Downloaded 17 times









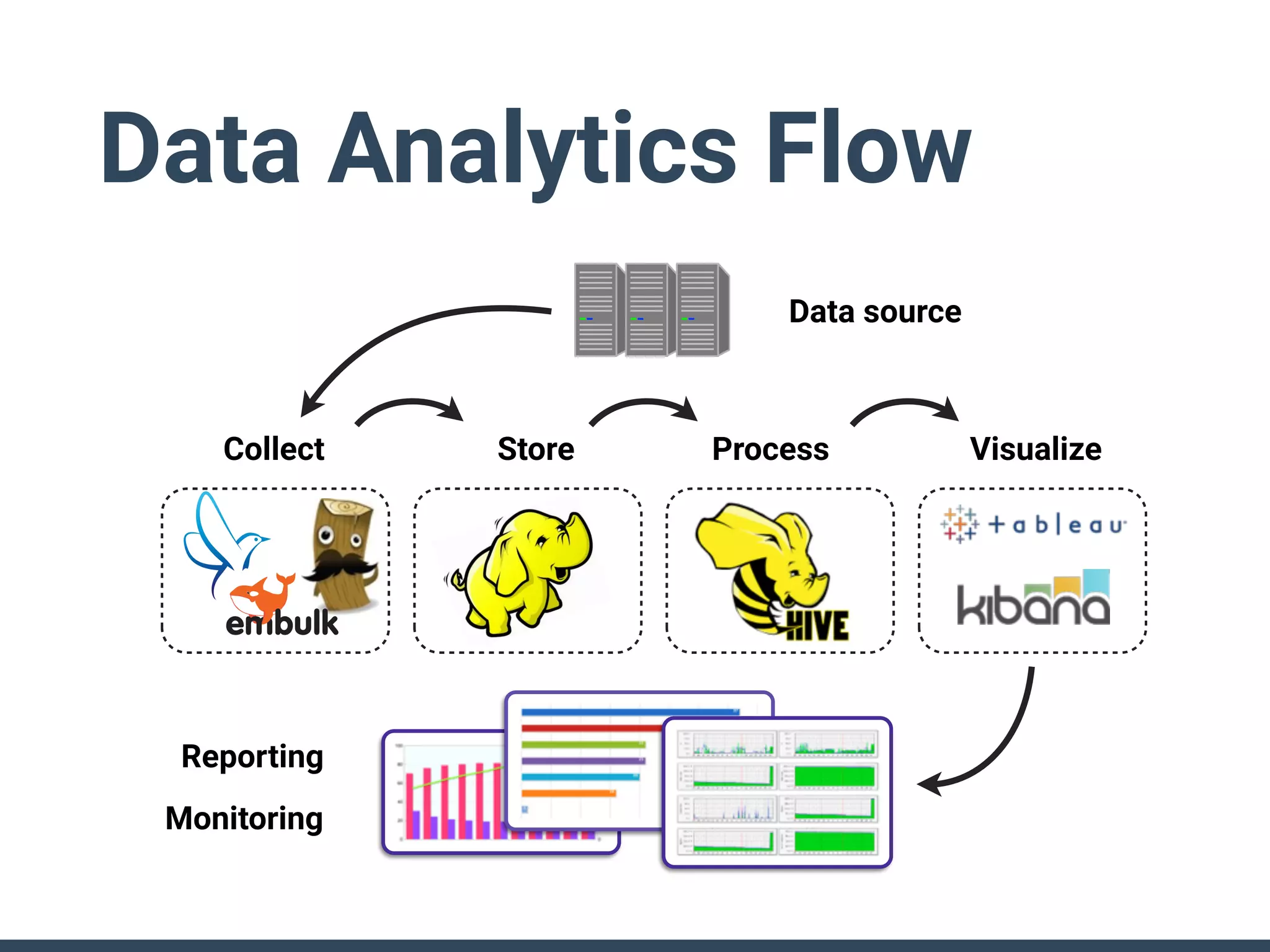
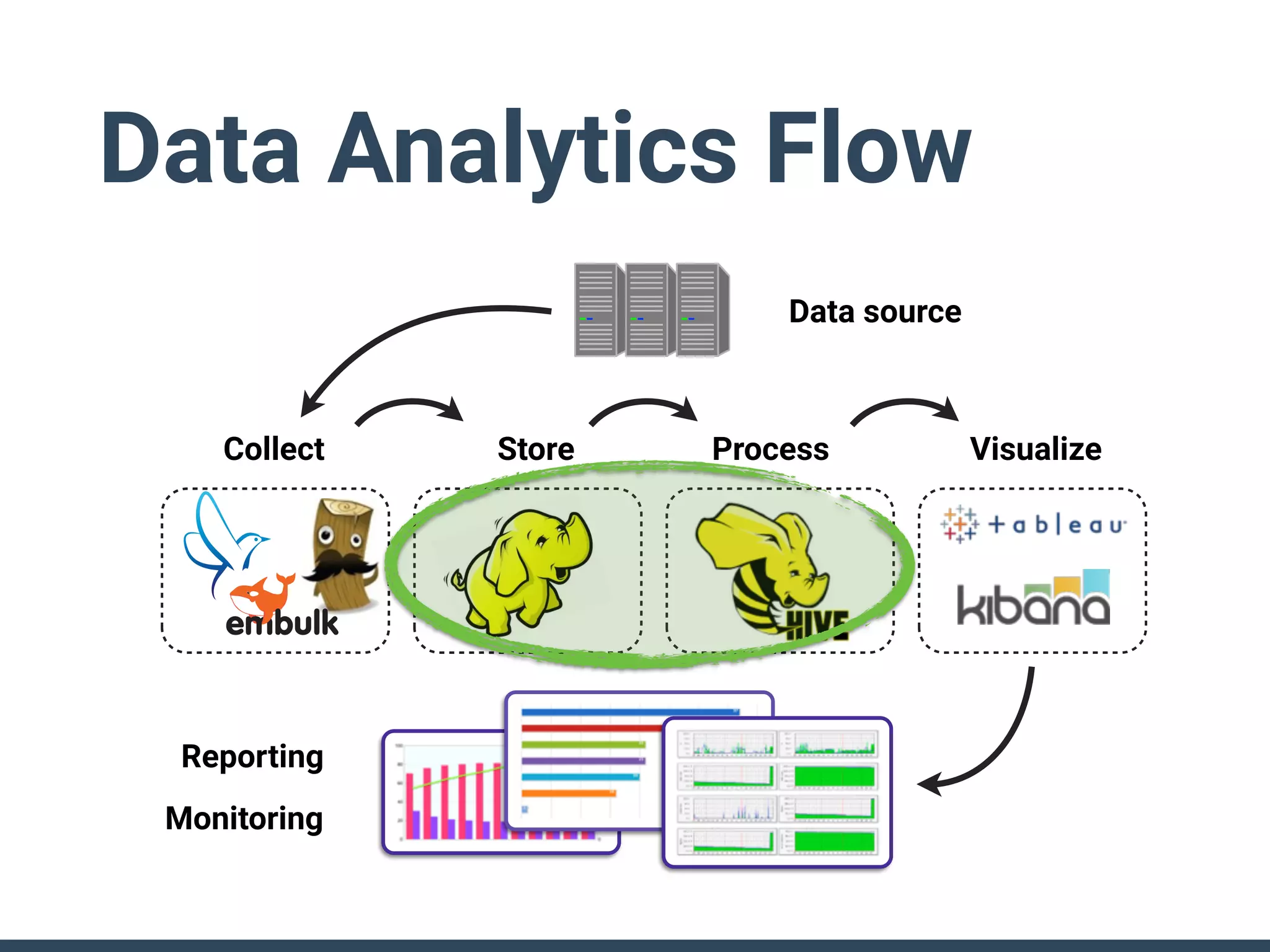



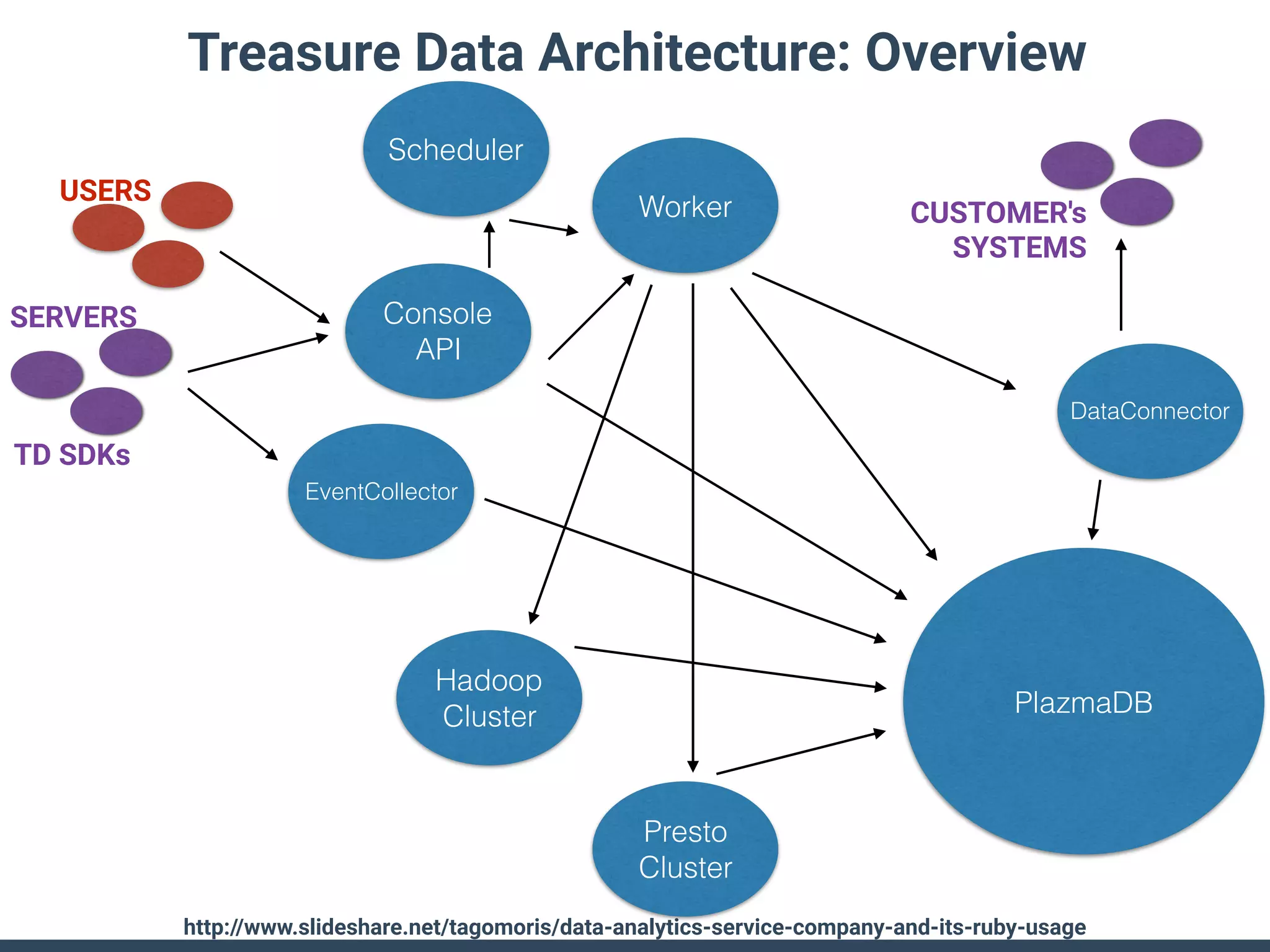
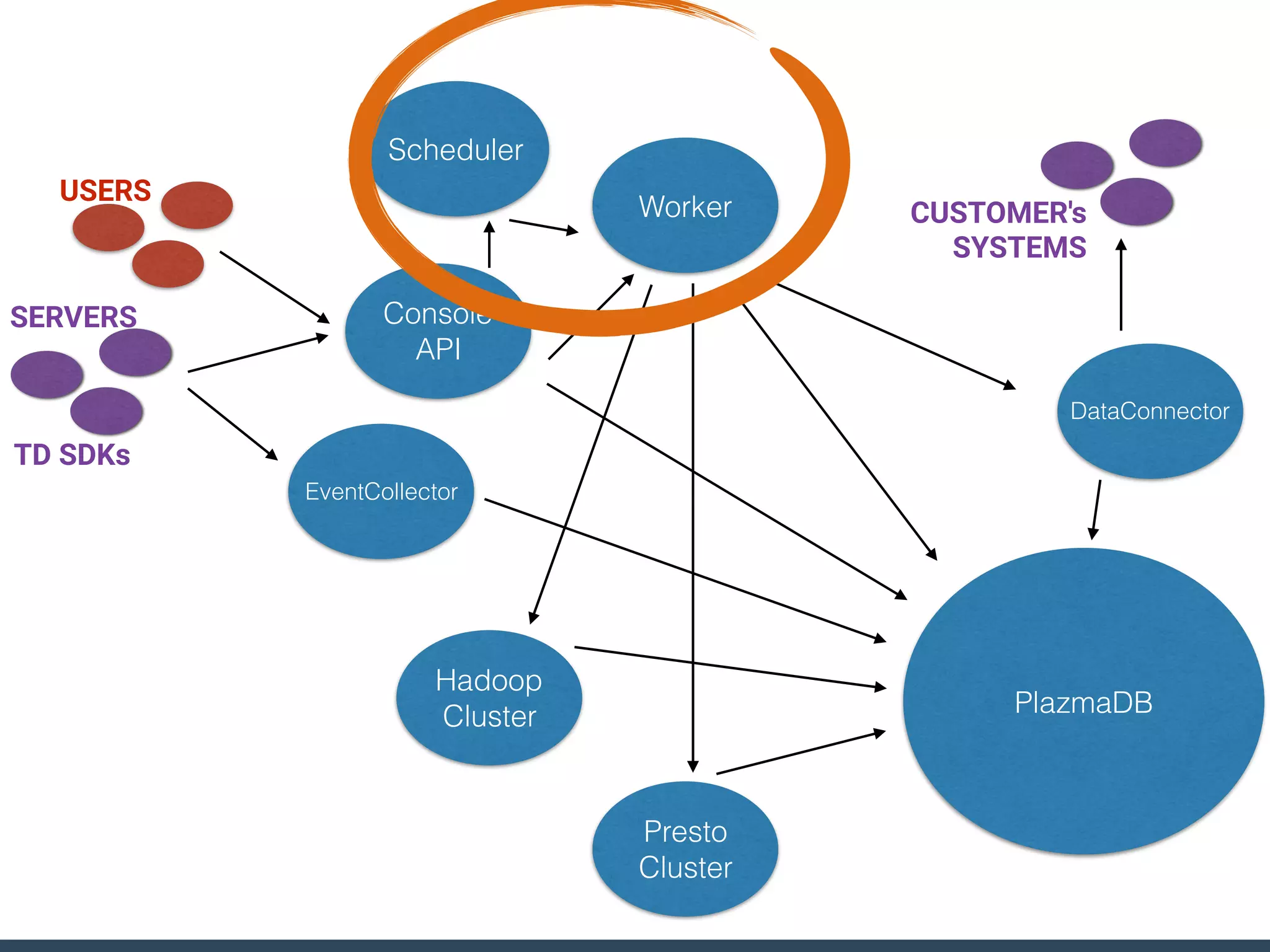
