bots vs users classification using XGBOOST algorithm
1.
Tribhuvan University Instituteof Science and Technology
Seminar Report
On
“Detection of Bot User Profiles Using XGBoost”
Submitted to
Central Department of Computer Science and Information Technology
Tribhuvan University, Kirtipur
Kathmandu, Nepal
In the partial fulfilment of the requirement for Master’s Degree in Masters in
Information Technology (MIT) Second Semester
Submitted by
Kamal Thapa
Roll No.8025010
April, 2025
2.
ii
Tribhuvan University Instituteof Science and Technology
SUPERVISOR’S RECOMMENDATION
I hereby recommend that the seminar report titled “Detection of Bot User Profiles Using
XGBoost”, prepared by Kamal Thapa under my supervision, be submitted for evaluation as
partial fulfillment of the requirements for the Master’s Degree in Information Technology
(MIT).
Supervisor
Asst. Professor Mr. Dhiraj Kedar Pandey
Central Department of Computer Science and Technology
Kirtipur, Tribhuvan University
3.
iii
CERTIFICATE OF APPROVAL
Theundersigned hereby confirm that they have reviewed, approved, and accepted the seminar
work titled “Detection of Bot User Profiles Using XGBoost” submitted by Kamal Thapa,
as a partial requirement for the Master’s Degree in Information Technology (MIT).
Evaluation Committee
Asst. Prof. Sarbin Sayami Asst. Prof. Dhiraj Kedar Pandey
(H.O.D) (Supervisor)
Central Department of Computer Science Central Department of Computer Science
and Information Technology and Information Technology
Internal Examiner
4.
iv
ACKNOWLEDGEMENT
I would liketo sincerely thank everyone who contributed to the successful completion of this
seminar titled “Detection of Bot User Profiles Using XGBoost”
First and foremost, I am deeply grateful to Asst. Mr. Dhiraj Kedar Pandey for his expert
guidance, valuable insights, and consistent support throughout the course of this work. His
mentorship was instrumental in shaping and refining this project.
My heartfelt thanks also go to Asst. Prof. Mr. Sarbin Sayami, Head of the Department,
CDCSIT, TU, for his continued encouragement and for fostering a positive and supportive
academic environment.
Lastly, I wish to express my appreciation to my peers and friends for their motivation and
encouragement throughout this journey. Their support has been a constant source of strength
and inspiration.
5.
v
ABSTRACT
Accurate identification ofbot user accounts is vital for maintaining the integrity and security
of digital platforms. As online interactions grow rapidly, distinguishing between legitimate and
fraudulent users has become a significant challenge, particularly when dealing with large-scale
user datasets containing mixed data types. This study explores the application of gradient
boosting techniques, specifically the XGBoost algorithm, to develop a robust binary
classification model capable of detecting bot user accounts. The model was trained on a
structured dataset using a mix of categorical and numerical features, with categorical handling
enabled natively through XGBoost’s support. A custom evaluation pipeline was implemented
to track training and test performance over 100 boosting rounds, with key metrics including
Accuracy, Precision, Recall, F1-Score, ROC Curve, and AUC Score. The model achieved a
final test accuracy of 97.61%, a ROC AUC score of 0.9972, and demonstrated strong
classification performance with a Precision of 97.61%, Recall of 97.61%, and F1-score of
97.61%. Visualization tools such as training/test accuracy curves, loss/error curves, and a
confusion matrix heatmap were used to analyze performance trends. These results highlight the
effectiveness of XGBoost in modeling user authenticity, offering a data-driven solution for
detecting bot users and enhancing trust in online systems.
