Downloaded 124 times

Uploaded byFernando Rodrigues Junior
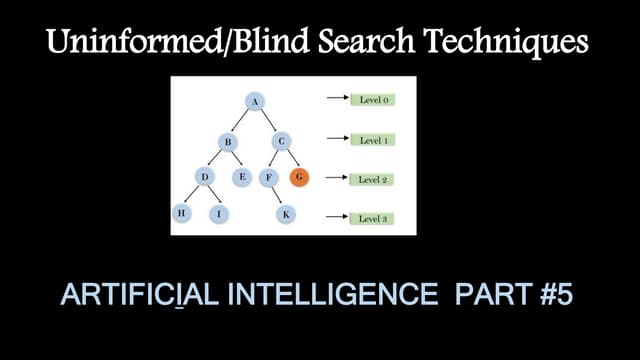
Breadth-First Search, Depth-First Search and Backtracking Depth-First Search Algorithms applied on a Sudoku Puzzle Solver
This document studies three search algorithms: breadth-first search (BFS), depth-first search (DFS), and backtracking depth-first search (B-DFS), particularly in the context of solving Sudoku puzzles. It concludes that B-DFS generally requires less memory and time compared to BFS and DFS, though each algorithm may perform differently based on the problem's specific characteristics. The findings emphasize the importance of pruning techniques in optimizing search space and highlight the limitations of brute force algorithms like DFS and B-DFS, suggesting future exploration of constraint satisfaction methods.
More Related Content














































Similar to Breadth-First Search, Depth-First Search and Backtracking Depth-First Search Algorithms applied on a Sudoku Puzzle Solver







































Breadth-First Search, Depth-First Search and Backtracking Depth-First Search Algorithms applied on a Sudoku Puzzle Solver
- 1. Breadth-First Search, Depth-FirstSearch and Backtracking Depth-First Search Algorithms Fernando Rodrigues Junior College of Science and Engineering University of Minnesota - Twin Cities Minneapolis, Minnesota 554550 Email: rodri987@umn.edu Abstract—This study concludes that the B-DFS is designated to applications that have a big state space which requires a great amount of memory. Using a practical problem as a Sudoku Puzzle, was possible to demonstrate that the Backtracking Depth- First Search (B-DFS) has a lower bounded space complexity than the regular Depth-First Search (DFS) algorithm. It saves more memory, but in some applications requires more computational effort due to the necessity to backtrack the actions many times. There are different approaches in respect of how to store the informations in each step throughout the expansion process, thus the best search algorithm depends on the nature of the problem. I. INTRODUCTION Search algorithms are used to solve problems from puzzles (e.g. Sudoku, KenKen, Towers of Hanoi) to more complex problems such as Video-Game, Signal Management [3] and Path-Planning for Robots [4]. Time and physical space is important to decide which algorithm is designated to solve certain problem. In many applications the state-space is big and is expected to find a solution fast. There are different kinds of search algorithms and this paper will briefly cover three of them. The Breadth-First Search, Depth-First Search and the Backtraking Depth-Search First. A standard search algorithm such as Breadth-First Search (BFS) is considered a complete algorithm representing that if a solution exists, it certainly will be found. However, BFS may be a big challenge in terms of performance and memory allocation. Some applications using this kind of approach requires a big amount of memory and time which sometimes are not compatible with the requisites for an expected solution. Looking for an alternative, this paper presents the Backtrack- ing Depth-First Search (B-DFS), another approach to solve search problems using less memory. It is important to be aware that every algorithm has limitations to be respected, otherwise the solution may not be guaranteed. In the next sections, is possible to understand the differences between the algorithms. Also, a practical application with met- rics and conclusion is presented to the different approaches. II. THE SUDOKU PUZZLE Sudoku consists in a puzzle game that you have a board of nine by nine squares (there are different sizes, but 9X9 is the most common). The board already contains some random numbers allocated and the final objective is filling all the remaining empty spaces. For that there are some rules the player have to follow. First, only integer values are acceptable, for example, in the conventional puzzle, the player can choose numbers from one to nine to fill each square. Second, it is required to all the squares from the same row and column to have different numbers. Third, each one of the nine boxes has to have different numbers. The boxes are nine 3X3 sub- grids that compose the grid [1]. The main idea to solve the game is to try each combination of numbers in each empty spot making sure that the rules are not violated. The Sudoku puzzle will be used as a practical example of the BDS, DFS and B-DFS applications in this