Springer exemplar
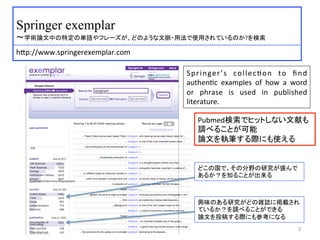
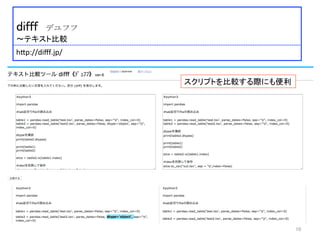
〜学術論文中の特定の単語やフレーズが、どのような文脈・用法で使用されているのか?を検索
h:p://www.springerexemplar.com
Springer’s
collec)on
to
find
authen)c
examples
of
how
a
word
or
phrase
is
used
in
published
literature.
2
興味のある研究がどの雑誌に掲載され
ているか?を調べることができる
論文を投稿する際にも参考になる
どこの国で、その分野の研究が盛んで
あるか?を知ることが出来る
Pubmed検索でヒットしない文献も
調べることが可能
論文を執筆する際にも使える
3.
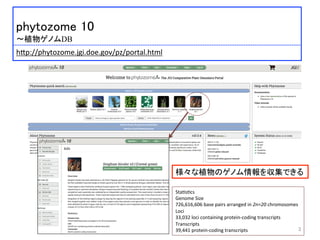
phytozome 10
〜植物ゲノムDB
h:p://phytozome.jgi.doe.gov/pz/portal.html
Sta)s)cs
Genome
Size
726,616,606
base
pairs
arranged
in
2n=20
chromosomes
Loci
33,032
loci
containing
protein-‐coding
transcripts
Transcripts
39,441
protein-‐coding
transcripts
3
様々な植物のゲノム情報を収集できる
4.
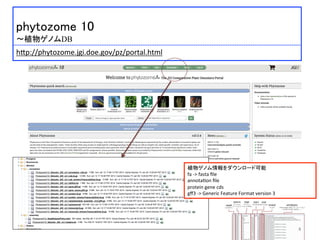
phytozome 10
〜植物ゲノムDB
h:p://phytozome.jgi.doe.gov/pz/portal.html
植物ゲノム情報をダウンロード可能
fa
-‐>
fasta
file
annota)on
file
protein
gene
cds
gff3
-‐>
Generic
Feature
Format
version
3
4
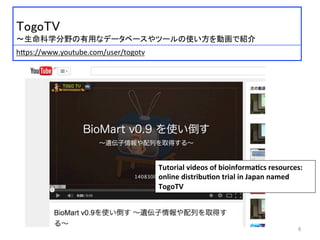
TogoTV
〜生命科学分野の有用なデータベースやツールの使い方を動画で紹介
h:ps://www.youtube.com/user/togotv
Tutorial
videos
of
bioinforma2cs
resources:
online
distribu2on
trial
in
Japan
named
TogoTV
6