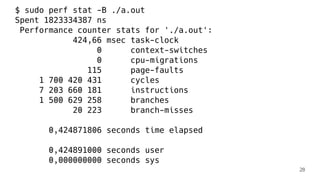
Download to read offline









![$ clang++ —O2 —Rpass=inline —c calc.cpp
calc.cpp:87:12: remark: _Z15get_first_valueii inlined into
_Z7get_resv with cost=0 (threshold=337) [—Rpass=inline]
res += get_first_value(i, 0) + get_second_value(i, 0) ;
^
calc.cpp:87:37: remark: _Z16get_second_valueii inlined into
_Z7get_resv with cost=0 (threshold=337) [—Rpass=inline]
res += get_first_value(i, 0) + get_second_value(i, 0) ;
11](https://image.slidesharecdn.com/oleynikov-191210132649/85/CoreHard-Autumn-2019-11-320.jpg)
![$ clang++ -O2 -Rpass=inline -Rpass-missed=inline -c calc.cpp
calc.cpp:76:10: remark: _Z10calc_valueii not inlined into
_Z15get_first_valueii because too costly to inline
(cost=320, threshold=225) [-Rpass-missed=inline]
return calc_value(i, branch);
^
calc.cpp:80:10: remark: _Z10calc_valueii not inlined into
_Z16get_second_valueii because too costly to inline
(cost=320, threshold=225) [-Rpass-missed=inline]
return calc_value(i, branch);
...
12](https://image.slidesharecdn.com/oleynikov-191210132649/85/CoreHard-Autumn-2019-12-320.jpg)


![$ clang++ -O2 -Rpass=inline -c calc.cpp
calc.cpp:76:10: remark: _Z10calc_valueii inlined into
_Z15get_first_valueii with cost=320 (threshold=325)
[-Rpass=inline]
return calc_value(i, branch);
^
calc.cpp:80:10: remark: _Z10calc_valueii inlined into
_Z16get_second_valueii with cost=320 (threshold=325)
[-Rpass=inline]
return calc_value(i, branch);
^
16](https://image.slidesharecdn.com/oleynikov-191210132649/85/CoreHard-Autumn-2019-16-320.jpg)
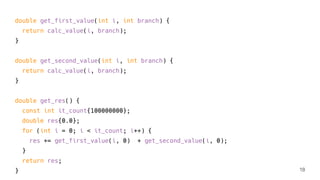

![$ clang++ -O2 -Rpass=inline -c calc.cpp
calc.cpp:89:12: remark: _Z15get_first_valuei inlined into
_Z7get_resv with cost=5 (threshold=337) [-Rpass=inline]
res += get_first_value(i) + get_second_value(i);
^
calc.cpp:89:33: remark: _Z16get_second_valuei inlined into
_Z7get_resv with cost=5 (threshold=337) [-Rpass=inline]
res += get_first_value(i) + get_second_value(i);
21](https://image.slidesharecdn.com/oleynikov-191210132649/85/CoreHard-Autumn-2019-21-320.jpg)

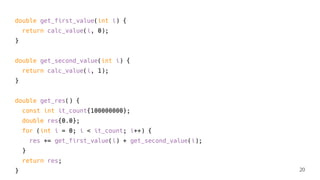
![$ clang++ -O2 -Rpass=inline -c calc.cpp
calc.cpp:78:10: remark: _Z10calc_valueii inlined into
_Z15get_first_valuei with cost=265 (threshold=325) [-
Rpass=inline]
return calc_value(i, 0);
^
calc.cpp:82:10: remark: _Z10calc_valueii inlined into
_Z16get_second_valuei with cost=255 (threshold=325) [-
Rpass=inline]
return calc_value(i, 1);
^
24](https://image.slidesharecdn.com/oleynikov-191210132649/85/CoreHard-Autumn-2019-24-320.jpg)

![$ clang++ -O2 -Rpass=inline -c calc.cpp
calc.cpp:78:10: remark: _Z10calc_valueii inlined into
_Z15get_first_valuei with cost=265 (threshold=325)
return calc_value(i, 0);
^
...
calc.cpp:89:12: remark: _Z15get_first_valuei inlined into
_Z7get_resv with cost=270 (threshold=325) [-Rpass=inline]
res += get_first_value(i) + get_second_value(i);
^
...
27](https://image.slidesharecdn.com/oleynikov-191210132649/85/CoreHard-Autumn-2019-27-320.jpg)


