Download to read offline
![movie
April 9, 2020
1 Analyzed 5,000 box offices with Python and found that the movies
that make money have these characteristics
When a general film company makes a new movie and puts it on the market, to succeed, it is usu-
ally necessary to understand the film market trends, the types of movies that audiences like, the
distribution of movies, the profitability of adaptations and original movies, and what audiences
like Content.
So this article will do a data analysis about the film industry.
2 1. Ask a question
This case comes from the TMDB 5000 Movie Dataset data on Kaggle. In order to explore the
visualization of movie data and provide data support for the production of movies, the following
issues are mainly studied:
• How does the genre of the film change over time?
• What is the relationship between film type and profit?
• How does Universal and Paramount compare?
• What is the relationship between movie duration and movie box office and rating?
3 2. Understand the Data
2.1 Collect data
Download the dataset from TMDB 5000 Movie Dataset on Kaggle:
https://www.kaggle.com/tmdb/tmdb-movie-metadata
2.2 Import data
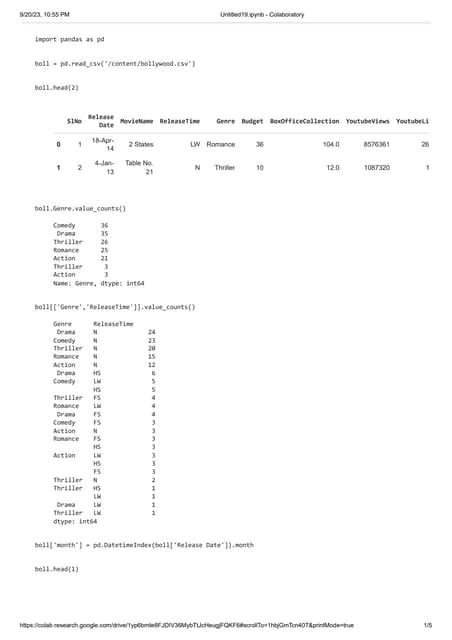
[156]: import json
import pandas as pd
import numpy as np
from pandas import Series,DataFrame
from datetime import datetime
import warnings
warnings.filterwarnings(ignore)
1](https://image.slidesharecdn.com/datascience-movie-200409044822/85/Data-Science-The-Most-Profitable-Movie-Characteristic-1-320.jpg)
![movie
April 9, 2020
1 Analyzed 5,000 box offices with Python and found that the movies
that make money have these characteristics
When a general film company makes a new movie and puts it on the market, to succeed, it is usu-
ally necessary to understand the film market trends, the types of movies that audiences like, the
distribution of movies, the profitability of adaptations and original movies, and what audiences
like Content.
So this article will do a data analysis about the film industry.
2 1. Ask a question
This case comes from the TMDB 5000 Movie Dataset data on Kaggle. In order to explore the
visualization of movie data and provide data support for the production of movies, the following
issues are mainly studied:
• How does the genre of the film change over time?
• What is the relationship between film type and profit?
• How does Universal and Paramount compare?
• What is the relationship between movie duration and movie box office and rating?
3 2. Understand the Data
2.1 Collect data
Download the dataset from TMDB 5000 Movie Dataset on Kaggle:
https://www.kaggle.com/tmdb/tmdb-movie-metadata
2.2 Import data
[156]: import json
import pandas as pd
import numpy as np
from pandas import Series,DataFrame
from datetime import datetime
import warnings
warnings.filterwarnings(ignore)
1](https://image.slidesharecdn.com/datascience-movie-200409044822/75/Data-Science-The-Most-Profitable-Movie-Characteristic-1-2048.jpg)
![# Visualization
import matplotlib.pyplot as plt
import seaborn as sns
#from wordcloud import WordCloud, STOPWORDS, ImageColorGenerator
from scipy.misc import imread
%matplotlib inline
[157]: credits_file=/home/nbuser/tmdb_5000_credits.csv
movies_file=/home/nbuser/tmdb_5000_movies.csv
credits=pd.read_csv(credits_file)
movies=pd.read_csv(movies_file)
2.3 View the data set information
[158]: credits.head()
[158]: movie_id title
0 19995 Avatar
1 285 Pirates of the Caribbean: At Worlds End
2 206647 Spectre
3 49026 The Dark Knight Rises
4 49529 John Carter
cast
0 [{cast_id: 242, character: Jake Sully, ...
