Download to read offline
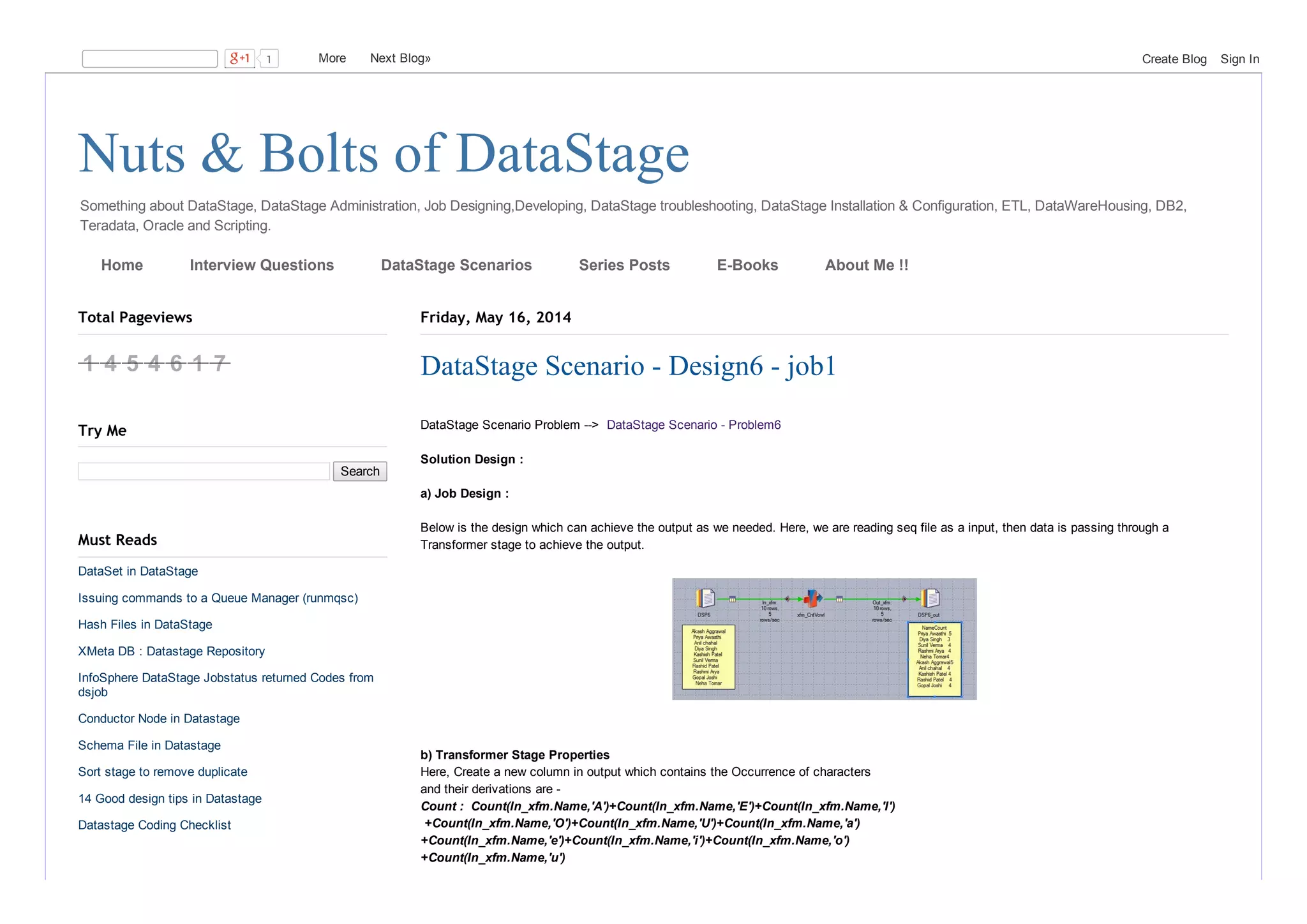
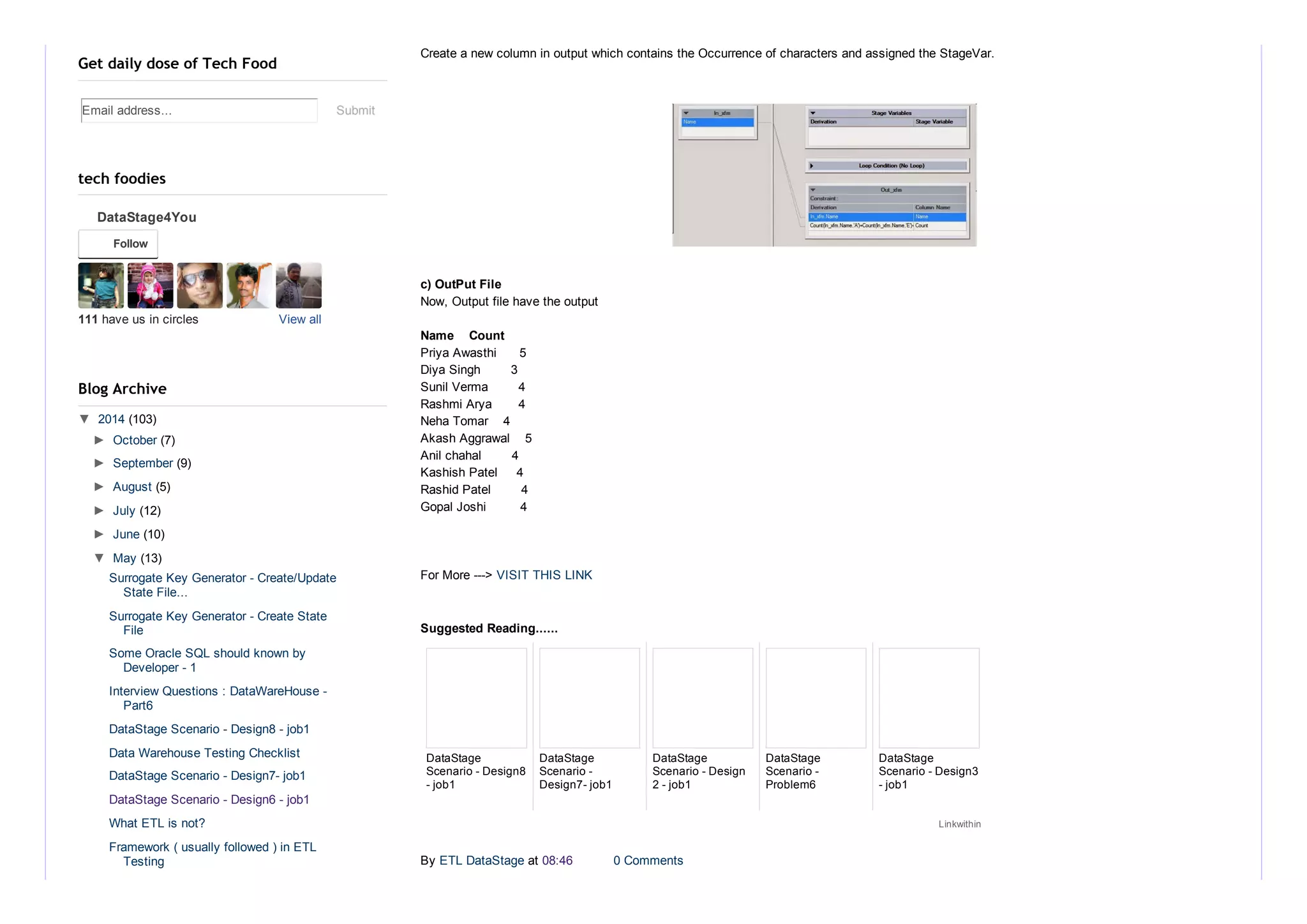


This document discusses a DataStage scenario problem and its solution design. It involves reading input from a sequential file, passing the data through a transformer stage to create a new column that counts the occurrences of vowels in each name, and writing the output to a file. The output file includes the names from the input and their associated vowel counts.















