



![Model sizes
Instance models with several million elements
o AUTOSAR models [1]
o Source code models
o Sensor data
Source: Markus Scheidgen, How Big are Models – An Estimation, 2012. [2]
application model size
software models 0 – 109
sensor data 109
geo-spatial models 109 – 1012
[1] http://wiki.eclipse.org/Auto_IWG_WP2
[2] http://hwl.hu-berlin.de/fileadmin/user_upload/documents/howbig_techreport.pdf](https://image.slidesharecdn.com/bigmde-incquery-d-130702044027-phpapp02/85/IncQuery-D-Incremental-Queries-in-the-Cloud-5-320.jpg)







![1
2
4
8
16
32
64
128
256
512
1024
2048
4096
0.1 /
0.008
0.2 /
0.015
0.5 /
0.03
0.9 /
0.06
1.7 /
0.114
3.5 /
0.231
7.1 /
0.47
14.1 /
0.945
28.0 /
1.907
55.8 /
3.853
time[s]
model size [million elements / file size in GB]
Neo4j/Cypher (batch) IncQuery-D (incremental)
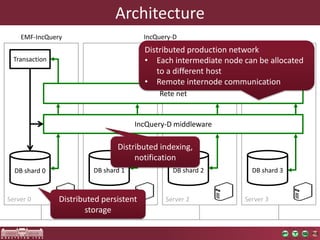
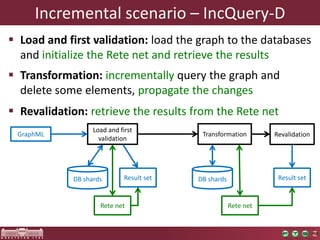
Load and first validation phase
Small overhead for
the Rete network’s
construction
50M+: approx. 30 minutesParallel loading of the
graph from a GraphML
representation](https://image.slidesharecdn.com/bigmde-incquery-d-130702044027-phpapp02/85/IncQuery-D-Incremental-Queries-in-the-Cloud-19-320.jpg)
![1
2
4
8
16
32
64
128
256
512
1024
2048
4096
0.1 /
0.008
0.2 /
0.015
0.5 /
0.03
0.9 /
0.06
1.7 /
0.114
3.5 /
0.231
7.1 /
0.47
14.1 /
0.945
28.0 /
1.907
55.8 /
3.853
time[s]
model size [million elements / file size in GB]
Neo4j/Cypher (batch) IncQuery-D (incremental)
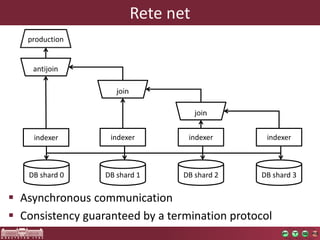
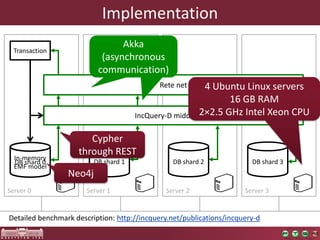
Transformation phase
1. Elementary model query
2. Model manipulation
• Both implemented with Cypher
• The query evaluation time is dominating
• Query is supported by the Rete net
• Only the manipulation implemented with Cypher
• Overhead due to change propagation is negligible
• 1.5 OOM faster
• Performs a transformation
over a 55M model in one
minute](https://image.slidesharecdn.com/bigmde-incquery-d-130702044027-phpapp02/85/IncQuery-D-Incremental-Queries-in-the-Cloud-20-320.jpg)
![0.25
1
4
16
64
256
1024
4096
0.1 /
0.008
0.2 /
0.015
0.5 /
0.03
0.9 /
0.06
1.7 /
0.114
3.5 /
0.231
7.1 /
0.47
14.1 /
0.945
28.0 /
1.907
55.8 /
3.853
time[s]
model size [million elements / file size in GB]
Neo4j/Cypher (batch) IncQuery-D (incremental)
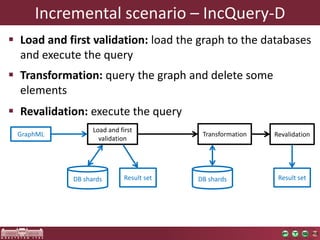
Revalidation phase
Near instant
response time for
very large models
Different characteristics,
4 OOM for the largest model
Revalidation time is
independent of node size](https://image.slidesharecdn.com/bigmde-incquery-d-130702044027-phpapp02/85/IncQuery-D-Incremental-Queries-in-the-Cloud-21-320.jpg)



The document presents the incquery-d approach developed by the Budapest University of Technology and Economics for scalable incremental graph queries in cloud environments. It addresses the limitations of existing tools when handling large models by proposing a distributed system architecture that enhances performance through data sharding and asynchronous communication. The evaluation demonstrates significant improvements in scalability and speed for processing complex model queries, paving the way for future developments in tooling and optimization.













































