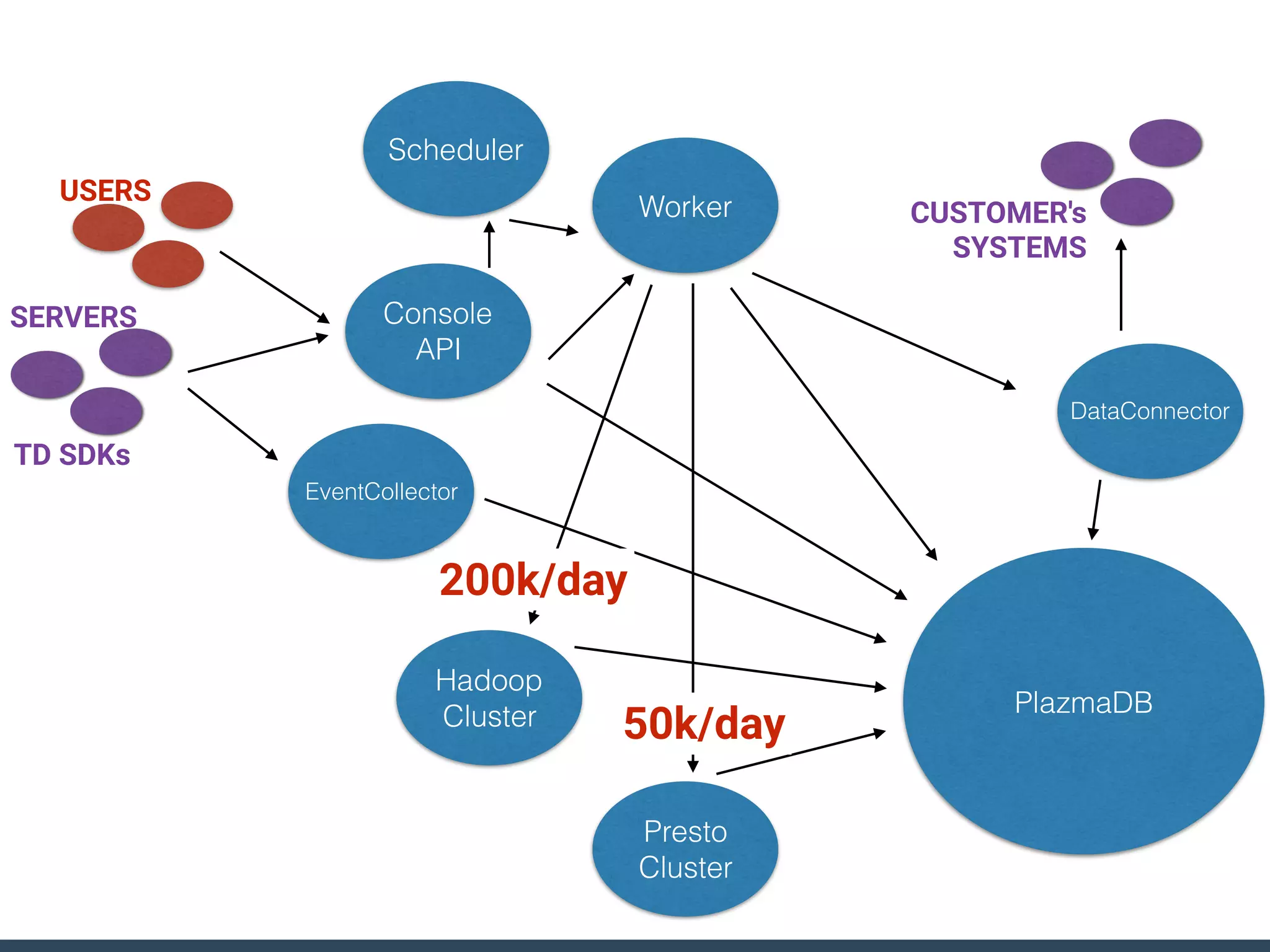
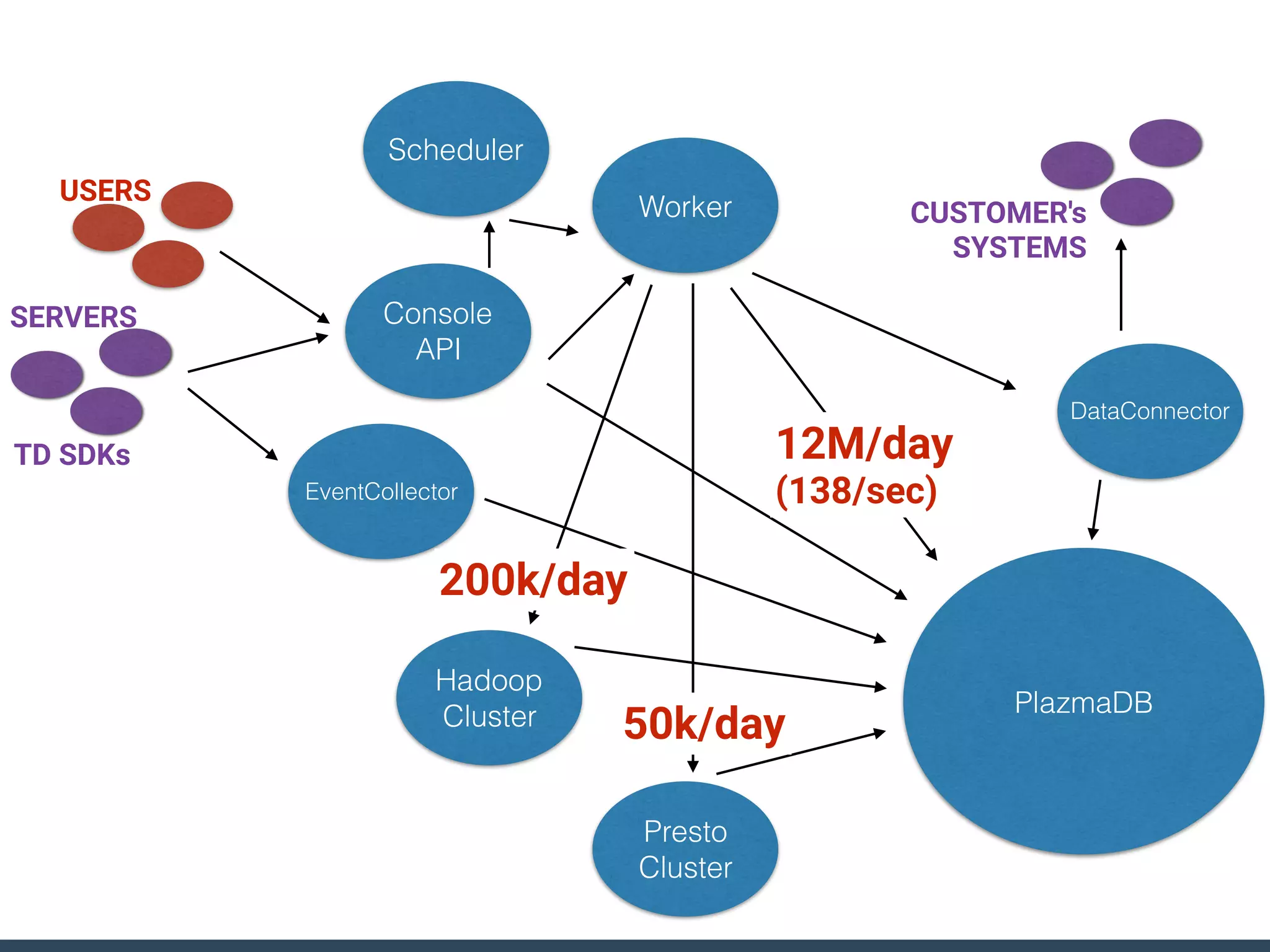



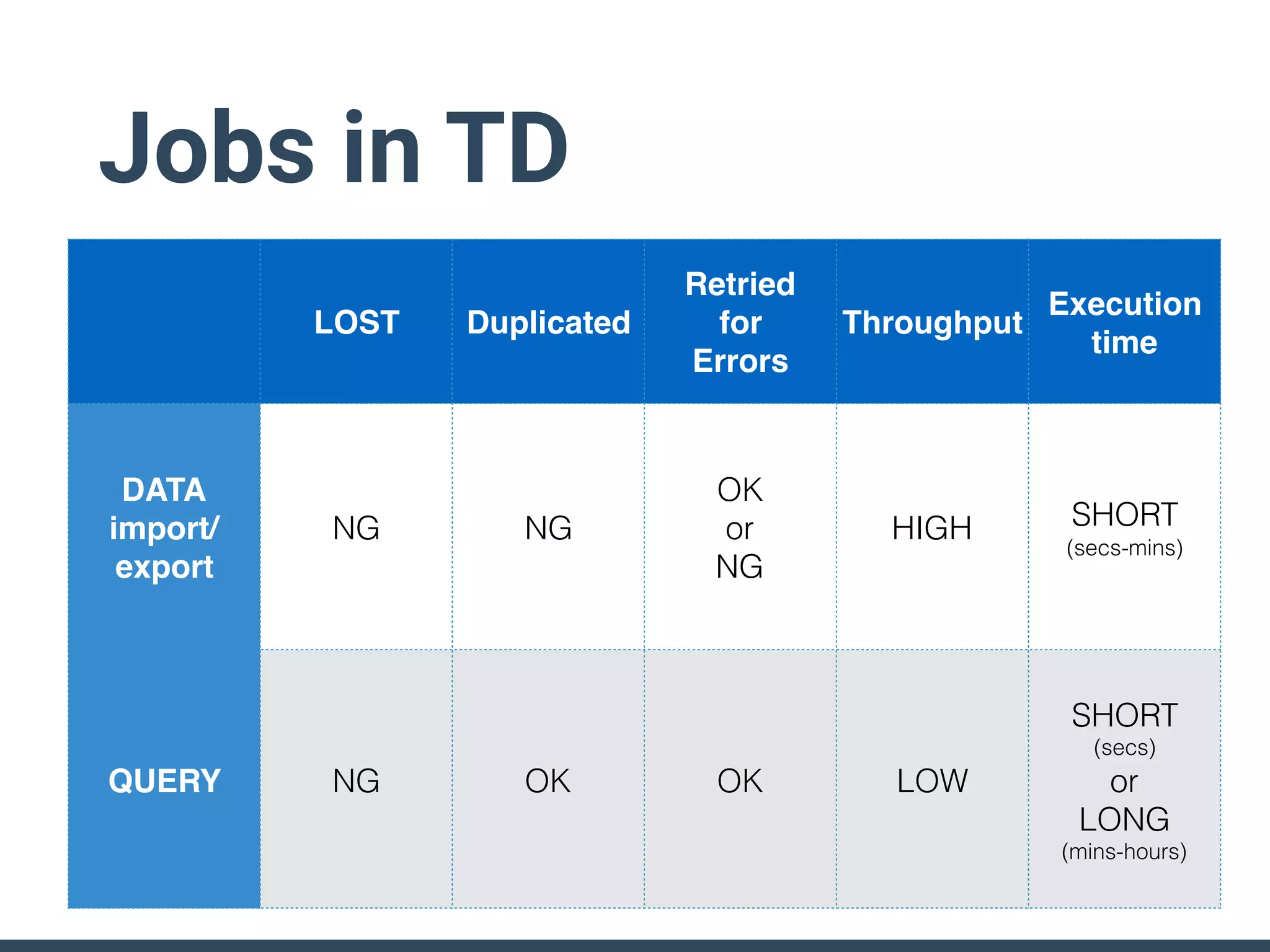

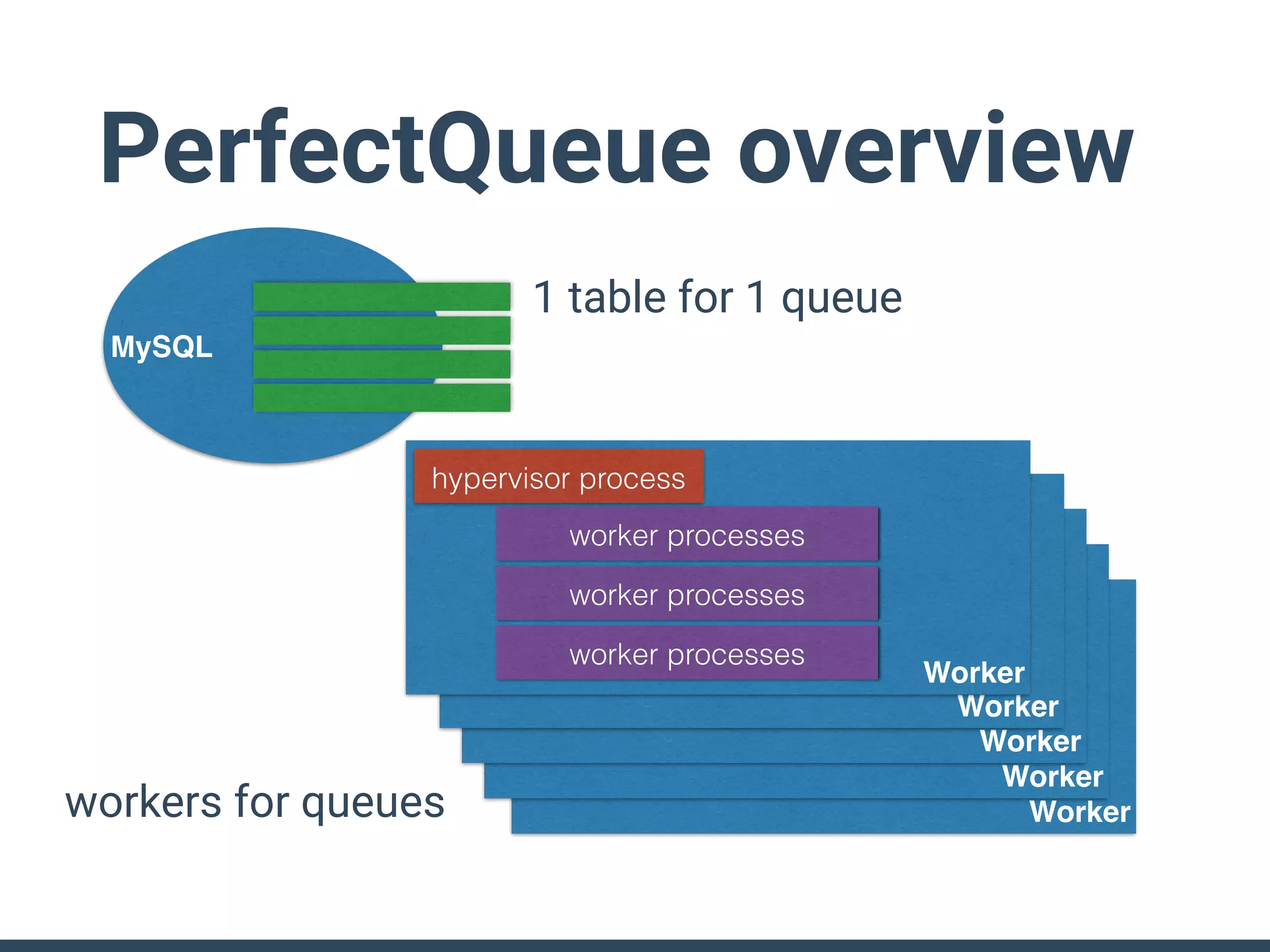




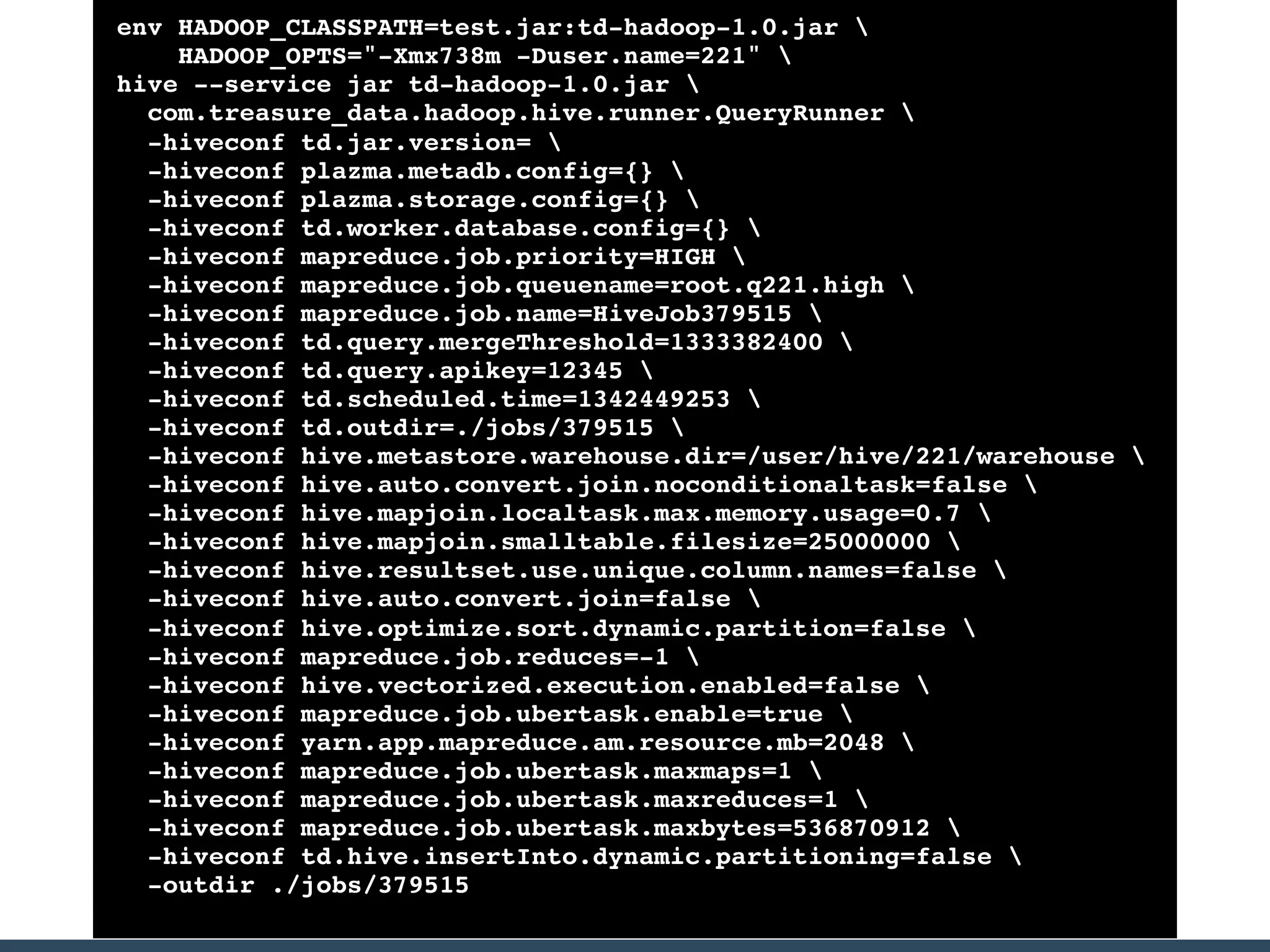

