Download to read offline









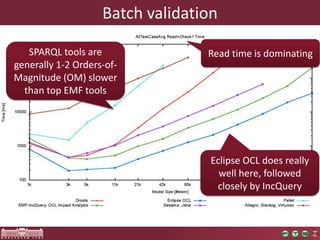
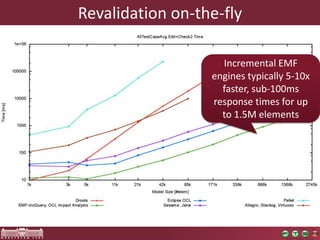
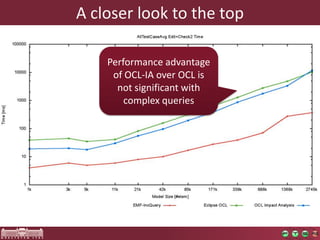
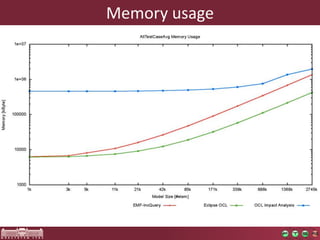


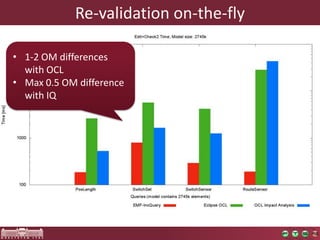









High performance model queries and their novel applications discusses model query performance for large models. Benchmark results show that model size affects query response times polynomially, with incremental engines achieving lower exponents. Query complexity also significantly impacts performance, with RETE-based tools like EMF-IncQuery performing well regardless of complexity. EMF-IncQuery is presented as an optimized model query engine for incremental queries, enabling on-the-fly validation over large models.























































