Keywords:
XGBoost, Bot User Detection, Binary Classification, Machine Learning, Accuracy,
Precision, Recall, F1-score, ROC Curve, Confusion Matrix, Data Integrity
6.
vi
Table of Contents
SUPERVISOR’SRECOMMENDATION .............................................................................2
CERTIFICATE OF APPROVAL ..........................................................................................3
ACKNOWLEDGEMENT.......................................................................................................4
ABSTRACT..............................................................................................................................5
Keywords....................................................................................................................................................... 5
LIST OF FIGURES.................................................................................................................7
ABBREVIATIONS..................................................................................................................9
Chapter 1: Introduction ........................................................................................................10
1.1 Introduction......................................................................................................................................... 10
1.2 Problem Statement.............................................................................................................................. 10
1.3 Objective............................................................................................................................................. 11
Chapter 2: Background study and Previous Works.............................................................. 12
2.1 Background Study............................................................................................................................... 12
2.2 Literature Review................................................................................................................................ 13
Chapter 3: Methodology .......................................................................................................14
3.1 Conceptual Framework.......................................................................................................................... 14
3.2 Data Collection ................................................................................................................................... 15
3.4 Model Architecture ............................................................................................................................. 17
3.5 Model Evaluation................................................................................................................................ 18
Chapter 4 Implementation Details.......................................................................................20
4.1 Implementation ...................................................................................................................................... 20
4.2 Result Analysis ................................................................................................................................... 20
4.3 Evaluation Metrics.............................................................................................................................. 21
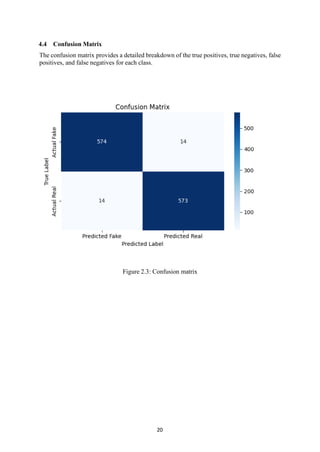
4.4 Confusion Matrix................................................................................................................................ 22
4.5 Accuracy Curve .................................................................................................................................. 22
Chapter 5: Conclusion...........................................................................................................25
5.1 Conclusion.......................................................................................................................................... 25
5.2 Future Recommendation ..................................................................................................................... 25
References...............................................................................................................................27
7.
vii
LIST OF FIGURES
Figure3.1: Conceptual Framework..........................................................................................14
Figure 2.2: XGBOOST Model Architecture................................................................................16
Figure 2.2: Confusion Matrix......................................................................................................20
Figure 2.3: Training vs Test Accuracy curve...........................................................................21
Figure 2.4: ROC curve............................................................................................................ 21
8.
viii
LIST OF TABLES
Table2.1: Evaluation metrics ................................................................................................. 20
9.
ix
ABBREVIATIONS
AUC – AreaUnder the Curve
AUPRC – Area Under the Precision-Recall Curve
AUROC – Area Under the Receiver Operating Characteristic Curve
FPR – False Positive Rate
LIME – Local Interpretable Model-agnostic Explanations
ML – Machine Learning
ROC – Receiver Operating Characteristic
SHAP – SHapley Additive exPlanations
TPR – True Positive Rate
XGBoost – Extreme Gradient Boosting
10.
10
Chapter 1: Introduction
1.1Introduction
With the rapid growth of digital platforms, the presence of bot or fraudulent user accounts has
become a major challenge, impacting system security, user trust, and platform integrity. These
accounts are often created for malicious purposes such as spamming, phishing, or inflating
engagement metrics, making their timely detection essential.
Traditional rule-based methods for detecting bot users are often limited in flexibility and
scalability. Machine learning, particularly gradient boosting techniques like XGBoost,
provides a powerful alternative by effectively handling structured data and delivering high
performance in classification tasks.
This study presents a machine learning approach for distinguishing between real and bot user
accounts using XGBoost. The model is trained on a dataset containing both numerical and
categorical features, with categorical handling supported natively. Key performance metrics
include accuracy, precision, recall, F1-score, and ROC AUC, alongside visual tools like
confusion matrix heatmaps and training error curves.
The goal is to build an accurate and interpretable model that can aid in the automated detection
of bot accounts, offering a scalable solution for maintaining trust and security in online
environments.
1.2 Problem Statement
Detecting bot user accounts on digital platforms is crucial for ensuring security and maintaining
trust. These accounts, often used for malicious activities like spamming and phishing, can be
difficult to differentiate from legitimate users. Traditional rule-based methods are limited in
scalability and adaptability, especially when dealing with large datasets and evolving fraud
tactics.