![$ clang++ -O2 -Rpass=inline -Rpass-missed=inline -c calc.cpp
...
calc.cpp:89:12: remark: _Z15get_first_valuei inlined into
_Z7get_resv with cost=always [-Rpass=inline]
res += get_first_value(i) + get_second_value(i);
^
...
calc.cpp:89:33: remark: _Z16get_second_valuei not inlined into
_Z7get_resv because it should never be inlined
(cost=never) [-Rpass-missed=inline]
res += get_first_value(i) + get_second_value(i);
31](https://image.slidesharecdn.com/oleynikov-191210132649/85/CoreHard-Autumn-2019-31-320.jpg)





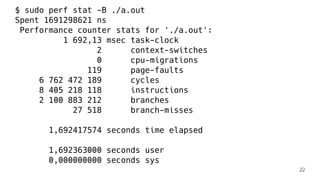
![IR перед оптимизацией
%1:
%2 = icmp sgt i32 %0, 0
br i1 %2, label %3, label %6
T F
%3:
br label %8
%6:
%7 = phi double [ 0.000000e+00, %1 ], [ %5, %4 ]
ret double %7
%8:
%9 = phi i32 [ %14, %8 ], [ 0, %3 ]
%10 = phi double [ %13, %8 ], [ 0.000000e+00, %3 ]
%11 = sitofp i32 %9 to double
%12 = tail call double @sin(double %11)
%13 = fadd double %10, %12
%14 = add nuw nsw i32 %9, 1
%15 = icmp eq i32 %14, %0
br i1 %15, label %4, label %8
T F
%4:
%5 = phi double [ %13, %8 ]
br label %6
37](https://image.slidesharecdn.com/oleynikov-191210132649/85/CoreHard-Autumn-2019-37-320.jpg)
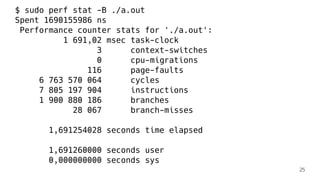
![IR после оптимизации
%1:
%2 = icmp sgt i32 %0, 0
br i1 %2, label %3, label %29
T F
%3:
%4 = add i32 %0, -1
%5 = and i32 %0, 3
%6 = icmp ult i32 %4, 3
br i1 %6, label %10, label %7
T F
%29:
%30 = phi double [ 0.000000e+00, %1 ], [ %28, %27 ]
ret double %30
%10:
%11 = phi double [ undef, %3 ], [ %49, %9 ]
%12 = phi i32 [ 0, %3 ], [ %50, %9 ]
%13 = phi double [ 0.000000e+00, %3 ], [ %49, %9 ]
%14 = icmp eq i32 %5, 0
br i1 %14, label %27, label %15
T F
%7:
%8 = sub i32 %0, %5
br label %31
%27:
%28 = phi double [ %11, %10 ], [ %22, %26 ]
br label %29
%15:
br label %16
%31:
%32 = phi i32 [ 0, %7 ], [ %50, %31 ]
%33 = phi double [ 0.000000e+00, %7 ], [ %49, %31 ]
%34 = phi i32 [ %8, %7 ], [ %51, %31 ]
%35 = sitofp i32 %32 to double
%36 = tail call double @sin(double %35)
%37 = fadd double %33, %36
%38 = or i32 %32, 1
%39 = sitofp i32 %38 to double
%40 = tail call double @sin(double %39)
%41 = fadd double %37, %40
%42 = or i32 %32, 2
%43 = sitofp i32 %42 to double
%44 = tail call double @sin(double %43)
%45 = fadd double %41, %44
%46 = or i32 %32, 3
%47 = sitofp i32 %46 to double
%48 = tail call double @sin(double %47)
%49 = fadd double %45, %48
%50 = add nuw nsw i32 %32, 4
%51 = add i32 %34, -4
%52 = icmp eq i32 %51, 0
br i1 %52, label %9, label %31
T F
%9:
br label %10
%16:
%17 = phi i32 [ %23, %16 ], [ %12, %15 ]
%18 = phi double [ %22, %16 ], [ %13, %15 ]
%19 = phi i32 [ %24, %16 ], [ %5, %15 ]
%20 = sitofp i32 %17 to double
%21 = tail call double @sin(double %20)
%22 = fadd double %18, %21
%23 = add nuw nsw i32 %17, 1
%24 = add i32 %19, -1
%25 = icmp eq i32 %24, 0
br i1 %25, label %26, label %16, !llvm.loop !0
T F
%26:
br label %27
38](https://image.slidesharecdn.com/oleynikov-191210132649/85/CoreHard-Autumn-2019-38-320.jpg)




