Download to read offline




























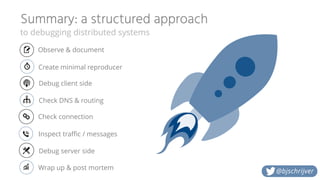




This document outlines a structured approach to debugging distributed systems. It begins with observing and documenting the problem. The next steps involve creating a minimal reproducer, debugging the client and server sides, and checking DNS, routing, and network connections. Traffic and messages should also be inspected. The process concludes by wrapping up findings and conducting a post-mortem analysis. Key challenges in distributed systems like concurrency, lack of a global clock, and independent failures are discussed.





























