1 [{cast_id: 4, character: Captain Jack Spa...
2 [{cast_id: 1, character: James Bond, cr...
3 [{cast_id: 2, character: Bruce Wayne / Ba...
4 [{cast_id: 5, character: John Carter, c...
crew
0 [{credit_id: 52fe48009251416c750aca23, de...
1 [{credit_id: 52fe4232c3a36847f800b579, de...
2 [{credit_id: 54805967c3a36829b5002c41, de...
3 [{credit_id: 52fe4781c3a36847f81398c3, de...
4 [{credit_id: 52fe479ac3a36847f813eaa3, de...
[159]: movies.head()
[159]: budget genres
0 237000000 [{id: 28, name: Action}, {id: 12, nam...
1 300000000 [{id: 12, name: Adventure}, {id: 14, ...
2 245000000 [{id: 28, name: Action}, {id: 12, nam...
3 250000000 [{id: 28, name: Action}, {id: 80, nam...
4 260000000 [{id: 28, name: Action}, {id: 12, nam...
homepage id
0 http://www.avatarmovie.com/ 19995
1 http://disney.go.com/disneypictures/pirates/ 285
2 http://www.sonypictures.com/movies/spectre/ 206647
2](https://image.slidesharecdn.com/datascience-movie-200409044822/85/Data-Science-The-Most-Profitable-Movie-Characteristic-2-320.jpg)
![3 http://www.thedarkknightrises.com/ 49026
4 http://movies.disney.com/john-carter 49529
keywords original_language
0 [{id: 1463, name: culture clash}, {id:... en
1 [{id: 270, name: ocean}, {id: 726, na... en
2 [{id: 470, name: spy}, {id: 818, name... en
3 [{id: 849, name: dc comics}, {id: 853,... en
4 [{id: 818, name: based on novel}, {id:... en
original_title
0 Avatar
1 Pirates of the Caribbean: At Worlds End
2 Spectre
3 The Dark Knight Rises
4 John Carter
overview popularity
0 In the 22nd century, a paraplegic Marine is di... 150.437577
1 Captain Barbossa, long believed to be dead, ha... 139.082615
2 A cryptic message from Bonds past sends him o... 107.376788
3 Following the death of District Attorney Harve... 112.312950
4 John Carter is a war-weary, former military ca... 43.926995
production_companies
0 [{name: Ingenious Film Partners, id: 289...
1 [{name: Walt Disney Pictures, id: 2}, {...
2 [{name: Columbia Pictures, id: 5}, {nam...
3 [{name: Legendary Pictures, id: 923}, {...
4 [{name: Walt Disney Pictures, id: 2}]
production_countries release_date revenue
0 [{iso_3166_1: US, name: United States o... 2009-12-10 2787965087
1 [{iso_3166_1: US, name: United States o... 2007-05-19 961000000
2 [{iso_3166_1: GB, name: United Kingdom... 2015-10-26 880674609
3 [{iso_3166_1: US, name: United States o... 2012-07-16 1084939099
4 [{iso_3166_1: US, name: United States o... 2012-03-07 284139100
runtime spoken_languages status
0 162.0 [{iso_639_1: en, name: English}, {iso... Released
1 169.0 [{iso_639_1: en, name: English}] Released
2 148.0 [{iso_639_1: fr, name: Franu00e7ais},... Released
3 165.0 [{iso_639_1: en, name: English}] Released
4 132.0 [{iso_639_1: en, name: English}] Released
tagline
0 Enter the World of Pandora.
3](https://image.slidesharecdn.com/datascience-movie-200409044822/85/Data-Science-The-Most-Profitable-Movie-Characteristic-3-320.jpg)
![1 At the end of the world, the adventure begins.