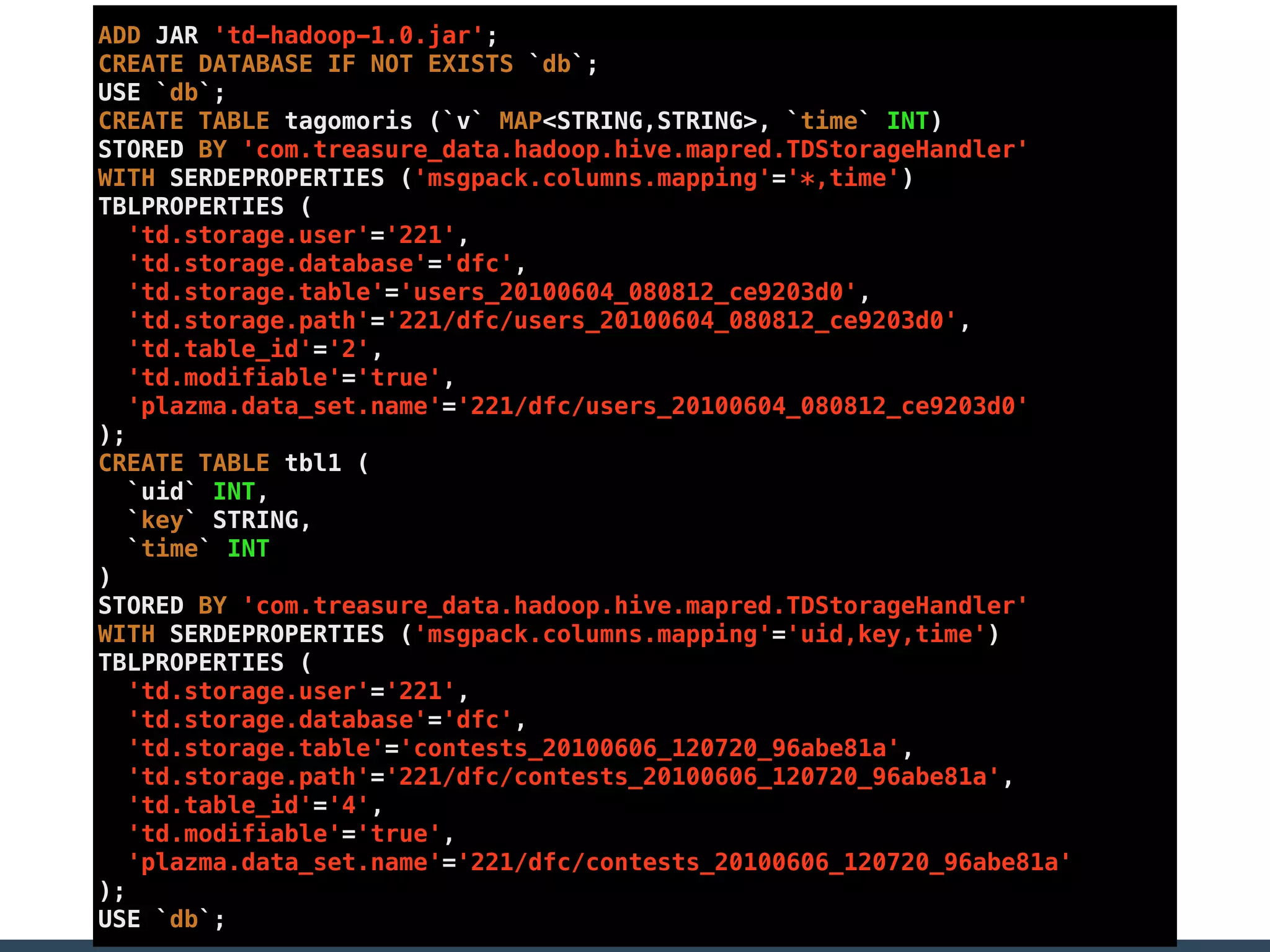
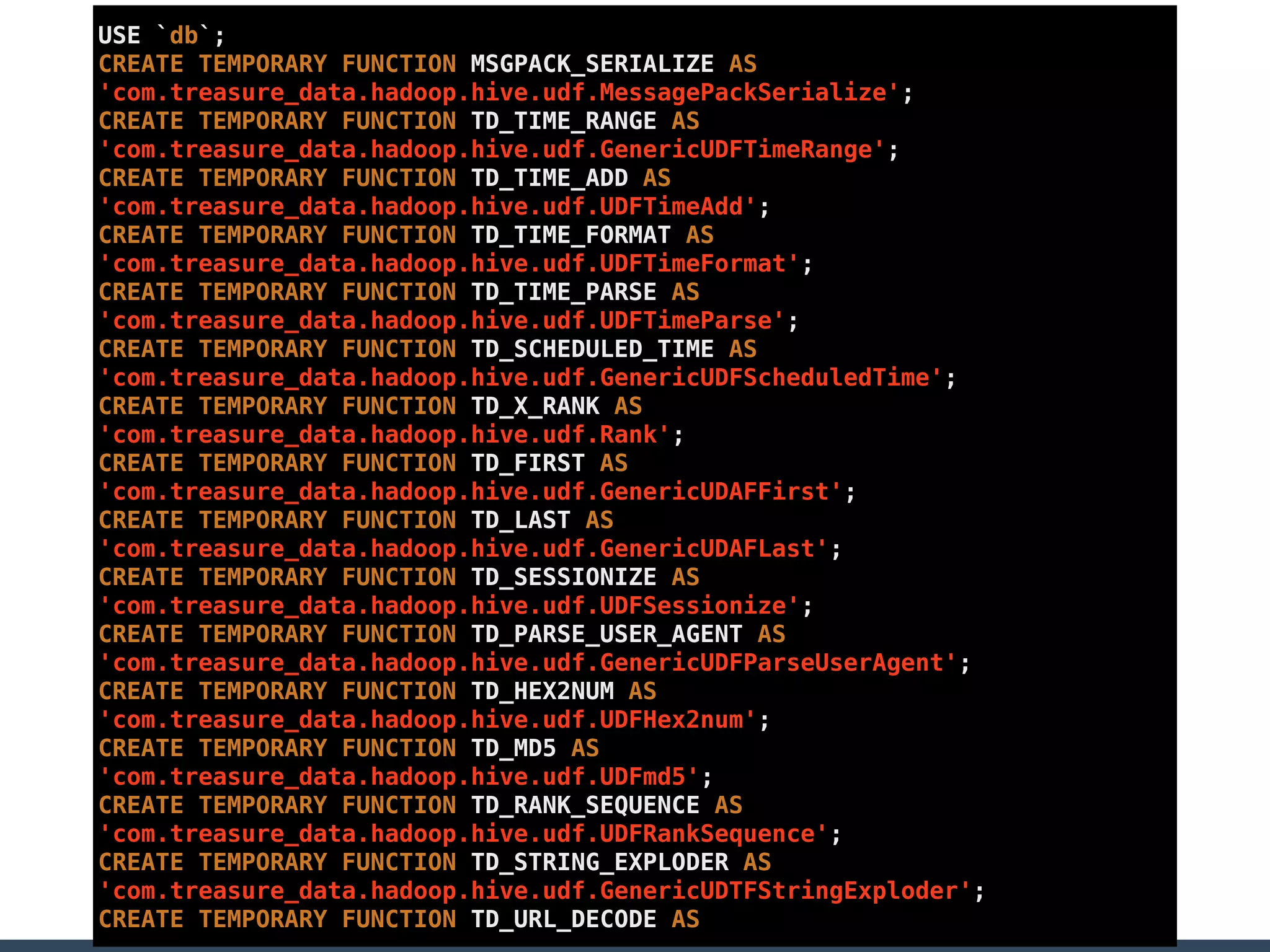

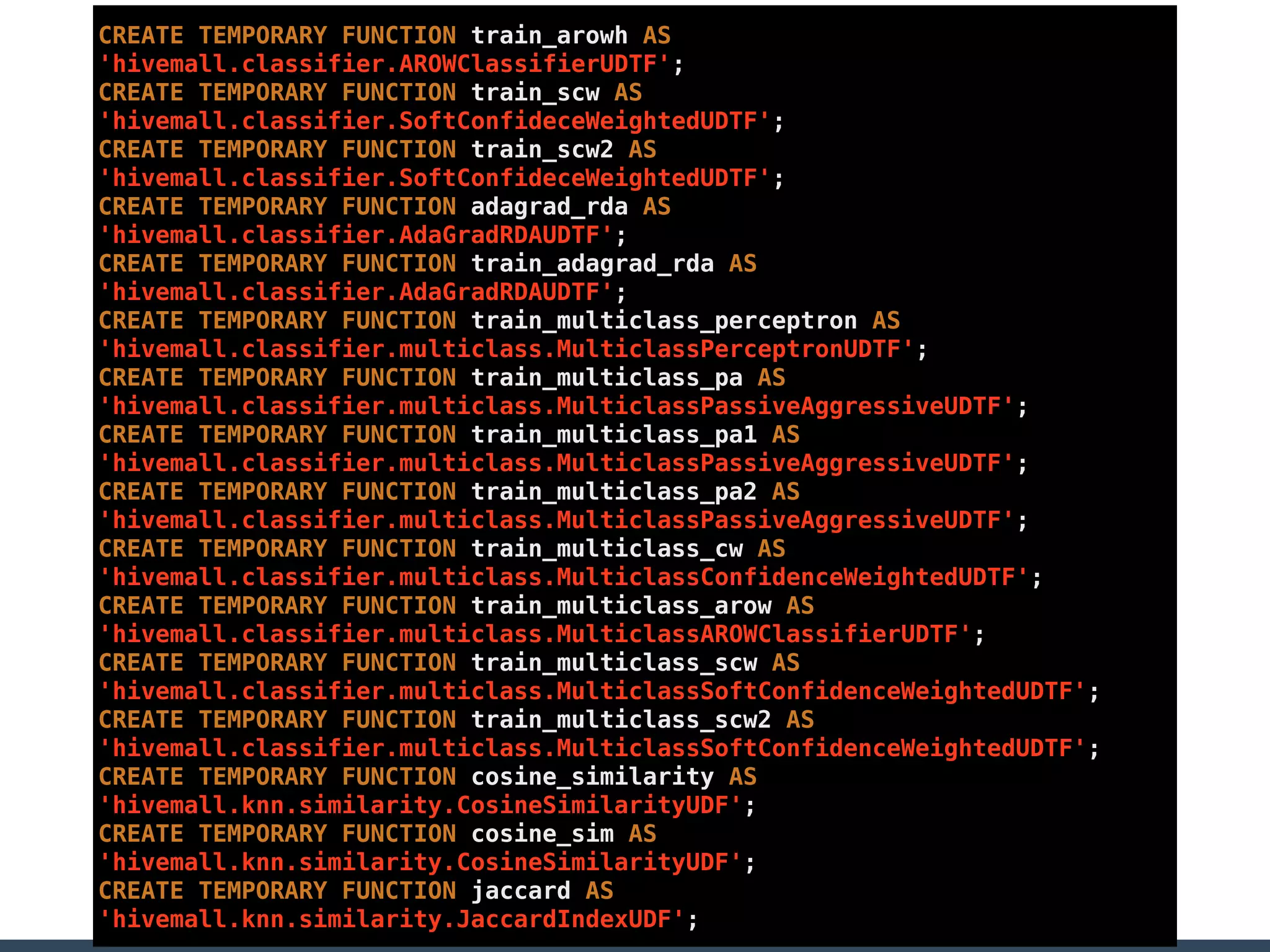
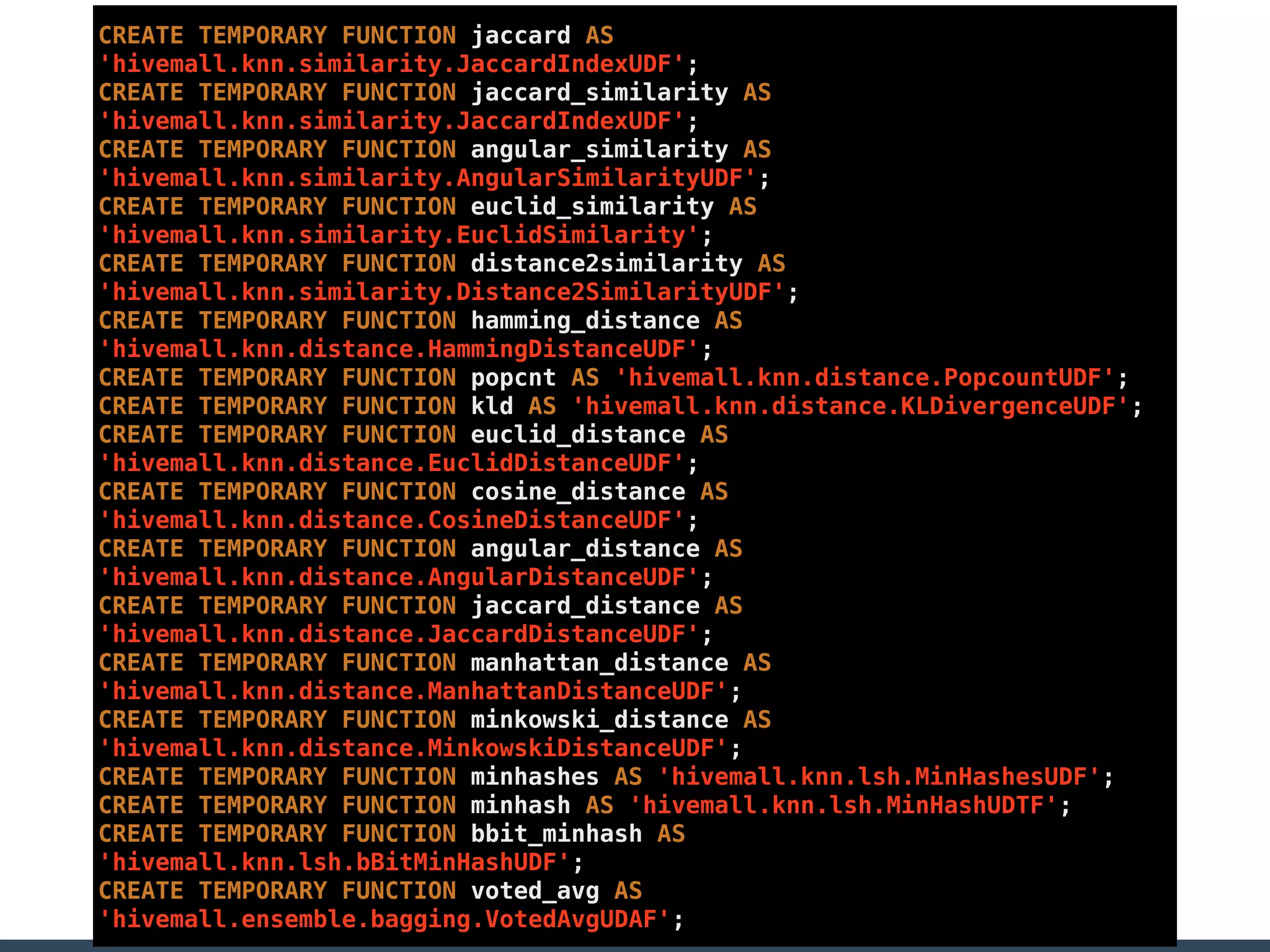
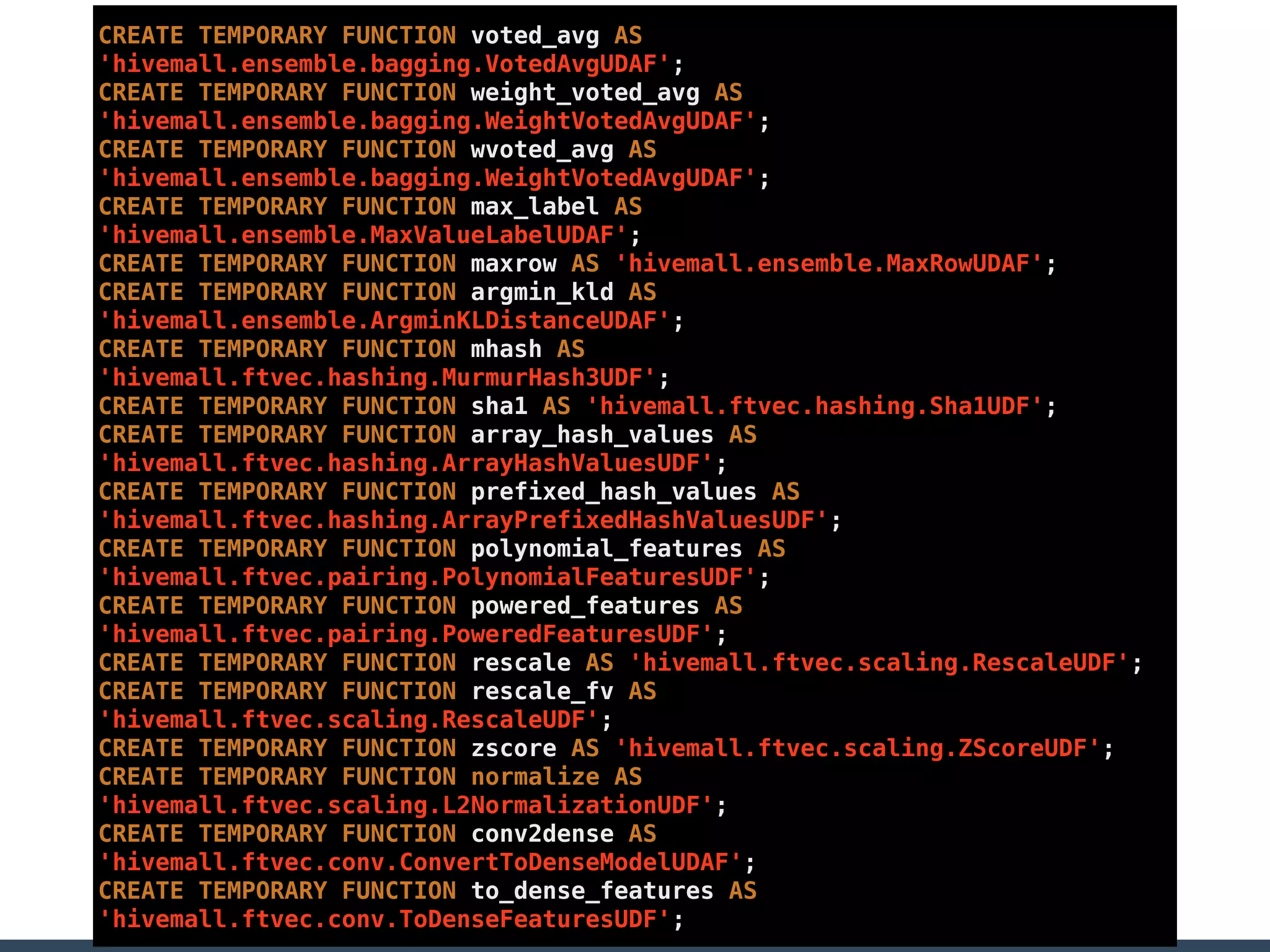
