Downloaded 45 times














![X= {0,1} , set of possible opinions. nX → The number of rankings which give the opinion x belongs to X
Total number of ranking → N. 0<=alpha<=0.5, 0<=beta<=1 .
Ranking k has disagreed with the alpha-majority iff the following conditions are satisfied:
1. n0+n1 >= ceil ( beta * N) ……. eq (1)
2. nx(k) < alpha * (n0 + n1 ) …….. eq (2)
Weight assignment rule:
Wl = 1 - delta / |S|C2 …...eq (3)
Wl → fraction of item pairs for which an input ranking Rl agrees with alpha majority.
where , delta = 0, if Rl does not disagree with alpha-majority for (i,j)
= 1, if Rl disagrees with alpha-majority for (i,j)
= 0.5, if both i and j are not ranked by Rl
|S| → the number of distinct items that appear in the input rankings.
The opinion of a ranker is incorrect if it fails to agree with a fraction alpha of rankers that rank both
the items. [Alpha Majority]](https://image.slidesharecdn.com/irprojectpresentation-170418115512/85/Building-a-Meta-search-Engine-18-320.jpg)


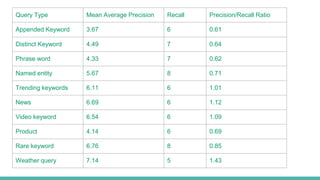
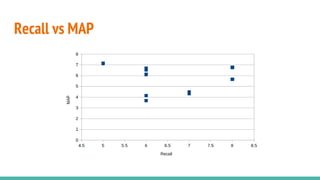

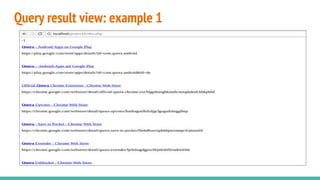


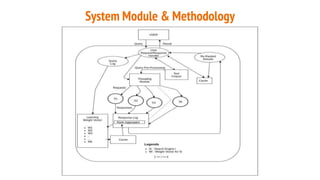
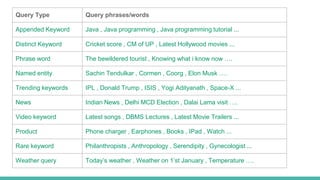
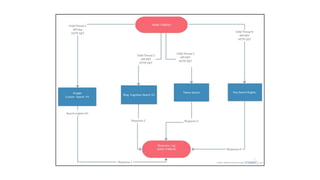
The document describes building a meta-search engine that aggregates results from multiple search engines. It discusses the infrastructure including querying different search engines simultaneously, preprocessing queries, caching results, and using multithreading. It also covers re-ranking and aggregating results using methods like alpha-majority and analyzing query logs and system performance. Evaluation shows highest mean average precision for queries related to news, trending topics, and video keywords.




















![[000622]](https://cdn.slidesharecdn.com/ss_thumbnails/000622-130202231406-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)






























