Download as PDF, PPTX

























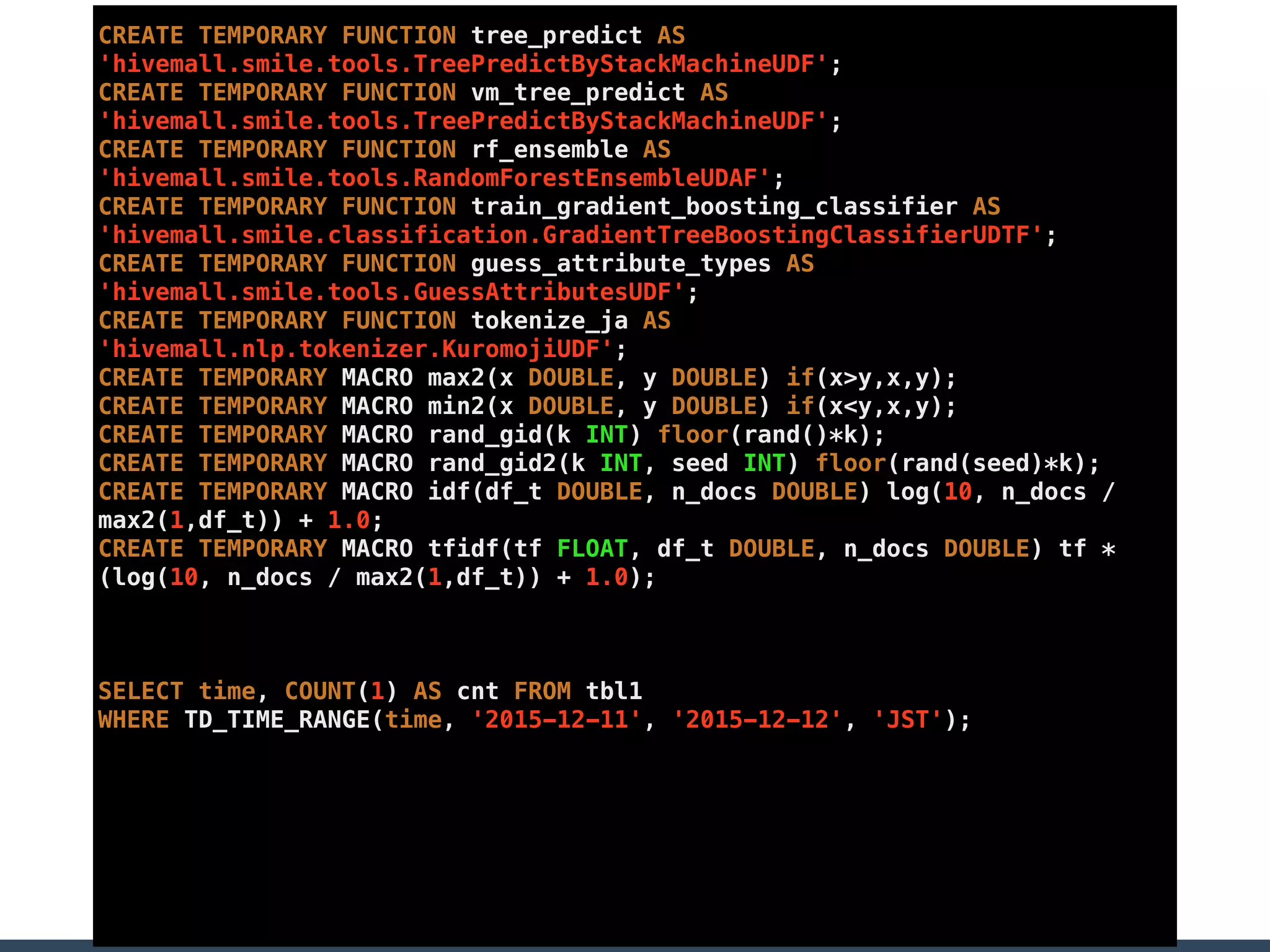








![IndexAnalyzer
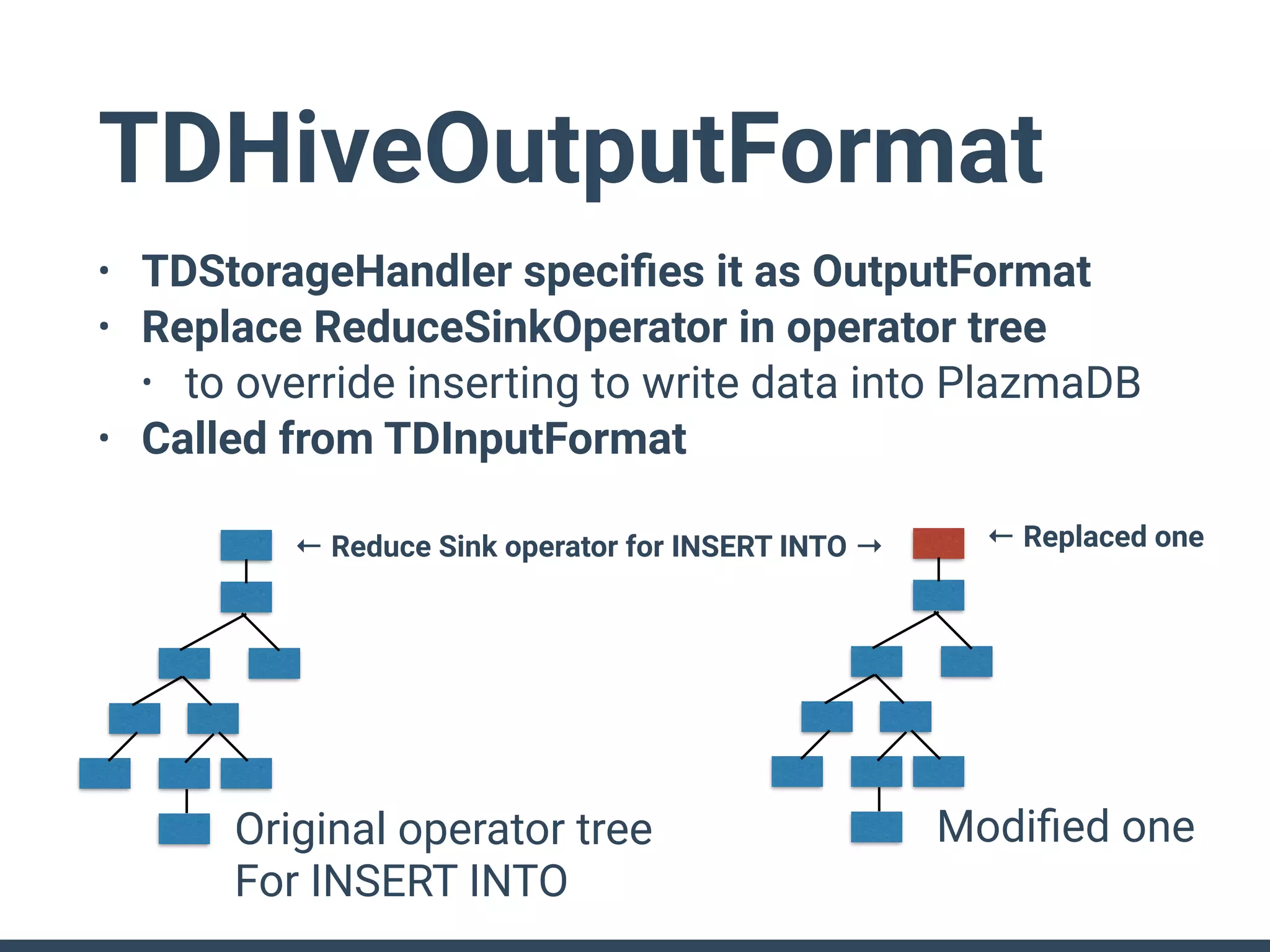
• Called from TDInputFormat
• InputFormat can do everything :-)
• Analyze operator tree
• to create time ranges for each tables
} else if (udf instanceof GenericUDFOPLessThan) {
ExprNodeDesc left = node.getChildren().get(0);
ExprNodeDesc right = node.getChildren().get(1);
if (isTimeColumn(right)) {
Long v = getLongConstant(left);
if (v != null) { // VALUE < key
return new TimeRange[] { new TimeRange(v + 1) };
}
} else if (isTimeColumn(left)) {
Long v = getLongConstant(right);
if (v != null) { // key < VALUE
return new TimeRange[] { new TimeRange(0, v - 1) };
}
}
return ALL_RANGES;
} else if (udf instanceof GenericUDFTimeRange) {
// static evaluate TIME_RANGE(time, start[, end[, timezone]])
if (node.getChildren().size() < 2 || node.getChildren().size() > 4) {
return ALL_RANGES;
}
ExprNodeDesc arg0 = node.getChildren().get(0);
ExprNodeDesc arg1 = node.getChildren().get(1);
ExprNodeDesc arg2 = null;
ExprNodeDesc arg3 = null;](https://image.slidesharecdn.com/hcj2016rejectedhiveintd-160213072920/75/Hive-dirty-beautiful-hacks-in-TD-43-2048.jpg)



![Appendix: hack NOT to sort rows
• Rows in a partitions have NOT to be sorted
• All rows in a partition should be read at same time
• There's no standard way NOT to sort rows
private static void preventFileReduceSinkOptimizationHack(Configuration conf,