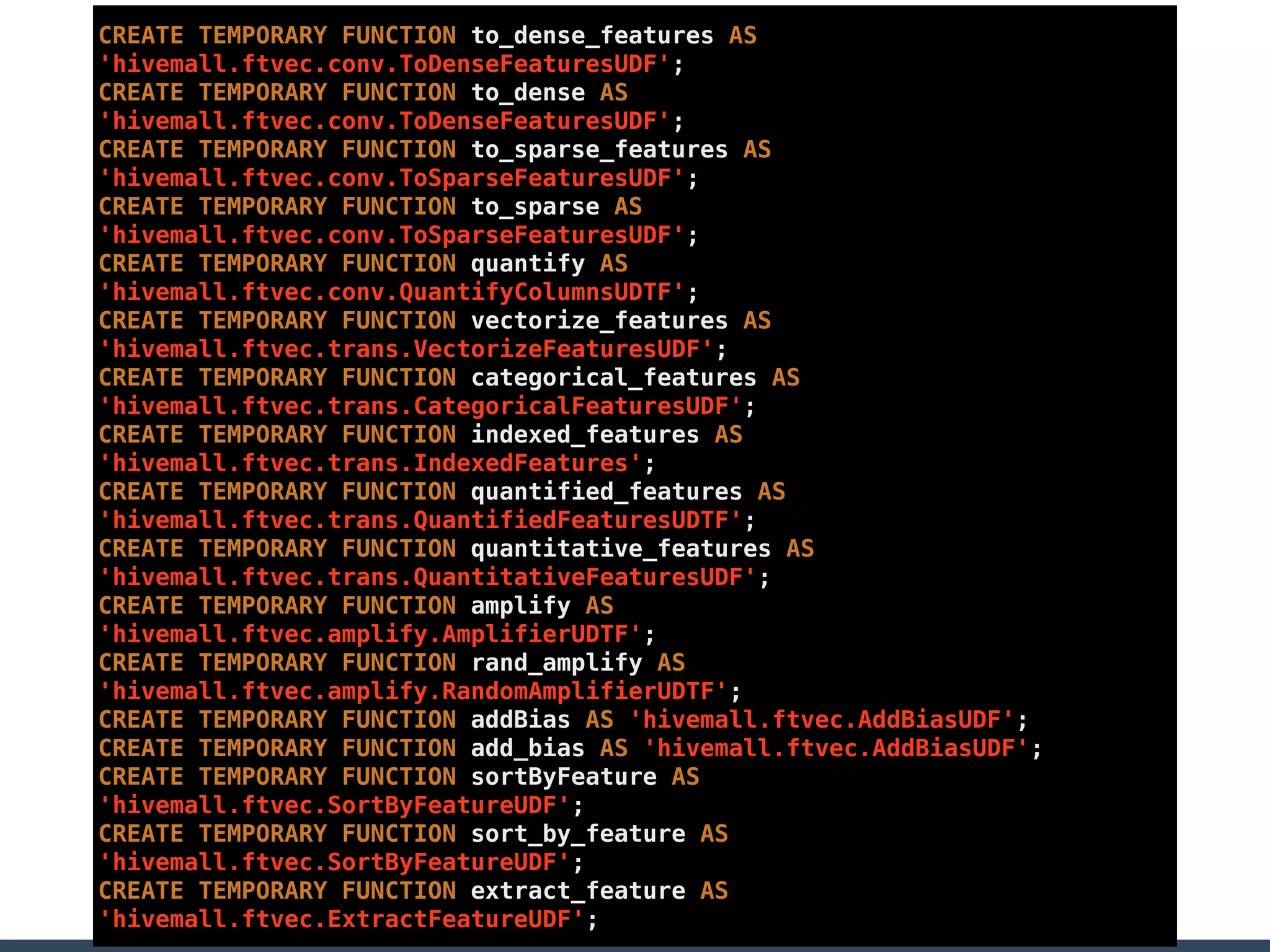
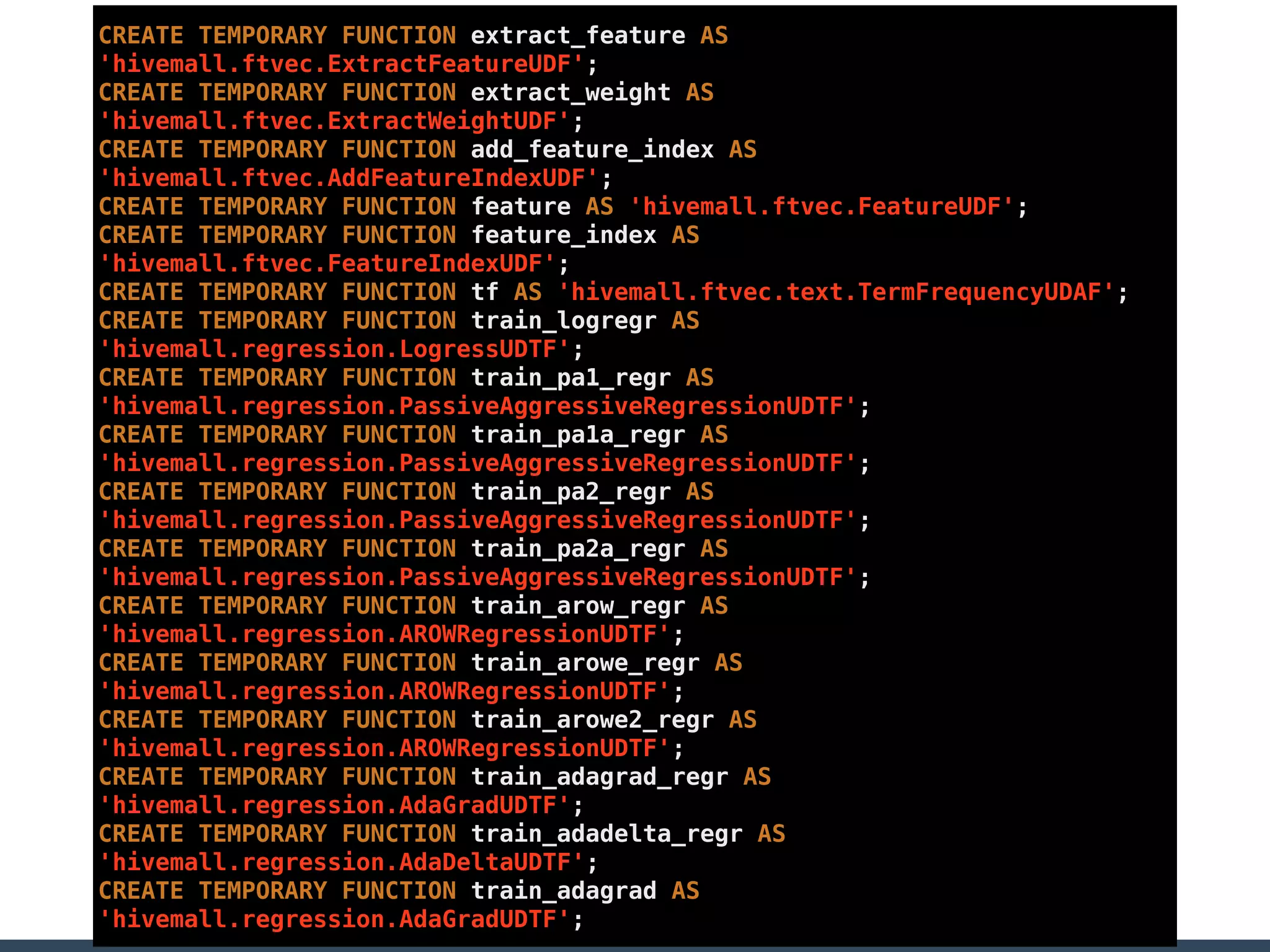
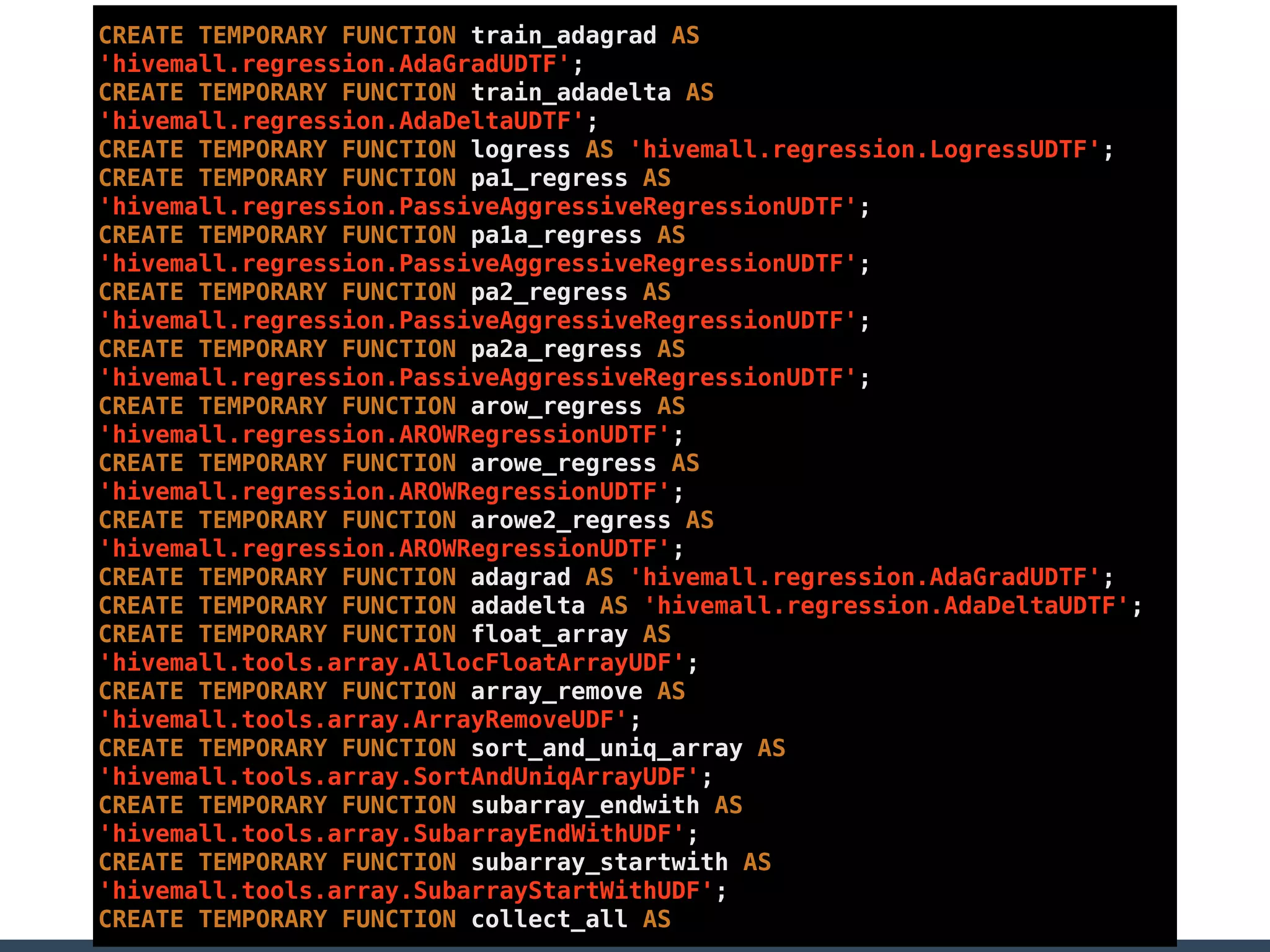
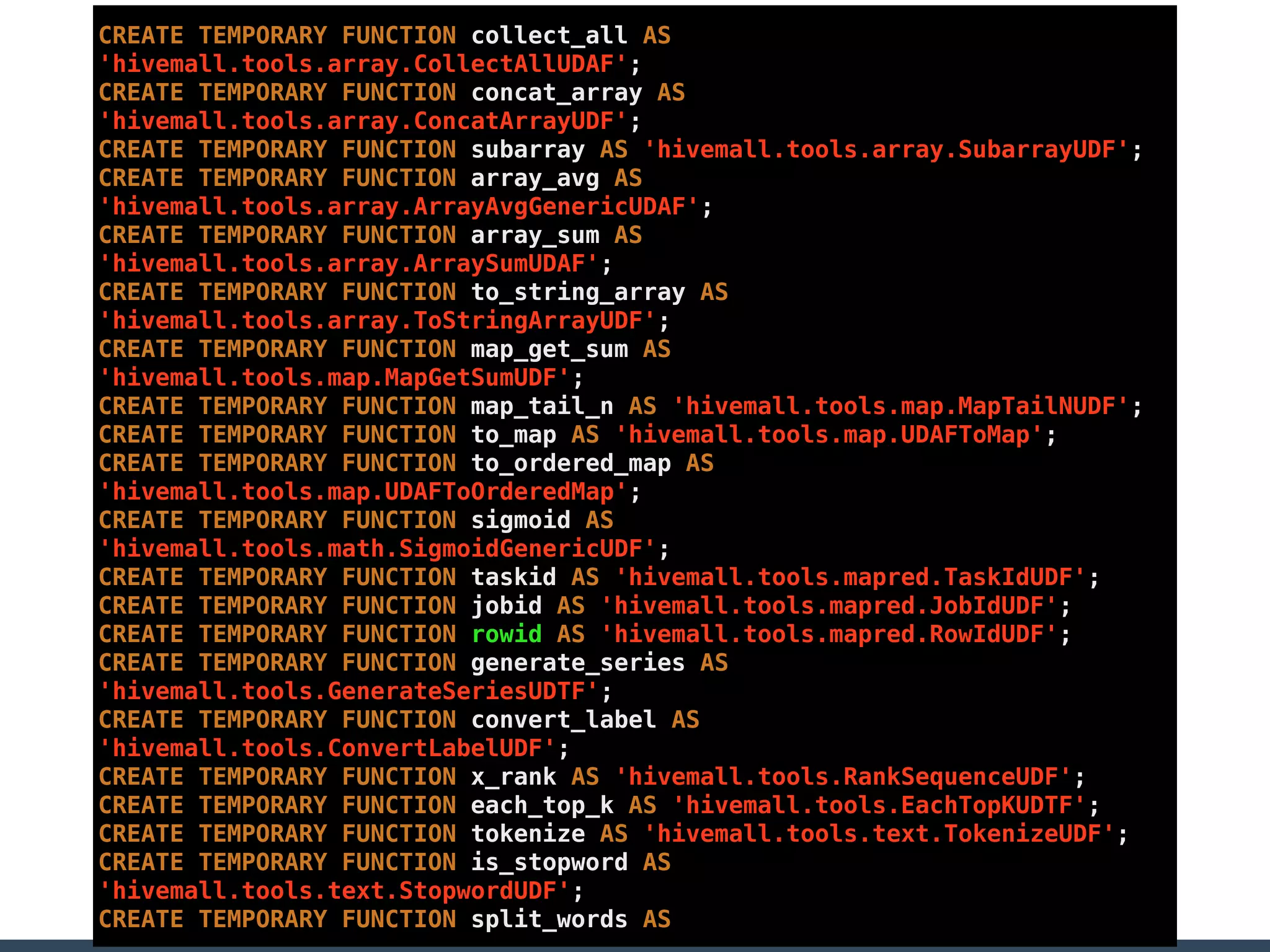

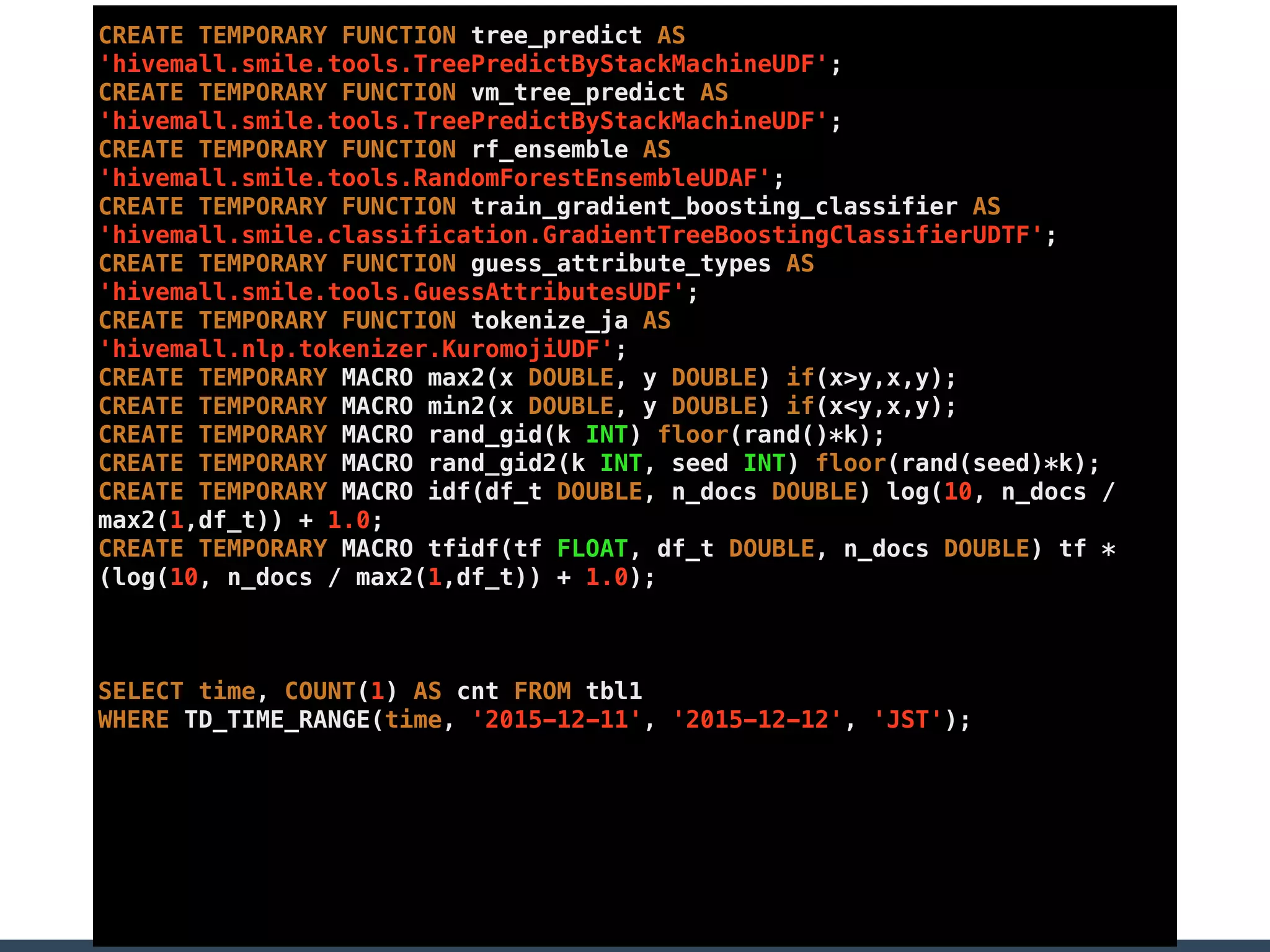







Treasure Data is a data analytics service company that makes heavy use of Ruby in its platform and services. It uses Ruby for components like Fluentd (log collection), Embulk (data loading), scheduling, and its Rails-based API and console. Java and JRuby are also used for components involving Hadoop and Presto processing. The company's architecture includes collectors that ingest data, a PlazmaDB for storage, workers that process jobs on Hadoop and Presto clusters, and schedulers that queue and schedule those jobs using technologies like PerfectSched and PerfectQueue which are written in Ruby. Hive jobs are built programmatically using Ruby to generate configurations and submit the jobs to underlying Hadoop clusters.










































































































