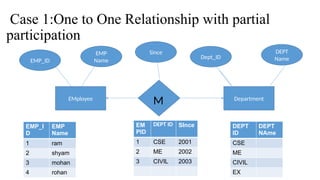
The document provides an overview of database management systems, focusing on the relational model proposed by E.F. Codd, including essential concepts such as attributes, tuples, relations, and schemas. It also discusses key types such as super keys, candidate keys, primary keys, and constraints like domain integrity and referential integrity. Furthermore, it covers anomalies in database operations and the process of converting entity-relationship diagrams into relational tables.