Downloaded 14 times











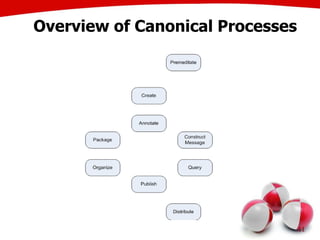

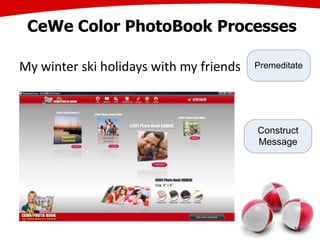

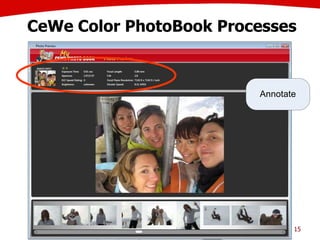
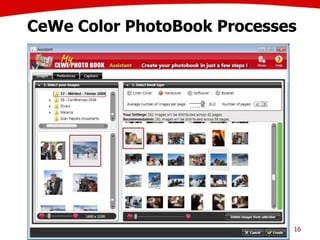
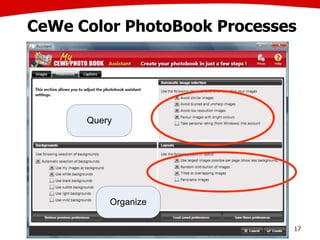

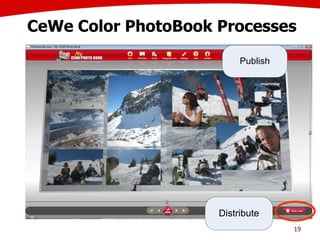
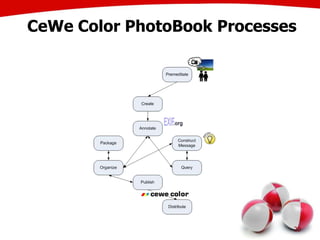
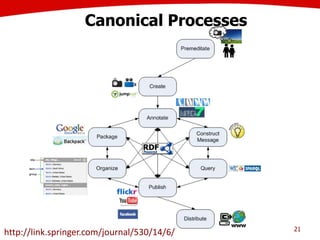












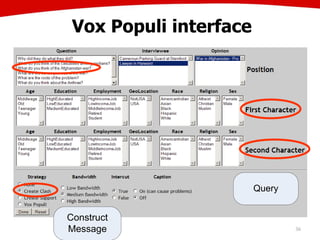
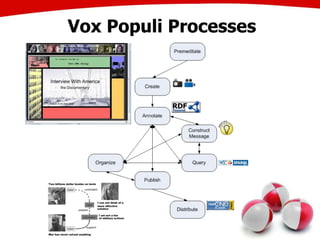











The document discusses the creation of stories using media and the importance of metadata for user interaction and multimedia applications. It emphasizes the need for mechanisms to identify and annotate media assets to enhance user experience in accessing and interpreting information. Multiple examples of application areas and processes, such as the Cewe color photobook and the Voxpopuli system for generating video documentaries, are presented to illustrate these concepts.


































































