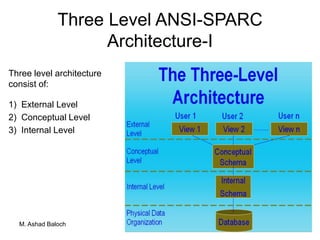
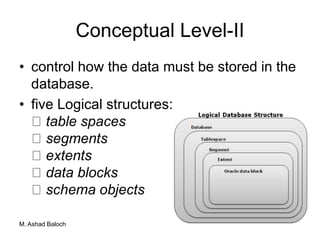
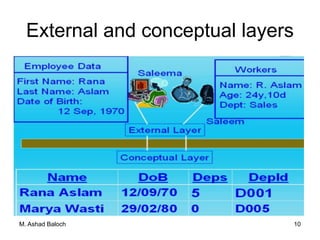
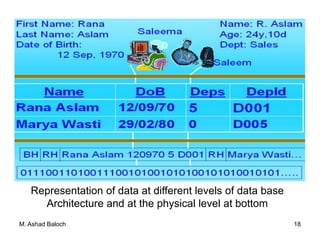
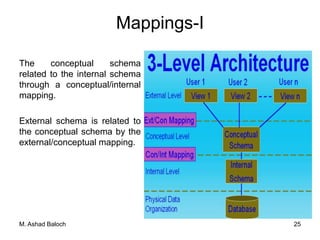
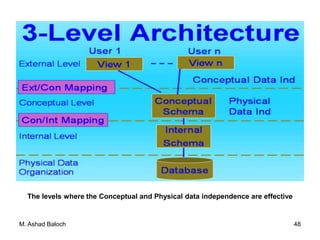
The document details the three-level ANSI-SPARC architecture of database management systems (DBMS), which includes external, conceptual, and internal levels, each serving distinct functions in data representation and user access. It emphasizes the importance of data independence, which allows for changes in the internal structure without affecting user views and applications. Additionally, it outlines the functions and environments of DBMS, including single-user and multi-user systems.