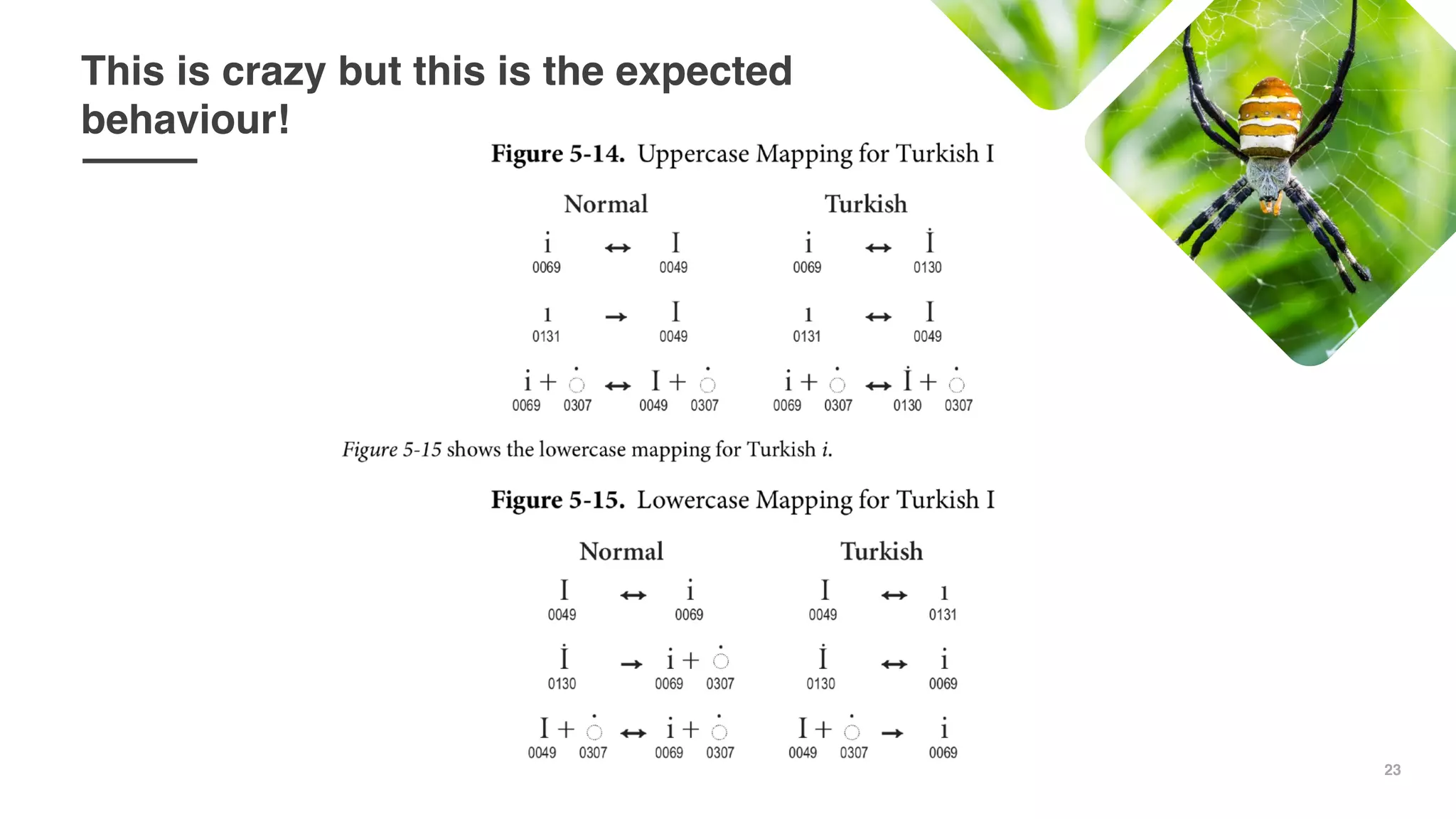
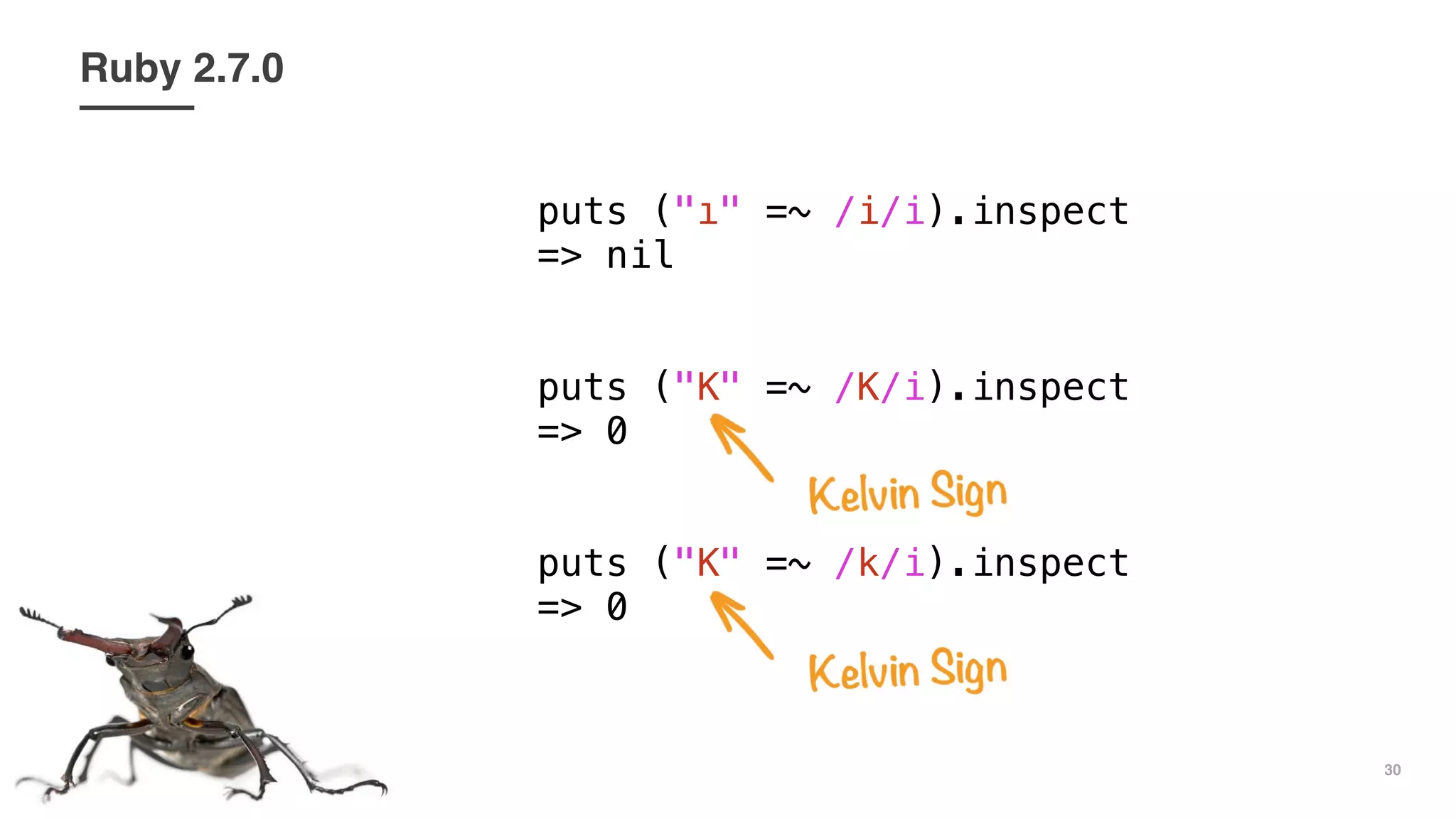
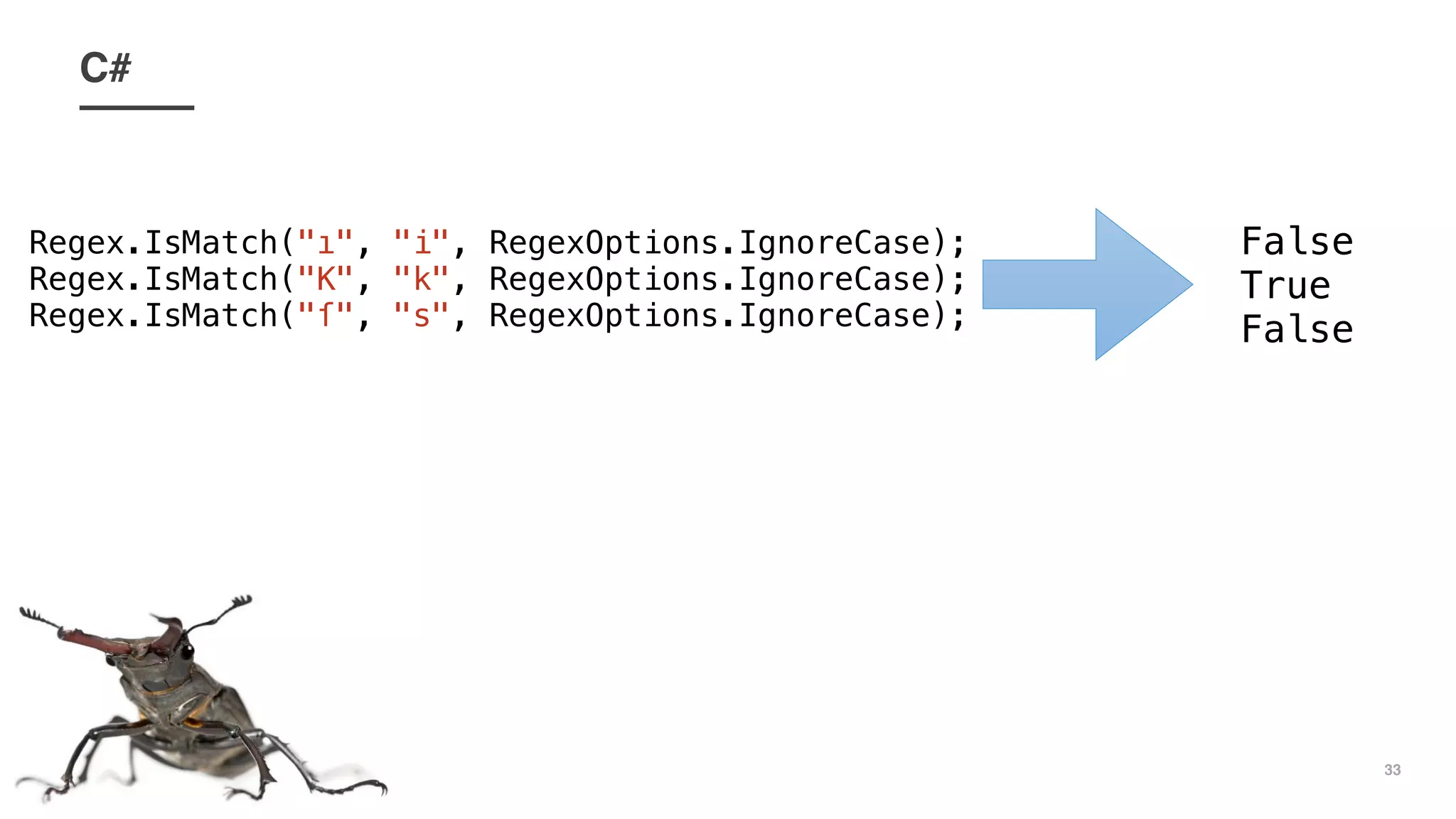
This document discusses issues with case-insensitive matching and regular expressions when Unicode characters are involved. It shows examples in multiple programming languages where case-insensitive matching fails to match strings containing Unicode characters like 'ı' and the lowercase ASCII character they resemble, like failing to match 'ı' and 'i'. It recommends being careful of assumptions when case-insensitive matching, and considering Unicode characters, as computers can behave unexpectedly with details like character casing and case-insensitive matching.