![%1:
%2 = icmp sgt i32 %0, 0
br i1 %2, label %3, label %27
T F
%3:
%4 = add i32 %0, -1
%5 = urem i32 %4, 12
%6 = add nuw nsw i32 %5, 1
%7 = urem i32 %6, 12
%8 = icmp ult i32 %4, 11
br i1 %8, label %11, label %9
T F
%27:
%28 = phi double [ 0.000000e+00, %1 ], [ %12, %11 ], [ %23, %17 ]
ret double %28
%11:
%12 = phi double [ undef, %3 ], [ %79, %29 ]
%13 = phi i32 [ 0, %3 ], [ %80, %29 ]
%14 = phi double [ 0.000000e+00, %3 ], [ %79, %29 ]
%15 = icmp eq i32 %7, 0
br i1 %15, label %27, label %16
T F
%9:
%10 = sub i32 %0, %7
br label %29
%16:
br label %17
%29:
%30 = phi i32 [ 0, %9 ], [ %80, %29 ]
%31 = phi double [ 0.000000e+00, %9 ], [ %79, %29 ]
%32 = phi i32 [ %10, %9 ], [ %81, %29 ]
%33 = sitofp i32 %30 to double
%34 = tail call double @sin(double %33) #2
%35 = fadd double %31, %34
%36 = or i32 %30, 1
%37 = sitofp i32 %36 to double
%38 = tail call double @sin(double %37) #2
%39 = fadd double %35, %38
%40 = or i32 %30, 2
%41 = sitofp i32 %40 to double
%42 = tail call double @sin(double %41) #2
%43 = fadd double %39, %42
%44 = or i32 %30, 3
%45 = sitofp i32 %44 to double
%46 = tail call double @sin(double %45) #2
%47 = fadd double %43, %46
%48 = add nuw nsw i32 %30, 4
%49 = sitofp i32 %48 to double
%50 = tail call double @sin(double %49) #2
%51 = fadd double %47, %50
%52 = add nuw nsw i32 %30, 5
%53 = sitofp i32 %52 to double
%54 = tail call double @sin(double %53) #2
%55 = fadd double %51, %54
%56 = add nuw nsw i32 %30, 6
%57 = sitofp i32 %56 to double
%58 = tail call double @sin(double %57) #2
%59 = fadd double %55, %58
%60 = add nuw nsw i32 %30, 7
%61 = sitofp i32 %60 to double
%62 = tail call double @sin(double %61) #2
%63 = fadd double %59, %62
%64 = add nuw nsw i32 %30, 8
%65 = sitofp i32 %64 to double
%66 = tail call double @sin(double %65) #2
%67 = fadd double %63, %66
%68 = add nuw nsw i32 %30, 9
%69 = sitofp i32 %68 to double
%70 = tail call double @sin(double %69) #2
%71 = fadd double %67, %70
%72 = add nuw nsw i32 %30, 10
%73 = sitofp i32 %72 to double
%74 = tail call double @sin(double %73) #2
%75 = fadd double %71, %74
%76 = add nuw nsw i32 %30, 11
%77 = sitofp i32 %76 to double
%78 = tail call double @sin(double %77) #2
%79 = fadd double %75, %78
%80 = add nuw nsw i32 %30, 12
%81 = add i32 %32, -12
%82 = icmp eq i32 %81, 0
br i1 %82, label %11, label %29, !llvm.loop !4
T F
%17:
%18 = phi i32 [ %24, %17 ], [ %13, %16 ]
%19 = phi double [ %23, %17 ], [ %14, %16 ]
%20 = phi i32 [ %25, %17 ], [ %7, %16 ]
%21 = sitofp i32 %18 to double
%22 = tail call double @sin(double %21) #2
%23 = fadd double %19, %22
%24 = add nuw nsw i32 %18, 1
%25 = add i32 %20, -1
%26 = icmp eq i32 %25, 0
br i1 %26, label %27, label %17, !llvm.loop !2
T F
43](https://image.slidesharecdn.com/oleynikov-191210132649/85/CoreHard-Autumn-2019-43-320.jpg)
























Как правило, можно положиться на то, что компилятор оптимизирует результирующий бинарный файл так, чтобы она работала максимально быстро. Но компилятор не знает на каких данных и на каком железе программа будет запущена. Плюс хотелось бы, чтобы компиляция занимала приемлемое время. Из-за этого результат может оказаться субоптимальным. Предлагаю на примерах для LLVM посмотреть как можно подсказать компилятору как оптимизировать программу и сделать результат лучше или хуже.

![[C++ Korea] Effective Modern C++ Study, Item 27, 29 - 30](https://cdn.slidesharecdn.com/ss_thumbnails/ckoreaeffectivemoderncstudy-item2729-30-150405051614-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)
























![C - Pattern - Code - [Future Programming]](https://cdn.slidesharecdn.com/ss_thumbnails/c-pattern-code-futureprogramming-140706034022-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)



















