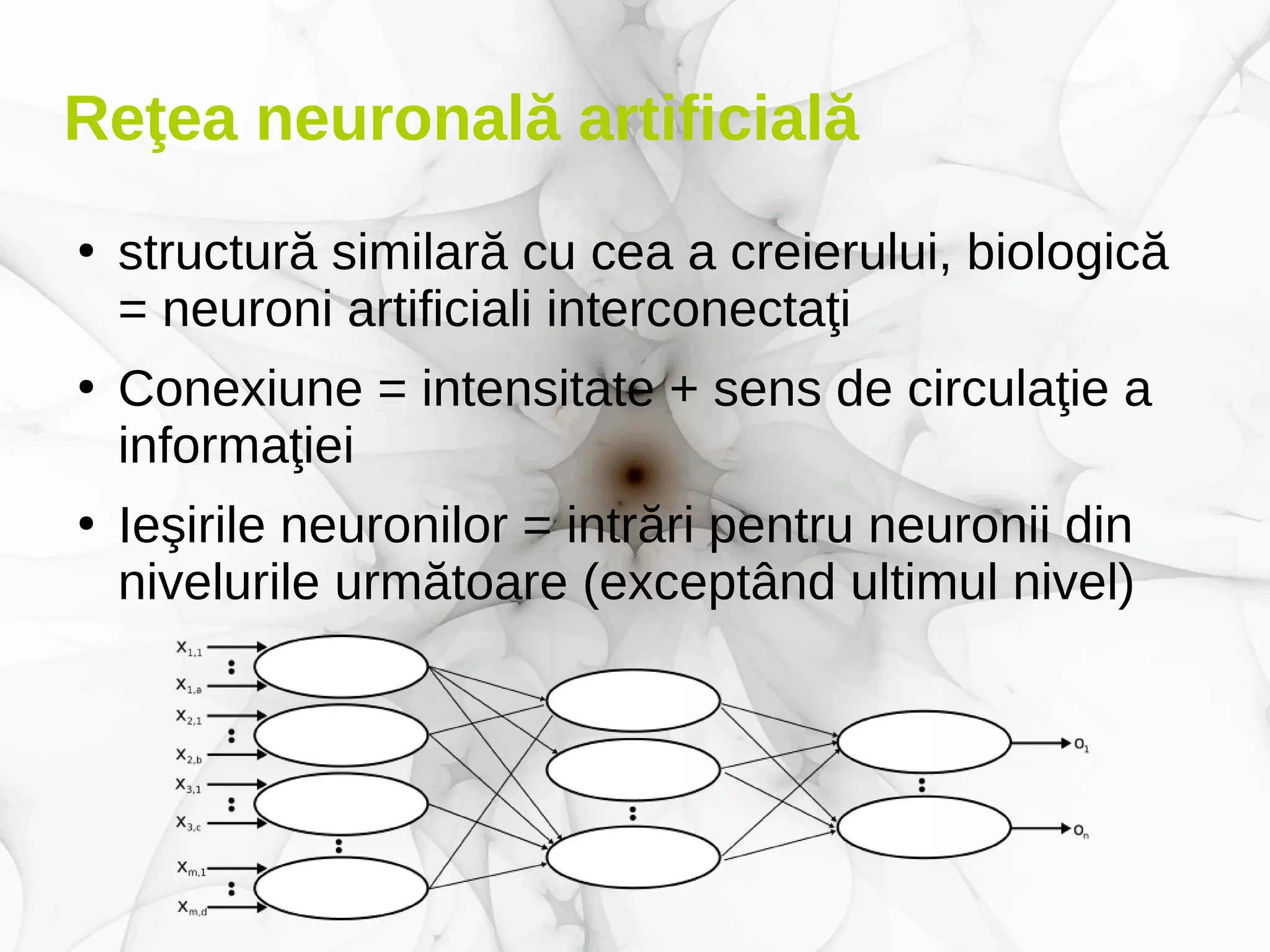
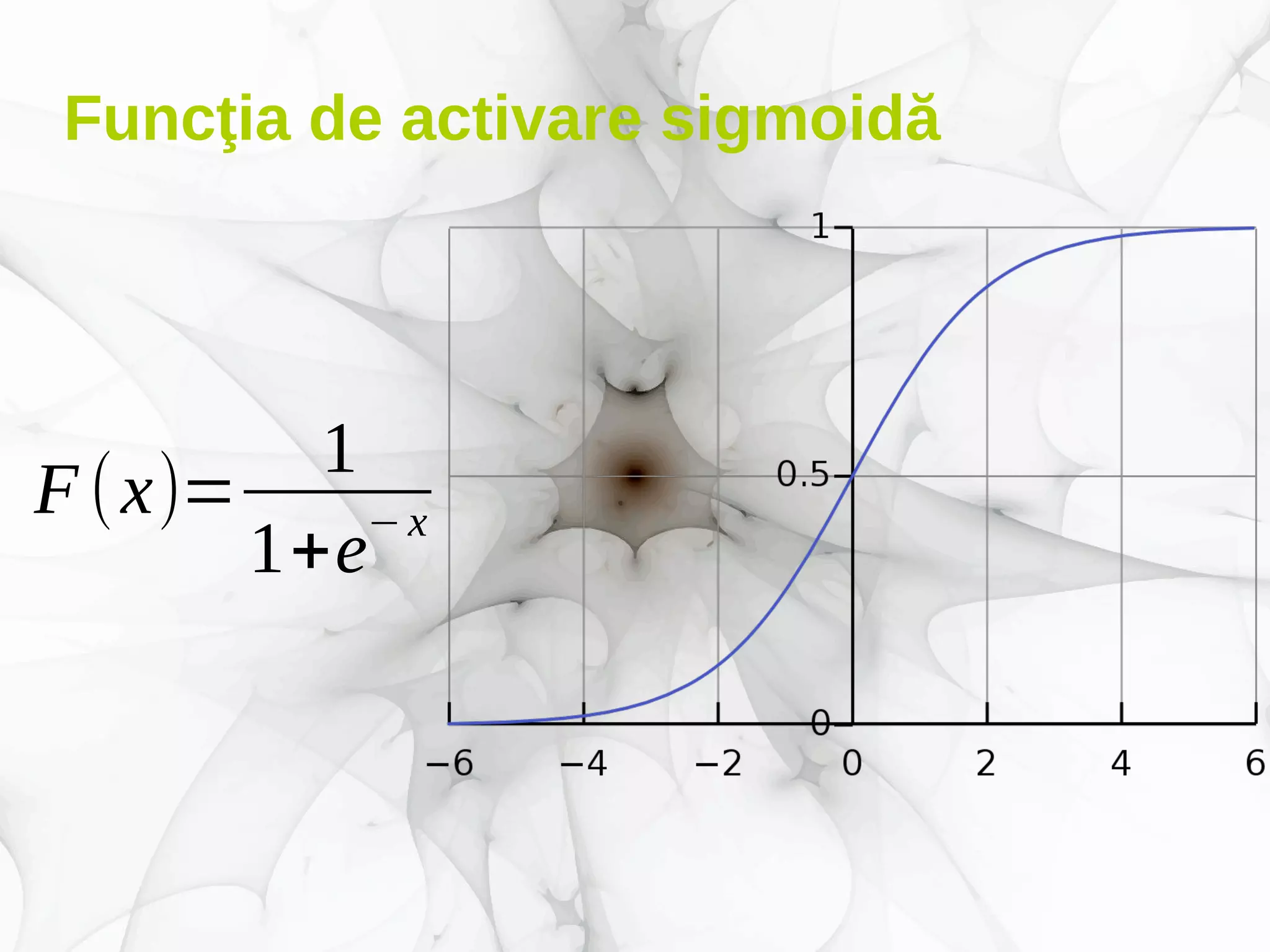
Documentul prezintă conceptele fundamentale și aplicațiile deep learning-ului, incluzând rețele neuronale, algoritmi de învățare, și tehnici de optimizare precum coborârea pe gradient. De asemenea, se discută despre rețele neuronale convoluționale și importanța volumului mare de date în antrenarea acestor modele. Este evidențiat rolul deep learning-ului în progresele recente din inteligența artificială și utilizarea sa în diverse domenii precum robotică și computer vision.







