Download to read offline
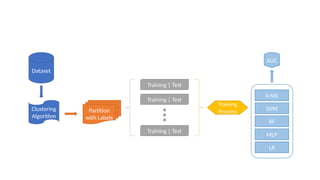
The document discusses a dataset clustering algorithm and its partitioning approach using labeled training and test data. It compares various machine learning models including k-nearest neighbors (k-nn), support vector machines (SVM), random forests (RF), multilayer perceptrons (MLP), and logistic regression (LR) in terms of their performance metrics such as AUC. This highlights the effectiveness of different algorithms in the training process.















