![14
func handler(w http.ResponseWriter, r *http.Request) {
filename := path.Clean(r.URL.Query()["filename"][0])
fd, err := os.Open(filename)
defer fd.Close()
if err != nil {
http.Error(w, "File not found.", 404)
return
}
io.Copy(w, fd)
}
func main() {
http.HandleFunc("/", handler)
log.Fatal(http.ListenAndServe(":8080", nil))
}](https://image.slidesharecdn.com/codethatgetsyoupwnsd-200411053251/75/Code-that-gets-you-pwn-s-d-14-2048.jpg)




![20
const express = require('express')
const app = express()
var allowedDomains = ['EXAMPLE.ORG', 'GMAIL.COM',
'GOOGLE.COM'];
function fetchContent(domain) {
…
}
app.get('/fetch', (req, res) => {
if (allowedDomains.includes(req.query.domain.toUpperCase())) {
return res.send(fetchContent(req.query.domain))
} else {
res.status(403)
return res.send("ACCESS DENIED")
}
});](https://image.slidesharecdn.com/codethatgetsyoupwnsd-200411053251/75/Code-that-gets-you-pwn-s-d-20-2048.jpg)










































![Diving into HHVM Extensions (php[tek] 2016)](https://cdn.slidesharecdn.com/ss_thumbnails/160525-divingintohhvmextensionsphptek2016-16x10-160525201430-thumbnail.jpg?width=640&height=640&fit=bounds)














![[CB16] Esoteric Web Application Vulnerabilities by Andrés Riancho](https://cdn.slidesharecdn.com/ss_thumbnails/cb16rianchoen-161109050650-thumbnail.jpg?width=640&height=640&fit=bounds)


















![Number_Guessing_Game_Dsbsbssbzboc[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/numberguessinggamedoc1-251206215042-a076fc05-thumbnail.jpg?width=640&height=640&fit=bounds)