2 A Plan No One Escapes
3 The Legend Ends
4 Lost in our world, found in another.
title vote_average vote_count
0 Avatar 7.2 11800
1 Pirates of the Caribbean: At Worlds End 6.9 4500
2 Spectre 6.3 4466
3 The Dark Knight Rises 7.6 9106
4 John Carter 6.1 2124
4 3. Data Cleaning
3.1 First merge the data in the credits data set and the movie data set, and then view the merged
data set information:
[160]: fulldf=pd.concat([credits,movies],axis=1)
fulldf.info()
class pandas.core.frame.DataFrame
RangeIndex: 4803 entries, 0 to 4802
Data columns (total 24 columns):
movie_id 4803 non-null int64
title 4803 non-null object
cast 4803 non-null object
crew 4803 non-null object
budget 4803 non-null int64
genres 4803 non-null object
homepage 1712 non-null object
id 4803 non-null int64
keywords 4803 non-null object
original_language 4803 non-null object
original_title 4803 non-null object
overview 4800 non-null object
popularity 4803 non-null float64
production_companies 4803 non-null object
production_countries 4803 non-null object
release_date 4802 non-null object
revenue 4803 non-null int64
runtime 4801 non-null float64
spoken_languages 4803 non-null object
status 4803 non-null object
tagline 3959 non-null object
title 4803 non-null object
vote_average 4803 non-null float64
vote_count 4803 non-null int64
4](https://image.slidesharecdn.com/datascience-movie-200409044822/85/Data-Science-The-Most-Profitable-Movie-Characteristic-4-320.jpg)
![dtypes: float64(3), int64(5), object(16)
memory usage: 900.6+ KB
3.2 Select subset
Because the data set contains too much information, some of the data is not the focus of our
research, so we choose the data we need:
[161]: moviesdf=fulldf[[original_title,crew,release_date,genres,keywords,production_companie
moviesdf.info()
class pandas.core.frame.DataFrame
RangeIndex: 4803 entries, 0 to 4802
Data columns (total 11 columns):
original_title 4803 non-null object
crew 4803 non-null object
release_date 4802 non-null object
genres 4803 non-null object
keywords 4803 non-null object
production_companies 4803 non-null object
production_countries 4803 non-null object
revenue 4803 non-null int64
budget 4803 non-null int64
runtime 4801 non-null float64
vote_average 4803 non-null float64
dtypes: float64(2), int64(2), object(7)
memory usage: 412.8+ KB
Since the subsequent data analysis involves the calculation of the profit of the movie type, first
find the profit of each movie, and add the profit data column to the dataset movies
[162]: moviesdf[profit]=moviesdf[revenue]-moviesdf[budget]
moviesdf.head()
[162]: original_title
0 Avatar
1 Pirates of the Caribbean: At Worlds End
2 Spectre
3 The Dark Knight Rises
4 John Carter
crew release_date
0 [{credit_id: 52fe48009251416c750aca23, de... 2009-12-10
1 [{credit_id: 52fe4232c3a36847f800b579, de... 2007-05-19
2 [{credit_id: 54805967c3a36829b5002c41, de... 2015-10-26
3 [{credit_id: 52fe4781c3a36847f81398c3, de... 2012-07-16
4 [{credit_id: 52fe479ac3a36847f813eaa3, de... 2012-03-07
genres
0 [{id: 28, name: Action}, {id: 12, nam...
1 [{id: 12, name: Adventure}, {id: 14, ...
5](https://image.slidesharecdn.com/datascience-movie-200409044822/85/Data-Science-The-Most-Profitable-Movie-Characteristic-5-320.jpg)
![2 [{id: 28, name: Action}, {id: 12, nam...
3 [{id: 28, name: Action}, {id: 80, nam...
4 [{id: 28, name: Action}, {id: 12, nam...
keywords
0 [{id: 1463, name: culture clash}, {id:...
1 [{id: 270, name: ocean}, {id: 726, na...
2 [{id: 470, name: spy}, {id: 818, name...
3 [{id: 849, name: dc comics}, {id: 853,...
4 [{id: 818, name: based on novel}, {id:...
production_companies
0 [{name: Ingenious Film Partners, id: 289...
1 [{name: Walt Disney Pictures, id: 2}, {...
2 [{name: Columbia Pictures, id: 5}, {nam...
3 [{name: Legendary Pictures, id: 923}, {...