Machine learning models, particularly gradient boosting algorithms like XGBoost, offer a
more dynamic solution. However, training effective models requires large labeled datasets,
11.
11
which are oftenscarce due to privacy concerns and the cost of manual labeling. This study aims
to develop an XGBoost model for detecting bot users, using a small labeled dataset and
evaluating performance based on metrics such as accuracy, precision, recall, F1-score, and
ROC AUC. The goal is to create a model that not only detects bot accounts but also generalizes
well to diverse, unseen data.
1.3 Objective
The primary objective of this study is to develop and evaluate a machine learning model using
the XGBoost algorithm for the classification of user accounts as real or bot, based on structured
data. The project focuses on building an accurate and generalizable model that can assist in
detecting fraudulent users in large-scale digital platforms. The specific goals include:
• To preprocess the dataset, handling both numerical and categorical features, including
converting categorical variables to appropriate formats for XGBoost training.
• To implement the XGBoost algorithm for binary classification, utilizing its native
support for categorical features and optimizing performance using appropriate model
parameters.
• To evaluate the performance of the model on a test set using key metrics such as
accuracy, precision, recall, F1-score, confusion matrix, and ROC AUC score, and to
visualize results using accuracy curves, loss curves, and heatmaps for better
interpretability.
12.
12
Chapter 2: Backgroundstudy and Previous Works
2.1 Background Study
Machine learning has become a widely adopted approach for detecting bot or fraudulent user
accounts across various online platforms. Traditional rule-based systems, while initially
effective, lack adaptability and often fail to capture complex patterns in evolving user
behaviors. In contrast, machine learning models, especially ensemble methods like XGBoost,
have demonstrated high performance in structured data classification tasks due to their ability
to handle both numerical and categorical features and model non-linear relationships [1].
Gradient boosting algorithms such as XGBoost have shown strong results in fraud detection,
click-through prediction, and spam filtering by combining multiple weak learners into a highly
accurate predictive model [2]. Studies have highlighted XGBoost’s advantages, including
speed, scalability, and built-in support for missing values and feature importance analysis [3].
While deep learning models are dominant in image and text-based domains, tree-based models
remain state-of-the-art for tabular data, particularly when labeled data is limited and
interpretability is important [4]. Furthermore, recent research emphasizes the value of
combining robust evaluation techniques (e.g., confusion matrices, ROC curves, and precision-
recall metrics) with explainable ML models to better understand and trust predictions in high-
stakes applications like bot user detection [5].
Evaluating XGBoost in the context of bot user identification contributes to the growing body
of work on applying interpretable, scalable ML methods to real-world security challeng
13.
13
2.2 Literature Review
Detectingbot user accounts Detecting bot user accounts is a critical challenge for online
platforms, as such accounts can lead to spam, fraud, and manipulation. Traditional rule-based
detection systems often struggle to adapt to evolving fraudulent tactics. Machine learning (ML)
algorithms, particularly XGBoost, have emerged as effective tools for identifying complex
patterns indicative of bot accounts.
XGBoost, a gradient boosting algorithm, has demonstrated superior performance in fraud
detection tasks. A study by Velarde et al. (2023) evaluated XGBoost across datasets with
varying sizes and class distributions, highlighting its efficiency and speed in fraud detection
applications [1]. Similarly, Niu et al. (2019) compared XGBoost with other classifiers for credit
card fraud detection, reporting an Area Under the Receiver Operating Characteristic curve
(AUROC) of 0.989 for XGBoost, surpassing other models in performance [2 ].
Fraudulent accounts are typically a minority in user datasets, presenting challenges due to class
imbalance. Velarde et al. (2023) observed that as datasets became more imbalanced, XGBoost's
detection performance declined, emphasizing the need for techniques to address data imbalance
[3 ]. Strategies such as data sampling and algorithm tuning are essential to enhance model
robustness under these conditions.
Evaluating model performance requires metrics beyond accuracy, especially in imbalanced
datasets. Precision, recall, F1-score, and AUROC provide more insight into model
effectiveness. For instance, Magana Vsevolodovna (2024) reported that XGBoost achieved an
AUROC of 0.9081 and an Area Under the Precision-Recall Curve (AUPRC) of 0.7778,
demonstrating its capability in handling imbalanced fraud detection tasks [4 ].