SemanticAnalyzer analyzer, Table dest_tab, String fakeSortCol, int fakeSortOrder)
throws NoSuchFieldException, IllegalAccessException, HiveException
{
dest_tab.setSortCols(Arrays.asList(new Order[] {
new Order("time", 1)
}));
conf.setBoolean("hive.enforce.sorting", true);
// prevent BucketingSortingReduceSinkOptimizer optimizing out the ReduceSinkOperator.
// fake this ReduceSinkOperator is a regular operator
// so that BucketingSortingReduceSinkOptimizer.process doesn't optimize out the operator
Field field = analyzer.getClass()
.getDeclaredField("reduceSinkOperatorsAddedByEnforceBucketingSorting");
field.setAccessible(true);
List<ReduceSinkOperator> list = (List<ReduceSinkOperator>) field.get(analyzer);
list.clear();
}](https://image.slidesharecdn.com/hcj2016rejectedhiveintd-160213072920/75/Hive-dirty-beautiful-hacks-in-TD-48-2048.jpg)









The document discusses various techniques used to optimize Hive query execution and deployment in Treasure Data, including: 1) Running Hive queries through a custom QueryRunner that handles query planning, execution, and statistics reporting. 2) Using an in-memory metastore and schema-on-read from Treasure Data's columnar storage to manage schemas and tables. 3) Configuring jobs through HiveConf properties to control mappings, partitions, and storage handlers for efficient execution on Hadoop clusters.























































