4 [{name: Walt Disney Pictures, id: 2}]
production_countries revenue budget
0 [{iso_3166_1: US, name: United States o... 2787965087 237000000
1 [{iso_3166_1: US, name: United States o... 961000000 300000000
2 [{iso_3166_1: GB, name: United Kingdom... 880674609 245000000
3 [{iso_3166_1: US, name: United States o... 1084939099 250000000
4 [{iso_3166_1: US, name: United States o... 284139100 260000000
runtime vote_average profit
0 162.0 7.2 2550965087
1 169.0 6.9 661000000
2 148.0 6.3 635674609
3 165.0 7.6 834939099
4 132.0 6.1 24139100
3.3 Processiong of missing values
It can be known from the above data set information: the missing data of the entire data set
is relatively small One release_date (first release date) is missing 1 data, and the runtime (movie
duration) is missing 2 data. You can complete this data through online query.
Fill in the release_date (first release date) data
[163]: release_date_null=moviesdf[release_date].isnull()
moviesdf.loc[release_date_null,:]
[163]: original_title crew release_date genres keywords
4553 America Is Still the Place [] NaN [] []
production_companies production_countries revenue budget runtime
4553 [] [] 0 0 0.0
vote_average profit
4553 0.0 0
6](https://image.slidesharecdn.com/datascience-movie-200409044822/85/Data-Science-The-Most-Profitable-Movie-Characteristic-6-320.jpg)
![[164]: moviesdf[release_date]=movies[release_date].fillna(2014-06-01)
moviesdf[release_date]=pd.
→to_datetime(moviesdf[release_date],format=%Y-%m-%d)
moviesdf.info()
class pandas.core.frame.DataFrame
RangeIndex: 4803 entries, 0 to 4802
Data columns (total 12 columns):
original_title 4803 non-null object
crew 4803 non-null object
release_date 4803 non-null datetime64[ns]
genres 4803 non-null object
keywords 4803 non-null object
production_companies 4803 non-null object
production_countries 4803 non-null object
revenue 4803 non-null int64
budget 4803 non-null int64
runtime 4801 non-null float64
vote_average 4803 non-null float64
profit 4803 non-null int64
dtypes: datetime64[ns](1), float64(2), int64(3), object(6)
memory usage: 450.4+ KB
Find the missing data of runtime (movie duration):
[165]: runtime_date_null=moviesdf[runtime].isnull()
moviesdf.loc[runtime_date_null,:]
[165]: original_title
2656 Chiamatemi Francesco - Il Papa della gente
4140 To Be Frank, Sinatra at 100
crew release_date
2656 [{credit_id: 5660019ac3a36875f100252b, de... 2015-12-03
4140 [{credit_id: 592b25e4c3a368783e065a2f, de... 2015-12-12
genres
2656 [{id: 18, name: Drama}]
4140 [{id: 99, name: Documentary}]
keywords
2656 [{id: 717, name: pope}, {id: 5565, na...
4140 [{id: 6027, name: music}, {id: 225822,...
production_companies
2656 [{name: Taodue Film, id: 45724}]
4140 [{name: Eyeline Entertainment, id: 60343}]
production_countries revenue budget
7](https://image.slidesharecdn.com/datascience-movie-200409044822/85/Data-Science-The-Most-Profitable-Movie-Characteristic-7-320.jpg)
![2656 [{iso_3166_1: IT, name: Italy}] 0 15000000
4140 [{iso_3166_1: GB, name: United Kingdom}] 0 2
runtime vote_average profit
2656 NaN 7.3 -15000000
4140 NaN 0.0 -2
Fill missing values in runtime
[166]: values1 = {runtime:98.0}
values2 = {runtime:81.0}
moviesdf.fillna(value=values1,limit=1,inplace=True)
moviesdf.fillna(value=values2,limit=1,inplace=True)
moviesdf.loc[runtime_null,:]
[166]: Empty DataFrame
Columns: [original_title, crew, release_date, genres, keywords,
production_companies, production_countries, revenue, budget, runtime,
vote_average, profit]
Index: []
3.4 Data format conversion
genres column data processing:
[167]: moviesdf[genres] = moviesdf[genres].apply(json.loads)
def decode(column):
z = []
for i in column:
z.append(i[name])
return .join(z)
moviesdf[genres] = moviesdf[genres].apply(decode)
moviesdf.head(2)
[167]: original_title
0 Avatar
1 Pirates of the Caribbean: At Worlds End
crew release_date
0 [{credit_id: 52fe48009251416c750aca23, de... 2009-12-10
1 [{credit_id: 52fe4232c3a36847f800b579, de... 2007-05-19
genres
0 Action Adventure Fantasy Science Fiction
1 Adventure Fantasy Action
keywords
0 [{id: 1463, name: culture clash}, {id:...