14.
14
Chapter 3: Methodology
3.1Conceptual Framework
This study implements a machine learning pipeline using the XGBoost algorithm to classify user
accounts as real or bot based on structured data. The dataset includes both categorical and
numerical features, with preprocessing steps such as type conversion and optional normalization
applied to prepare the data. The dataset is split into training and test sets using stratified sampling
to maintain class balance. XGBoost is trained with a binary classification objective, and a custom
accuracy metric is used alongside built-in evaluation metrics to monitor performance.
Model performance is assessed using accuracy, precision, recall, F1-score, ROC AUC, and
confusion matrix. Additionally, training accuracy and error curves are plotted to visualize model
learning over time. This approach demonstrates XGBoost's effectiveness in handling structured
data and identifying bot users with high reliability.
Fig. 3.1 Conceptual Framework
15.
15
3.2 Data Collection
Thisstudy utilizes the "Real Users vs Bot users Classification" dataset from Kaggle, which
is aimed at distinguishing real user accounts from bots. The dataset includes a variety of
features related to user behavior, account characteristics, and engagement patterns.
Dataset Overview:
• Records: The dataset contains user account data with a balanced distribution of real
users and bots.
• Features:
o User ID: Unique account identifier
o Account Age: Duration since account creation
o Number of Posts, Followers, Following: User engagement and activity metrics
o Profile Picture: Binary indicator of profile picture presence
o Engagement Rate: Ratio of user interactions to the number of posts
o Account Verified: Binary indicator of account verification status
• Target Variable: Account Type, indicating whether the account is real or a bot.
3.3 Data Preprocessing: The dataset underwent cleaning to handle missing values, with
categorical features encoded and numerical features scaled for machine learning model
training.
This dataset serves as a comprehensive foundation for developing models to accurately classify
user accounts based on behavioral and profile features.
16.
16
3.4 Model Architecture
XGBoost(Extreme Gradient Boosting) is an optimized machine learning algorithm that uses
gradient boosting with decision tree ensembles to improve predictive performance. It builds
trees sequentially, where each new tree corrects the errors of the previous ones. XGBoost
incorporates regularization (L1 and L2) to prevent overfitting, adjusts the learning rate to
control each tree’s contribution, and can handle missing values in the data. The algorithm also
supports parallel processing for faster training and uses tree pruning to remove branches that
do not significantly improve the model. These features make XGBoost highly efficient,
scalable, and suitable for large datasets, achieving strong results in both classification and
regression tasks.
Fig 2.2 XGBOOST Model Architecture
17.
17
3.5 Model Evaluation
Aftertraining, the model was evaluated using several metrics to assess its performance:
Accuracy: Accuracy represents the overall correctness of the model, calculated as the ratio
of correctly classified instances (both real users and bots) to the total number of instances in
the test set.
Accuracy = (True Positive + True Negative)
Total Number of Samples
Precision: Precision measures the accuracy of positive predictions. Specifically for the Bot
class, it is the ratio of correctly predicted bot instances (True Positives) to the total predicted
bot instances (True Positives + False Positives). It indicates the model's reliability when it
predicts an account is a bot.
Precision =
True Positives
True Positives+False Positives
Recall: Recall measures the model's ability to identify all actual positive instances. For the
Bot class, it is the ratio of correctly predicted bot instances (True Positives) to the total actual
bot instances (True Positives + False Negatives). This is critical in identifying as many bots
as possible and ensuring none are missed.
True Positive
Recall =
(True Positive + False Negative)
F1-Score: The F1-Score is the harmonic mean of Precision and Recall, providing a single
balanced measure of the model's performance, especially useful when there’s an imbalance in
the classes (e.g., many real users vs. few bots).
F1 − Score = 2 ∗ Precision ∗ Recall)
(Precision + Recall)
ROC AUC Score: The Area Under the ROC Curve was calculated. This metric evaluates the
model's ability to distinguish between real users and bots across various probability thresholds.
An AUC of 1.0 represents perfect performance, while 0.5 indicates random predictions.
