Download as PDF, PPTX



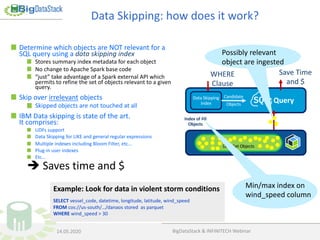
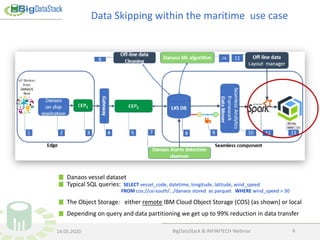




The document discusses data skipping technology, particularly in the context of Apache Spark and its application to big data analytics, focusing on minimizing data transfer during queries. It highlights how IBM has integrated this technology into its products to enhance efficiency, achieving up to 99% reduction in data transfer when accessing maritime datasets. The document also outlines future developments and contributions to the Big Data Stack and Infinitech projects.






















































