paper. III. BREADTH-FIRST SEARCH, DEPTH-FIRST SEARCH AND BACKTRACKING DEPTH-FIRST SEARCH Breadth-First Search, Depth-First Search (DFS) and Back- tracking Depth-First Search (B-DFS) are uninformed search strategies that use the concept of a queue to expand the states from a graph or a tree structure. The Breadth-First Search expands the nodes horizontally fig. 1. It means that before expanding the next level to the bottom, it expands all the nodes from the same level first. Furthermore, BFS uses a FIFO (First-In-First-Out) queue fig. 2, to guarantee that the nodes are going to be expanded in the same order that they were created. Fig. 1. Breadth-First Search and the expansion process storing one copy of the board for each state. The nodes are expanded horizontally. Differently, DFS and B-DFS expands nodes vertically and stop increasing the depth only if a goal or a dead-end is reached. To make this mechanic possible, the algorithm uses the concept of a Last-In-First-Out (LIFO) Queue Fig. 3. This queue represents the next nodes that are going to be visited
- 2. Fig. 2. First-Input-First-Output(FIFO) Queue order. A and D were already expanded, thus they do not belong to the queue anymore. This kind of queue is used to the BFS algorithm. and consecutively expanded. The expansion order is inverse as the created order, thus the three first nodes were generated in the order as follows: 1st - A, 2nd - B and 3rd - C. The first node to be expanded is the last node inserted in the queue - node C. Fig. 3. Last-Input-First-Output (LIFO) Queue order. C and F were already expanded, thus they do not belong to the queue anymore. This kind of queue is used to the DFS and B-DFS algorithms. In both DFS and B-DFS the nodes are visited and expanded as the fig. 4, generating children according to the different actions applied to the last state. Even though both algorithms use the same approach in terms of the node expansion process, they have different representations about the information storage. For example, in regular DFS each state stores one representation of the entire puzzle that depending on the state size can cost a lot of memory. On the other hand, the B-DFS considers only one copy of the puzzle and each state carries a list of actions that represents all the actions until reaching this state. The action list is important because it makes possible to backtrack along Fig. 4. Depth-First Search and the expansion process storing one copy of the board for each state. The nodes are expanded vertically. the states when the algorithm reaches a dead-end. In this case, B-DFS requires a list of actions to ”undo” every time that the node is stuck or when it cannot expand anymore. The relation of time and space in both DFS and B-DFS is represented by the BigO notation that demonstrates the relation between the branching factor (b) and maximum depth of the search tree (m). O(bm ) (1) Fig. 5. Exponential Function Complexity 2n. Increasing either the branching factor or the maximum depth of the search tree, the number of possibilities grows drastically. In the section V, there is a practical example that demonstrates this situation. IV. EXPERIMENTAL SET-UP Aiming to validate the hypothesis that B-DFS uses less memory than the DFS, both algorithms were used to solve a Sudoku puzzle that is a classic brute force problem. The ex- periments tested different puzzle sizes and tracked the memory allocation, number of nodes and time for each situation. All the puzzles were solved using three search algorithms: Breadth- First Search, Depth-First Search and Backtracking Depth-First Search. For a nine-by-nine Sudoku we have a time and space complexity as follows: O(981 ) (2)
- 3. Where 9 representsthe branching factor or the number of possibilities in each square and 81 represents the maximum depth of the search tree. To reduce the search tree space was applied a pruning technique that is explained in the next section. A. Pruning Pruning is important in terms of state space reduction. Sudoku demonstrates this idea when we show that the state- space size without pruning is equal to O(bm ). In a nine-by- nine puzzle, this number is 981 = 1.96627050475553 ∗ 1077 representing that finding a solution without pruning may be a problem in terms of memory and time requirements. The idea is checking the row, column and box to evaluate which numbers are available to fit the square without violating the rules. As you can see in fig. 6, the possibilities before pruning were the numbers 1, 2, 3, 4, 5, 6, 7, 8 and 9. However, applying