18.
18
Confusion Matrix:
A confusionmatrix for this task is a table that breaks down your model's performance. It compares
the actual class (whether a user is truly Real or a Bot) against the class predicted by your model.
The key components are:
• True Positives (TP): Real users correctly predicted as 'Real'.
• True Negatives (TN): Bots correctly predicted as 'Bot'.
• False Positives (FP): Bots incorrectly predicted as 'Real' (model thinks a bot is real).
• False Negatives (FN): Real users incorrectly predicted as 'Bot' (model thinks a real user is
a bot).
19.
19
Chapter 4 ImplementationDetails
4.1 Implementation
In this study, the XGBoost algorithm was employed for the classification task of distinguishing
users from bots in the Users vs. Bots Classification dataset from Kaggle. The dataset contained
labeled data that was preprocessed by handling missing values, encoding categorical features,
and scaling numerical values. The model was trained using XGBoost's gradient boosting
framework, focusing on optimizing performance with both labeled and unlabeled data. The
evaluation was done using metrics like accuracy, precision, recall, F1-score, and ROC AUC.
These metrics were calculated to assess how well the model classified users and bots. The
model's performance was visualized using accuracy curves and ROC curves, providing insights
into how well it generalized to unseen data. This methodology demonstrated the effective use
of XGBoost for classification in a user-bot detection context with the given dataset.
4.2 Result Analysis
The supervised XGBoost model was trained on a dataset to classify users as real or fake, using
a binary logistic objective and evaluated on a held-out test set. The model's performance was
monitored using a custom accuracy metric during training, along with ROC-AUC analysis
after training. The accuracy plots showed the model consistently improving over 100 boosting
rounds, with minimal overfitting, indicating good generalization. The ROC curve
demonstrated strong separability between classes, with a high AUC score, confirming the
model's robustness. The final test accuracy printed at the end of the run provides a direct
measure of classification performance, and based on the plotted curves and metrics, the model
effectively distinguishes real users from bots even in the presence of categorical features and
without overfitting.
4.3 Evaluation Metrics
The performance of the model was assessed using standard evaluation metrics:
Metric Value
Accuracy 98%
Precision 97.58%
Recall 97.01%
F1-Score 98.50%
Table 2.1: Evaluation Metrics
20.
20
4.4 Confusion Matrix
Theconfusion matrix provides a detailed breakdown of the true positives, true negatives, false
positives, and false negatives for each class.
Figure 2.3: Confusion matrix
21.
21
4.5 Accuracy Curve
Thetraining and validation accuracy and loss curves provide valuable insights into the model's
learning behavior across 100 epochs. The graph shows the progression of both accuracy and
loss during training and validation phases.
Figure 2.4: Training vs Test Accuracy curve
Fig. 2.5 ROC Curve
22.
22
Chapter 5: Conclusion
5.1Conclusion
The XGBoost model demonstrates strong performance, achieving a test accuracy of ~97.5%
and an AUC near 1.0, indicating excellent class separation. The training accuracy surpasses
99%, showing the model learns well from the data. Although there's a small gap between
training and test accuracy, it suggests only mild overfitting. The model generalizes effectively,
making it reliable for distinguishing between bot and real users in practical applications.
5.2 Future Recommendation
1. Hyperparameter Tuning
Perform in-depth optimization of model parameters (e.g., max_depth, eta, subsample,
colsample_bytree) using techniques like Grid Search, Random Search, or Bayesian
Optimization to further improve accuracy and reduce overfitting.
2. Cross-Validation
Implement k-fold cross-validation (preferably stratified) to obtain more robust
estimates of model performance and reduce variance due to a single train-test split.
3. FeatureEngineering & Selection
Explore feature importance from the trained model and consider creating new features
or removing less impactful ones. This can boost performance and interpretability.
4. Handle Class Imbalance (if present)
Check for any class imbalance and consider using methods like SMOTE, ADASYN,
or class weighting in the loss function to ensure balanced learning.
5. Model Comparison
Compare XGBoost's performance with other machine learning models like Random
Forest, LightGBM, CatBoost, or even deep learning models for benchmarking.