![Perceptronul liniar
●
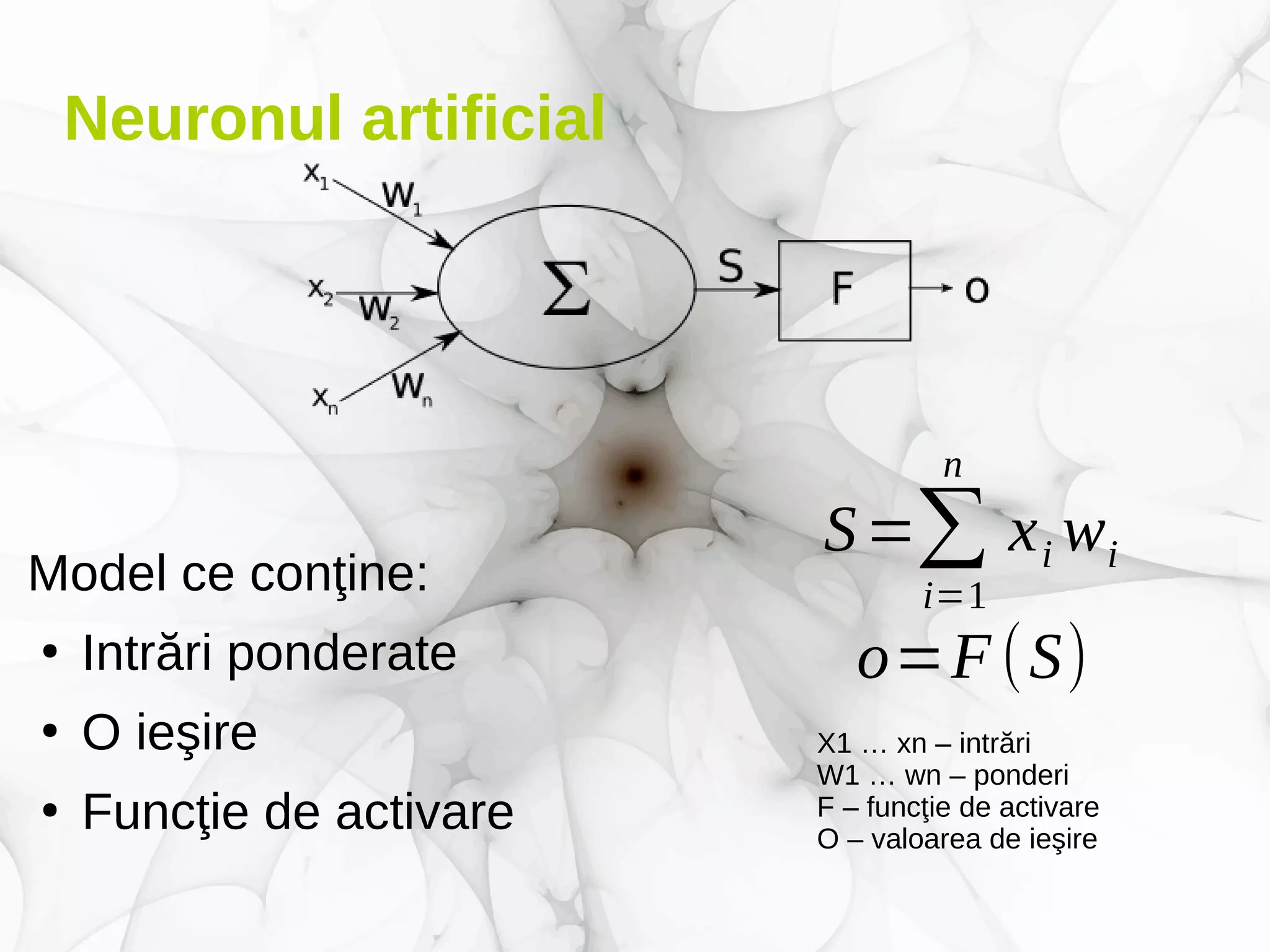
Modelul: o funcţie h(x, θ)
– x este un vector al intrărilor în model
– θ este un vector de parametri interni modelului
●
Exemplu: un model de prezicere dacă vom
avea rezultate sub medie sau peste medie în
cazul unui examen, ştiind numărul de ore
dormite şi nr. de ore de studiu în pregătirea sa:
x=[x1, x2]T x1
– nr. ore dormite
x2
– nr. ore studiu
θ=[θ 1,θ 2,θ 0]T
h(x ,θ)=
{
−1dacă xT
⋅
[θ 1
θ 2]+θ 0<0
1dacă xT
⋅
[θ 1
θ 2
]+θ 0≥0](https://image.slidesharecdn.com/deeplearninguoradea-parti-ian2018-new-180131111840/75/Deep-learning-UOradea-partea-I-ianuarie-2018-15-2048.jpg)










![презентация Microsoft office_power_point_(3)[1]](https://cdn.slidesharecdn.com/ss_thumbnails/microsoftofficepowerpoint31-110221022623-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)