1 [{id: 270, name: ocean}, {id: 726, na...
8](https://image.slidesharecdn.com/datascience-movie-200409044822/85/Data-Science-The-Most-Profitable-Movie-Characteristic-8-320.jpg)
![production_companies
0 [{name: Ingenious Film Partners, id: 289...
1 [{name: Walt Disney Pictures, id: 2}, {...
production_countries revenue budget
0 [{iso_3166_1: US, name: United States o... 2787965087 237000000
1 [{iso_3166_1: US, name: United States o... 961000000 300000000
runtime vote_average profit
0 162.0 7.2 2550965087
1 169.0 6.9 661000000
[168]: genres_list=set()
for i in moviesdf[genres].str.split( ):
genres_list=set().union(i,genres_list)
genres_list=list(genres_list)
genres_list
genres_list.remove()
print(genres_list)
[Foreign, Action, Thriller, Science, Drama, TV, Music, Western,
Comedy, Adventure, Horror, Movie, Mystery, Romance, Fantasy,
Crime, War, History, Fiction, Animation, Family, Documentary]
Data processing of release_date column:
[169]: moviesdf[release_date] = pd.to_datetime(moviesdf[release_date]).dt.year
columns = {release_date:year}
moviesdf.rename(columns=columns,inplace=True)
moviesdf[year].apply(int).head()
[169]: 0 2009
1 2007
2 2015
3 2012
4 2012
Name: year, dtype: int64
5 4. Data analysis and visualization
Q1 : How does the genre of the film change over time?
1 Establish a data frame containing the relationship between the year and the number of movie
types:
[170]: for genre in genres_list:
moviesdf[genre] = moviesdf[genres].str.contains(genre).apply(lambda x:1 if
→x else 0)
9](https://image.slidesharecdn.com/datascience-movie-200409044822/85/Data-Science-The-Most-Profitable-Movie-Characteristic-9-320.jpg)
![moviesdf[genre].tail()
genre_year = moviesdf.loc[:,genres_list]
genre_year.tail(2)
[170]: Foreign Action Thriller Science Drama TV Music Western Comedy
4801 0 0 0 0 0 0 0 0 0
4802 0 0 0 0 0 0 0 0 0
Adventure ... Mystery Romance Fantasy Crime War History
4801 0 ... 0 0 0 0 0 0
4802 0 ... 0 0 0 0 0 0
Fiction Animation Family Documentary
4801 0 0 0 0
4802 0 0 0 1
[2 rows x 22 columns]
[171]: genre_year.index = moviesdf[year]
genresdf = genre_year.groupby(year).sum()
genresdf.tail()
[171]: Foreign Action Thriller Science Drama TV Music Western Comedy
year
2013 0 56 53 27 110 2 12 1 71
2014 0 54 66 26 110 0 9 3 62
2015 0 46 67 28 95 0 8 7 52
2016 0 39 27 11 37 0 1 1 26
2017 0 0 0 0 1 0 0 0 1
Adventure ... Mystery Romance Fantasy Crime War History
year ...