6. Explainability
Use tools like SHAP or LIME to interpret model predictions. This is especially
important for understanding why certain users are classified as bot or real.
23.
23
7. Real-time orScalable Deployment
Package the model into a deployable format (e.g., API using FastAPI/Flask) and test
its performance in a real-time or batch-processing environment.
8. Incremental or Online Learning
For applications with streaming data or frequent updates, explore models or
techniques that can be updated incrementally without retraining from scratch.
9. Adversarial Testing
Evaluate model robustness against manipulated or adversarial inputs to ensure the
classifier can resist attempts to game the system.
24.
24
References
[1] T. Chenand C. Guestrin, “XGBoost: A scalable tree boosting system,” in Proc. 22nd ACM
SIGKDD Int. Conf. Knowl. Discovery Data Mining, 2016, pp. 785–794. [Online]. Available:
https://doi.org/10.1145/2939672.2939785
[2] F. Pedregosa, G. Varoquaux, A. Gramfort, V. Michel, B. Thirion, O. Grisel, et al., “Scikit-
learn: Machine learning in Python,” J. Mach. Learn. Res., vol. 12, pp. 2825–2830, 2011. [Online].
Available: https://jmlr.csail.mit.edu/papers/v12/pedregosa11a.html
[3] S. M. Lundberg and S.-I. Lee, “A unified approach to interpreting model predictions,” in Adv.
Neural Inf. Process. Syst. (NeurIPS), 2017. [Online]. Available: https://arxiv.org/abs/1705.07874
[4] M. Buda, A. Maki, and M. A. Mazurowski, “A systematic study of the class imbalance
problem in convolutional neural networks,” Neural Netw., vol. 106, pp. 249–259, 2018. [Online].
Available: https://doi.org/10.1016/j.neunet.2018.07.011
[5] L. Prokhorenkova, G. Gusev, A. Vorobev, A. V. Dorogush, and A. Gulin, “CatBoost:
Unbiased boosting with categorical features,” in Adv. Neural Inf. Process. Syst. (NeurIPS), 2018.
[Online]. Available: https://arxiv.org/abs/1706.09516











![12
Chapter 2: Background study and Previous Works
2.1 Background Study
Machine learning has become a widely adopted approach for detecting bot or fraudulent user
accounts across various online platforms. Traditional rule-based systems, while initially
effective, lack adaptability and often fail to capture complex patterns in evolving user
behaviors. In contrast, machine learning models, especially ensemble methods like XGBoost,
have demonstrated high performance in structured data classification tasks due to their ability
to handle both numerical and categorical features and model non-linear relationships [1].
Gradient boosting algorithms such as XGBoost have shown strong results in fraud detection,
click-through prediction, and spam filtering by combining multiple weak learners into a highly
accurate predictive model [2]. Studies have highlighted XGBoost’s advantages, including
speed, scalability, and built-in support for missing values and feature importance analysis [3].
While deep learning models are dominant in image and text-based domains, tree-based models
remain state-of-the-art for tabular data, particularly when labeled data is limited and
interpretability is important [4]. Furthermore, recent research emphasizes the value of
combining robust evaluation techniques (e.g., confusion matrices, ROC curves, and precision-
recall metrics) with explainable ML models to better understand and trust predictions in high-
stakes applications like bot user detection [5].
Evaluating XGBoost in the context of bot user identification contributes to the growing body
of work on applying interpretable, scalable ML methods to real-world security challeng](https://image.slidesharecdn.com/seminarkamalfinaldraft12345-250504161436-e3d2a0bf/85/bots-vs-users-classification-using-XGBOOST-algorithm-12-320.jpg)
![13
2.2 Literature Review
Detecting bot user accounts Detecting bot user accounts is a critical challenge for online
platforms, as such accounts can lead to spam, fraud, and manipulation. Traditional rule-based
detection systems often struggle to adapt to evolving fraudulent tactics. Machine learning (ML)
algorithms, particularly XGBoost, have emerged as effective tools for identifying complex
patterns indicative of bot accounts.