the rule that the number cannot be repeated in a row, column and a box, the new possibilities become the numbers 7, 4 and 8. The possibilities were reduced from nine to three. As long as you repeat this process for every square, the puzzle complexity reduces drastically. Fig. 6. Pruning technique in a Sudoku puzzle. It reduced 33% of the space complexity in the first line of the graph. The results can be even better as long as the graph goes deeper. B. Algorithm and Coding As a motivation, a Sudoku Solver was coded to validate the different approaches covered throughout this paper. The algorithm was developed using Python v.3.4 and was based on the generic search algorithm from AIMA[2]. This algorithm fits for BFS, DFS and B-DFS, the difference is the node representation and how it is going to be stored in the queue. As explained in section III, BFS and DFS have the entire board as a node representation. Using Python is possible to consider the board as a list of lists which each of them contains one row of the puzzle. As a convention, it is a good practice to name the rows using a literal name and columns using numbers. For example, the element in the first row and first column can be called A1, the second element in a row and first column, B1. The variables formation are created as follows: rows = [ A , B , C , D , E , F , G , H , I ] cols = [ 1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 ] varNames = [x + y for x in rows for y in cols] With this structure the initial state can be stored and one action can be applied. It is important to keep in mind that only one action can be applied per time. Each action represents the application of one number into an empty spot, changing the previous board state and generating a new node. All the generated nodes pass for a test which checks the consistent of the board. If the board list is completely filled, the puzzle is solved. In the B-DFS, sometimes the sequence of actions lead to an inconsistence of the board. Then, it is required to backtrack the actions and go through another path. For this instance, the nodes have to store all the actions that were applied into the puzzle. The actions can be stored using a list containing the location and which action was applied. For example, if the number one was applied on the square located on the first line and second column, then the list are going to store (A2, 1). Algorithm 1 Search 1: procedure SEARCH(problem) returns a solution, or failure 2: node ← a node with STATE = problem.Initial 3: if problem.Goal −Test(node.STATE) then return Solution(node) 4: frontier ← a FIFO / LIFO queue with node element 5: explored ← an empty set 6: loop do: 7: if EMPTY(frontier) then return failure 8: node ← POP(frontier) 9: add node.STATE to explored 10: for each action in problem.ACTIONS(node.STATE) 11: child ← CHILD-NODE(problem, node, action) 12: if child.STATE is not in frontier then 13: if problem GOAL-TEST(child.STATE) then return SOLUTION(child) 14: frontier INSERT(child,frontier) 15: end if 16: end if 17: end if 18: end if 19: end procedure
- 4. V. RESULTS After solvingmore than 1000 puzzles from different characteristics as size of the puzzle and number of empty spaces, was possible to collect enough metrics to compare the results. The puzzles were solved using all the three algorithms and using a computer with the specifications as follows: Operational System: Windows 10 - 64bits Processor: Intel I7 - 4710 HQ - 2.5Ghz Memory: 16Gb - DDR3L Storage: 500Gb - SSD EVO850 The data was separated in easy and hard puzzles and normalized using a simple average algorithm. The data from the easy puzzles is presented in the table I and the hard puzzles in the table II The experiments concluded that B-DFS used less memory and time to solve all the puzzles when compared to others algorithms. According to the fig. 7, the BFS was the algorithm that required more memory allocation. Comparing both BFS and DFS, the DFS expanded less nodes in all puzzles fig. 9, thus it required less memory to store the nodes. The result depends on the location of the solution on the search tree. For example, if the solution is near the initial node or the does not grow quickly (e.g small number of children), then the BFS can be better than the DFS. It is important to notice that the DFS and B-DFS use the same expansion approach, then they reached the same number of expanded nodes. TABLE I RESULTS FOR DIFFERENT SUDOKU PUZZLES SIZES AND ALGORITHMS (EASY) Puzzle Size 6x6 9x9 10x10 Breadth-First Search Total allocated size [KiB] 7.3 24.2 27.9 Time to solve [s] 0.011 0.057 0.059 # of Nodes with pruning 58 129 149 Depth-First Search Total allocated size [KiB] 4.8 14.3 22.9 Time to solve [s] 0.007 0.026 0.044 # of Nodes with pruning 38 76 122 Backtracking Depth-First Search Total allocated size [KiB] 3.4 7.4 11.8 Time to solve [s] 0.005 0.025 0.029 # of Nodes with pruning 38 76 122 # of Backtracking 7 12 306 For a more detailed experiment, hard puzzles were tested exhaustively. The table II demonstrates that finding a solution for bigger and harder puzzles are challenging. According to the data collected, as long as the puzzle size increases, the number of nodes grow drastically and more memory is required. For the 16x16 puzzles, the BFS could not reach a solution and the computer ran out of memory after five hours running. On the other hand, the DFS and B-DFS solved the problem. The DFS required 2878s - approximately 48min and about 670mb (megabytes) of memory to solve the puzzle. The B-DFS solved the puzzle with only 1641s - approximately 27.3min and used only 420mb of memory. As discussed on Section IV, these algorithms follow an exponential equation, thus the branching factor changes the size of the search space quickly. From a 12x12 puzzle to a 16x16 there is a huge increase in the numbers of possible combinations. One way to demonstrate this increase is through the fig. 13, which the difference between the number of backtracking from 12x12 to 16x16 increased a lot. Fig. 7. The different levels of Memory Allocation according to the puzzle sizes and algorithm used. Fig. 8. Number of nodes related to different puzzle sizes and algorithms.
- 5. Fig. 9. Timeto reach the solution. The BDFS is faster than the BFS and DFS algorithms. TABLE II RESULTS FOR DIFFERENT SUDOKU PUZZLES SIZES AND ALGORITHMS (HARD) Puzzle Size 12x12 16x16 Breadth-First Search Total allocated size [KiB] 45408.8 Out of Memory Time to solve [s] 119.628 Out of Memory # of Nodes with pruning 242180 Out of Memory Depth-First Search Total allocated size [KiB] 20671.5 671508.0 Time to solve [s] 54.647 2878.601 # of Nodes with pruning 110248 3581376 Backtracking Depth-First Search Total allocated size [KiB] 33603 420099.2 Time to solve [s] 30.592 1641.31 # of Nodes with pruning 110248 3581376 # of Backtracking 33603 976601 VI. CONCLUSION AND FUTURE WORK As a conclusion, the Backtracking-Depth Search algorithm is considered an alternative to solve problems that have a big search-tree. However, is important to know that the search approach has limitations. Even though was possible to solve the most number of puzzles using the regular DFS and the B-DFS, these techniques belong to the group of brute force algorithms. It means that there is no knowledge or heuristic to help the algorithm to find a solution. To solve more sophisticated problems, a new approach may be needed. Algorithms such as Constraint Satisfaction and A* may be good alternatives to solve this particular problem. Fig. 10. Memory Allocation of two different hard puzzles. The BFS was not capable to solve the 16x16 (computer ran out of memory). Fig. 11. Number of nodes related to different puzzle sizes and algorithms. The BFS expanded more nodes than the others. Both DFS and B-DFS expanded the same number of nodes. BFS was not capable to solve the 16x16 puzzle. Fig. 12. Time to reach the solution. The BDFS was faster than all BFS and DFS algorithms.
- 6. Fig. 13. Timeto reach the solution. The BDFS was faster than all BFS and DFS algorithms. As a future work, the application of the CSP (Constraint Satisfaction Problem) to the Sudoku puzzle would be interesting. CSP uses constraints to reduce the domains of each variable which may be faster than using only the search algorithm. Note that CSP will not solve some puzzles by itself, then it will be needed to combine both techniques to find a solution. REFERENCES [1] Sudoku wikipedia https://en.wikipedia.org/wiki/sudoku. [2] Stuart J. Russell and Peter Norvig. Artificial Intelligence: A Modern Approach. Pearson Education, 2 edition, 2003. [3] Wen-Lin Yang and Wan-Ting Hong. Backtracking and best-first based channel assignment strategy for multicast in multi-radio wireless mesh networks. In Multimedia Technology (ICMT), 2011 International Confer- ence on, pages 2984–2987, July 2011. [4] Guoyu Zuo, Peng Zhang, and Junfei Qiao. Path planning algorithm based on sub-region for agricultural robot. In Informatics in Control, Automation and Robotics (CAR), 2010 2nd International Asia Conference on, volume 2, pages 197–200, March 2010.