2013 36 ... 5 25 21 37 3 8
2014 37 ... 15 24 16 27 10 7
2015 35 ... 20 23 10 26 2 9
2016 23 ... 6 9 13 10 3 6
2017 0 ... 0 0 0 0 0 0
Fiction Animation Family Documentary
year
2013 27 17 22 10
2014 26 14 23 7
2015 28 13 17 7
2016 11 4 9 0
10](https://image.slidesharecdn.com/datascience-movie-200409044822/85/Data-Science-The-Most-Profitable-Movie-Characteristic-10-320.jpg)
![2017 0 0 1 0
[5 rows x 22 columns]
[172]: genresdfSum = genresdf.sum(axis=0).sort_values(ascending=False)
genresdfSum
[172]: Drama 2297
Comedy 1722
Thriller 1274
Action 1154
Romance 894
Adventure 790
Crime 696
Science 535
Fiction 535
Horror 519
Family 513
Fantasy 424
Mystery 348
Animation 234
History 197
Music 185
War 144
Documentary 110
Western 82
Foreign 34
TV 8
Movie 8
dtype: int64
2. Data visualization
Plot histograms of various movie types:
[173]: plt.figure(figsize=(12,8))
plt.subplot(111)
genresdfSum.sort_values().plot(kind=barh,label=genres)
plt.title(Statistics of the number of movie genres ranking)
plt.xlabel(movies number)
plt.ylabel(movies type)
plt.show()
11](https://image.slidesharecdn.com/datascience-movie-200409044822/85/Data-Science-The-Most-Profitable-Movie-Characteristic-11-320.jpg)
![Draw a pie chart of the proportion of various movie types:
[174]: genres_pie = genresdfSum / genresdfSum.sum()
others = 0.01
genres_pie_otr = genres_pie[genres_pie = others]
genres_pie_otr[Other] = genres_pie[genres_pie others].sum()
explode = (genres_pie_otr = 0.02) / 10 + 0.04
genres_pie_otr.
→plot(kind=pie,label=,startangle=50,shadow=False,figsize=(10,10),autopct=%1.
→1f%%,explode=explode)
plt.title(The proportion of various film types)
[174]: Text(0.5, 1.0, The proportion of various film types)
12](https://image.slidesharecdn.com/datascience-movie-200409044822/85/Data-Science-The-Most-Profitable-Movie-Characteristic-12-320.jpg)
![3 Trend analysis of movie types over time
[175]: plt.figure(figsize=(12,8))
plt.plot(genresdf,label=genresdf.columns)
plt.xticks(range(1910,2020,5))
plt.legend(genresdf)
plt.title(Trends of movie genres over time,fontsize=15)
plt.xlabel(year,fontsize=15)
plt.ylabel(movies number,fontsize=15)
plt.grid(True)
plt.show()
13](https://image.slidesharecdn.com/datascience-movie-200409044822/85/Data-Science-The-Most-Profitable-Movie-Characteristic-13-320.jpg)
![Q2: What is the relationship between film type and profit?
First find the average profit of various movie genres:
[176]: mean_genre_profit = pd.DataFrame(index=genres_list)
mean_genre_profit.head(2)
newarray = []
for genre in genres_list:
newarray.append(moviesdf.groupby(genre,as_index=True)[profit].mean())
newarray2 = []
for i in range(len(genres_list)):
newarray2.append(newarray[i][1])
mean_genre_profit[mean_profit] = newarray2
mean_genre_profit.head()
[176]: mean_profit
Foreign -2.934369e+05
Action 8.970235e+07
Thriller 4.907608e+07
Science 1.005910e+08
Drama 3.143791e+07
[177]: plt.figure(figsize=(12,8))
mean_genre_profit.sort_values(by=mean_profit).plot(kind=barh)
14](https://image.slidesharecdn.com/datascience-movie-200409044822/85/Data-Science-The-Most-Profitable-Movie-Characteristic-14-320.jpg)
![plt.xlabel(avg_profit)
plt.ylabel(movies_type)
plt.title(type avg_profit)
[177]: Text(0.5, 1.0, type avg_profit)
Figure size 864x576 with 0 Axes
Visualization of movie type average profit data
Q3: How does the comparison between Universal Pictures and Paramount Pictures release
films?
Universal Pictures (Universal Pictures) and Paramount Pictures (Paramount Pictures) are two
American film giants.
1. Check the number of film releases of Universal Pictures and Paramount Pictures
[178]: moviesdf[production_companies] = moviesdf[production_companies].apply(json.
→loads)
moviesdf[production_companies] = moviesdf[production_companies].apply(decode)
moviesdf.head(2)
moviesdf[Universal Pictures] = moviesdf[production_companies].str.
