Downloaded 11 times












![{
"version": "v2.0",
"data": [
{
"title": "Normans",
"paragraphs": [
{
"qas": [
{
"question": "In what country is Normandy located?",
"id": "56ddde6b9a695914005b9628",
"answers": [
{
"text": "France",
"answer_start": 159
}
],
"is_impossible": false
}
],
"context": "The Normans (Norman: Nourmands; French: Normands; Latin: Normanni) were the
people who in the 10th and 11th centuries gave their name to Normandy, a region in France.
They were descended from Norse ("Norman" comes from "Norseman") raiders and pirates from
Denmark, Iceland and Norway who, under their leader Rollo, agreed to swear fealty to King
Charles III of West Francia. Through generations of assimilation and mixing with the native
Frankish and Roman-Gaulish populations, their descendants would gradually merge with the
Carolingian-based cultures of West Francia. The distinct cultural and ethnic identity of the
Normans emerged initially in the first half of the 10th century, and it continued to evolve
over the succeeding centuries."
}
]
}
]
}
JSON Structure
13](https://image.slidesharecdn.com/bertforquestionansweringonsquad2-191101020530/85/Bert-for-question-answering-on-SQuAD-2-0-13-320.jpg)



![Pre-training BERT
• Masked Language Model (MLM)
• Input:
my dog is hairy
• sẽ được chuyển thành
my dog is [MASK]
• sau đó [MASK] sẽ được thay thế bằng một từ ngẫu nhiên, ví dụ
my dog is apple
• Giữ lại câu gốc và tính độ lệch so với từ dự đoán thông qua hàm mất
mát cross entropy
17](https://image.slidesharecdn.com/bertforquestionansweringonsquad2-191101020530/85/Bert-for-question-answering-on-SQuAD-2-0-17-320.jpg)
![Pre-training BERT
• Next Sentence Prediction (NSP)
Input = [CLS] the man went to [MASK] store [SEP]
he bought a gallon [MASK] milk SEP]
Label = IsNext
Input = [CLS] the man [MASK] to the store [SEP]
penguin [MASK] are flight ##less birds [SEP]
Label = NotNext
18](https://image.slidesharecdn.com/bertforquestionansweringonsquad2-191101020530/85/Bert-for-question-answering-on-SQuAD-2-0-18-320.jpg)

![Input Representation
• Token Embeddings: sử dụng pretrained WordPiece embeddings
• Position Embeddings: sử dụng learned Position Embeddings
• Sử dụng [SEP] để phân tách các câu
• Sử dụng [CLS] để phân tách các lớp (gồm nhiều câu)
20](https://image.slidesharecdn.com/bertforquestionansweringonsquad2-191101020530/85/Bert-for-question-answering-on-SQuAD-2-0-20-320.jpg)
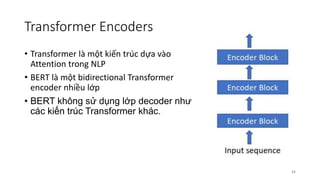

![Inside an Encoder Block
• Input Embedding
• Hello, how are you?”
• → [“Hello”, “,” , “how”, “are”, “you”, “?”]
• → [34, 90, 15, 684, 55, 193]
23](https://image.slidesharecdn.com/bertforquestionansweringonsquad2-191101020530/85/Bert-for-question-answering-on-SQuAD-2-0-23-320.jpg)






![nbest_predictions.json{
"56ddde6b9a695914005b9628": [
{
"text": "mands; French: Normands; Latin: Normanni) were the
people who in the 10th and 11th centuries gave their",
"probability": 0.05308649383291742,
"start_logit": 0.36476194858551025,
"end_logit": 0.7789570689201355
},
{
"text": "based",
"probability": 0.05172724203669382,
"start_logit": 0.4540586471557617,
"end_logit": 0.6637223958969116
}
]
}
30](https://image.slidesharecdn.com/bertforquestionansweringonsquad2-191101020530/85/Bert-for-question-answering-on-SQuAD-2-0-30-320.jpg)


Tài liệu giới thiệu về hệ thống trả lời câu hỏi (QA) trong NLP, với 3 loại câu hỏi chính và 4 phương pháp tiếp cận khác nhau cho QA. SQuAD 2.0 là bộ dữ liệu quan trọng, kết hợp 100,000 câu hỏi từ SQuAD 1.1 và hơn 50,000 câu hỏi mới không có câu trả lời. BERT, với kiến trúc encoder biến thể hai chiều, được sử dụng để cải thiện hiệu suất trong các nhiệm vụ QA.












![[123doc] do-an-phan-mem-quan-ly-nhan-su-tien-luong](https://cdn.slidesharecdn.com/ss_thumbnails/123doc-do-an-phan-mem-quan-ly-nhan-su-tien-luong-220312022256-thumbnail.jpg?width=640&height=640&fit=bounds)













![[224] 번역 모델 기반_질의_교정_시스템](https://cdn.slidesharecdn.com/ss_thumbnails/242-150915010843-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)











