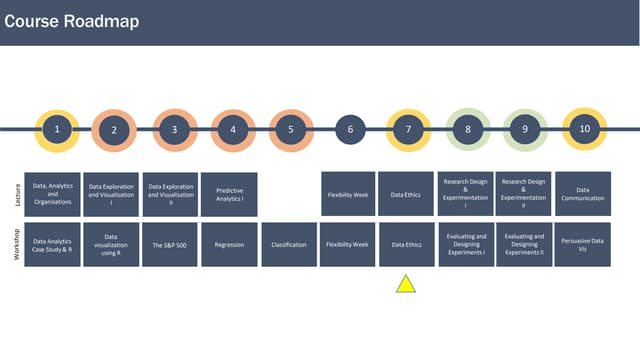
The document outlines a data ethics framework emphasizing the importance of proportional data use based on user needs, while considering issues like data anonymization, pseudonymization, and the ethical implications of using various data sources. It discusses the responsible use of repurposed operational and third-party data, including social media and web-scraped data, while assessing data limitations such as bias, provenance, and errors. The framework encourages collaborative evaluations among multidisciplinary teams to ensure data usage aligns with ethical standards and regulations.