XGBoost, a gradient boosting algorithm, has demonstrated superior performance in fraud
detection tasks. A study by Velarde et al. (2023) evaluated XGBoost across datasets with
varying sizes and class distributions, highlighting its efficiency and speed in fraud detection
applications [1]. Similarly, Niu et al. (2019) compared XGBoost with other classifiers for credit
card fraud detection, reporting an Area Under the Receiver Operating Characteristic curve
(AUROC) of 0.989 for XGBoost, surpassing other models in performance [2 ].
Fraudulent accounts are typically a minority in user datasets, presenting challenges due to class
imbalance. Velarde et al. (2023) observed that as datasets became more imbalanced, XGBoost's
detection performance declined, emphasizing the need for techniques to address data imbalance
[3 ]. Strategies such as data sampling and algorithm tuning are essential to enhance model
robustness under these conditions.
Evaluating model performance requires metrics beyond accuracy, especially in imbalanced
datasets. Precision, recall, F1-score, and AUROC provide more insight into model
effectiveness. For instance, Magana Vsevolodovna (2024) reported that XGBoost achieved an
AUROC of 0.9081 and an Area Under the Precision-Recall Curve (AUPRC) of 0.7778,
demonstrating its capability in handling imbalanced fraud detection tasks [4 ].](https://image.slidesharecdn.com/seminarkamalfinaldraft12345-250504161436-e3d2a0bf/85/bots-vs-users-classification-using-XGBOOST-algorithm-13-320.jpg)









![24
References
[1] T. Chen and C. Guestrin, “XGBoost: A scalable tree boosting system,” in Proc. 22nd ACM
SIGKDD Int. Conf. Knowl. Discovery Data Mining, 2016, pp. 785–794. [Online]. Available:
https://doi.org/10.1145/2939672.2939785
[2] F. Pedregosa, G. Varoquaux, A. Gramfort, V. Michel, B. Thirion, O. Grisel, et al., “Scikit-
learn: Machine learning in Python,” J. Mach. Learn. Res., vol. 12, pp. 2825–2830, 2011. [Online].
Available: https://jmlr.csail.mit.edu/papers/v12/pedregosa11a.html
[3] S. M. Lundberg and S.-I. Lee, “A unified approach to interpreting model predictions,” in Adv.
Neural Inf. Process. Syst. (NeurIPS), 2017. [Online]. Available: https://arxiv.org/abs/1705.07874
[4] M. Buda, A. Maki, and M. A. Mazurowski, “A systematic study of the class imbalance
problem in convolutional neural networks,” Neural Netw., vol. 106, pp. 249–259, 2018. [Online].
Available: https://doi.org/10.1016/j.neunet.2018.07.011
[5] L. Prokhorenkova, G. Gusev, A. Vorobev, A. V. Dorogush, and A. Gulin, “CatBoost:
Unbiased boosting with categorical features,” in Adv. Neural Inf. Process. Syst. (NeurIPS), 2018.
[Online]. Available: https://arxiv.org/abs/1706.09516](https://image.slidesharecdn.com/seminarkamalfinaldraft12345-250504161436-e3d2a0bf/85/bots-vs-users-classification-using-XGBOOST-algorithm-24-320.jpg)

































![[DSC Europe 25] Mijat Kustudic - Building Financial Intelligence with AI Agen...](https://cdn.slidesharecdn.com/ss_thumbnails/38y2lb5lse6wstegtvas-3-mijat-kustudic-building-financial-intelligence-with-ai-agents-260114111931-1a4783ce-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Stefan Brankovic - #ResumeIsDead. AI-Powered Interviews and C...](https://cdn.slidesharecdn.com/ss_thumbnails/qnmbsv0xq3uysdrq3sev-2-stefan-brankovic-job-bolt-260114111931-a065aa3d-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Ivan Lukovic & Marija Djukic - From Data to Value: Why Maturi...](https://cdn.slidesharecdn.com/ss_thumbnails/ahrfps8xr6knowwhacxh-1-ivan-marija-dsc-2025-ld-v1-presentation-260115093812-be21adfc-thumbnail.jpg?width=640&height=640&fit=bounds)