→contains(Universal Pictures).apply(lambda x:1 if x else 0)
15](https://image.slidesharecdn.com/datascience-movie-200409044822/85/Data-Science-The-Most-Profitable-Movie-Characteristic-15-320.jpg)
![moviesdf[Paramount Pictures] = moviesdf[production_companies].str.
→contains(Paramount Pictures).apply(lambda x:1 if x else 0)
moviesdf.head(1)
a=moviesdf[Paramount Pictures].sum()
b=moviesdf[Universal Pictures].sum()
dict_companies = {Universal Pictures: b,Paramount Pictures:a}
companies_number = pd.Series(dict_companies)
companies_number
companies_number.plot(kind=pie,label=,autopct=%11.1f%%)
[178]: matplotlib.axes._subplots.AxesSubplot at 0x7ff8cd30f940
Analyze the trend of film distribution of Universal Pictures and Paramount Pictures
Extract relevant data columns for processing:
[179]: companydf=moviesdf[[Universal Pictures,Paramount Pictures]]
companydf.index=moviesdf[year]
companydf=companydf.groupby(year).sum()
companydf.tail()
[179]: Universal Pictures Paramount Pictures
year
2013 9 8
2014 10 8
2015 13 7
2016 10 5
2017 0 0
16](https://image.slidesharecdn.com/datascience-movie-200409044822/85/Data-Science-The-Most-Profitable-Movie-Characteristic-16-320.jpg)
![Line charts of film releases of two film and television companies:
[147]: company=moviesdf[[Universal Pictures,Paramount Pictures]]
company.index=moviesdf[year]
companydf=company.groupby(year).sum()
companydf.tail()
plt.figure(figsize=(14,8))
plt.plot(companydf,label = companydf.columns)
[147]: [matplotlib.lines.Line2D at 0x7ff8f20aff60,
matplotlib.lines.Line2D at 0x7ff8f20af860]
Q4. Relationship between movie duration and movie box office and rating
The relationship between movie duration and movie box office:
[114]: moviesdf.plot(kind=scatter, x=runtime, y=revenue, figsize=(8, 6))
plt.title(The relationship between movie duration and movie box
→office,fontsize=15)
plt.xlabel(minute,fontsize=15)
plt.ylabel($,fontsize=15)
plt.grid(True)
17](https://image.slidesharecdn.com/datascience-movie-200409044822/85/Data-Science-The-Most-Profitable-Movie-Characteristic-17-320.jpg)
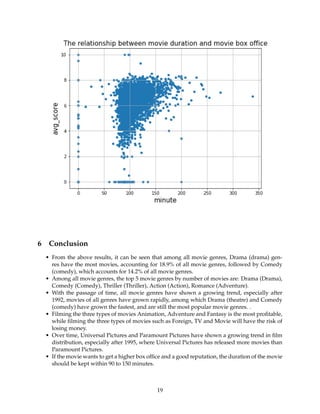
![The relationship between movie duration and average movie rating:
[115]: moviesdf.plot(kind=scatter, x=runtime, y=vote_average, figsize=(8, 6))
plt.title(The relationship between movie duration and movie box
→office,fontsize=15)
plt.xlabel(minute,fontsize=15)
plt.ylabel(avg_score,fontsize=15)
plt.grid(True)
plt.show()
18](https://image.slidesharecdn.com/datascience-movie-200409044822/85/Data-Science-The-Most-Profitable-Movie-Characteristic-18-320.jpg)

The document analyzes movie data from the TMDB 5000 Movie Dataset to understand characteristics of profitable movies. It explores relationships between genres, movie types and profits over time. The data is cleaned by merging movie and credits datasets, selecting relevant columns, and filling in missing values for release date and runtime. Three main issues are studied: how genres change over time, the relationship between type and profit, and comparisons between production companies.








![[Custom Data] Alice Nguyen](https://cdn.slidesharecdn.com/ss_thumbnails/alicenguyenawsdevax2021-211019042627-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Custom Data] Alice Nguyen](https://cdn.slidesharecdn.com/ss_thumbnails/alicenguyenawsdevax2021-211019040708-thumbnail.jpg?width=640&height=640&fit=bounds)