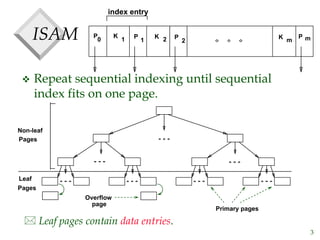
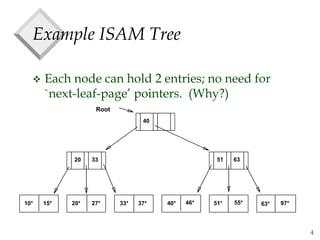
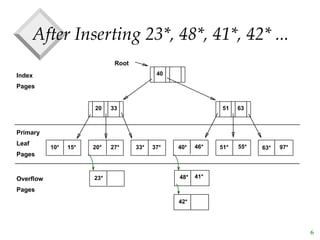
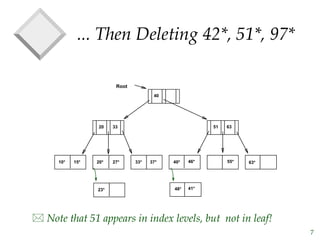
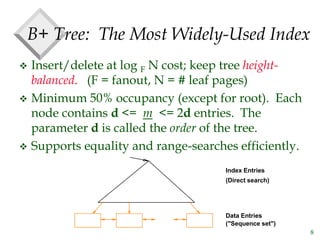
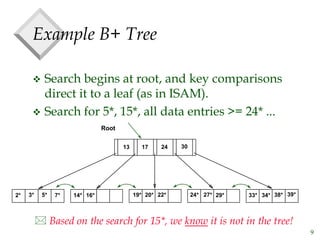
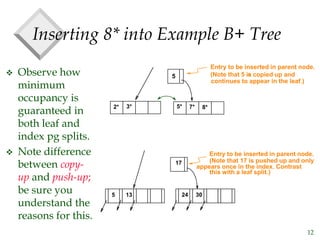
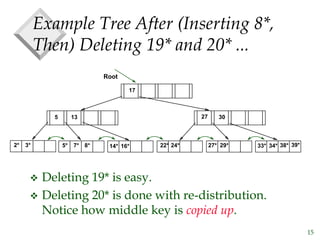
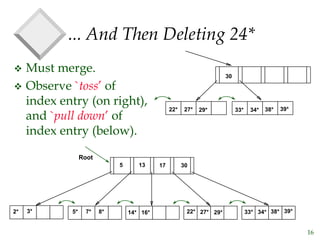
The document discusses tree-structured indexing techniques, specifically focusing on ISAM and B+ trees, which support both range and equality searches. ISAM is a static structure, while B+ trees are dynamic, allowing for efficient insertions and deletions with logarithmic cost, and maintaining balance. B+ trees are preferred in database management systems due to their high fanout and adaptability for growth.



























![[Www.pkbulk.blogspot.com]file and indexing](https://cdn.slidesharecdn.com/ss_thumbnails/www-pkbul-blogspot-comfileandindexing-130615034648-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)


![Presentation on b trees [autosaved]](https://cdn.slidesharecdn.com/ss_thumbnails/presentationonbtreesautosaved-210209155822-thumbnail.jpg?width=640&height=640&fit=bounds)


























