





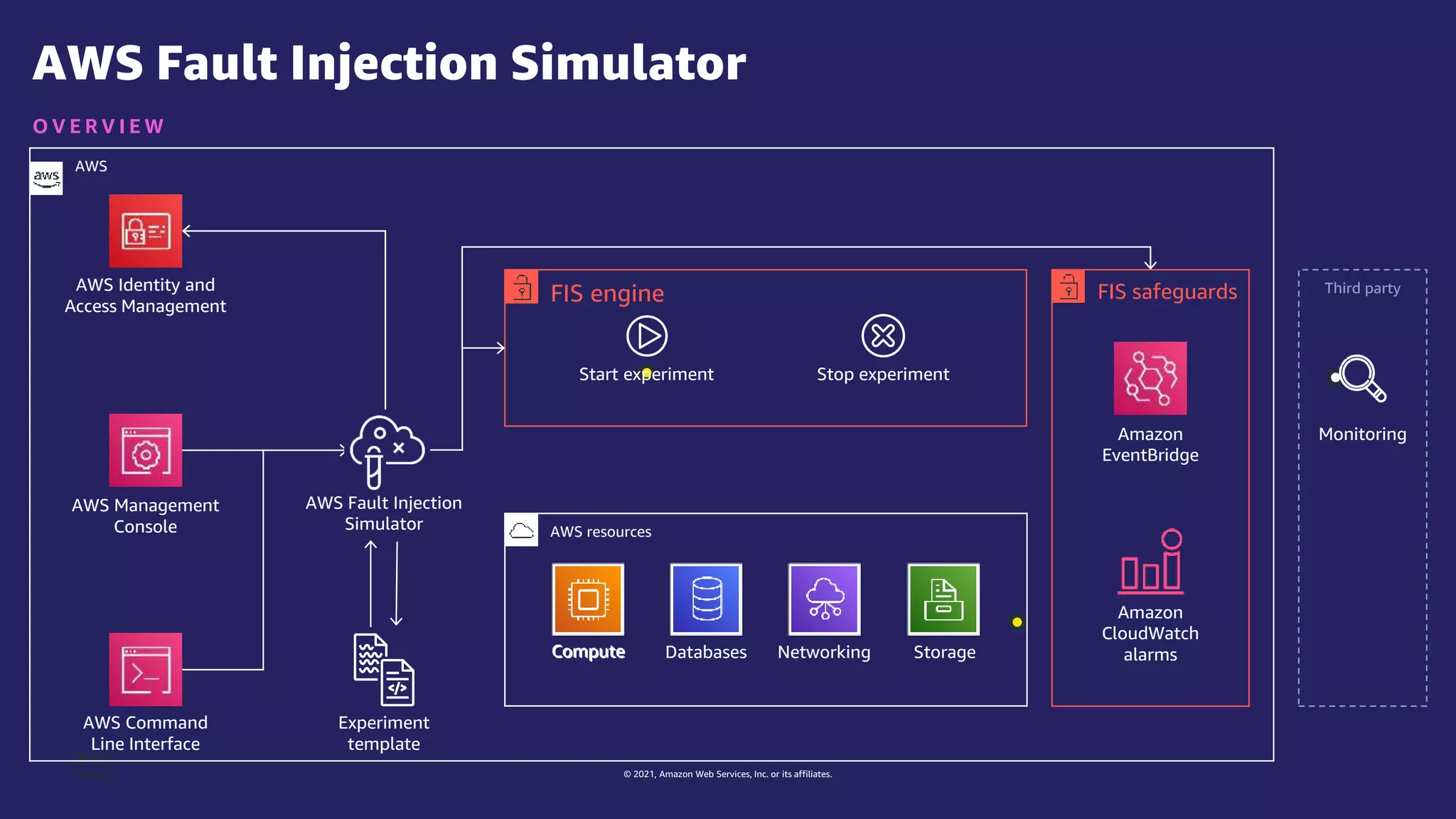





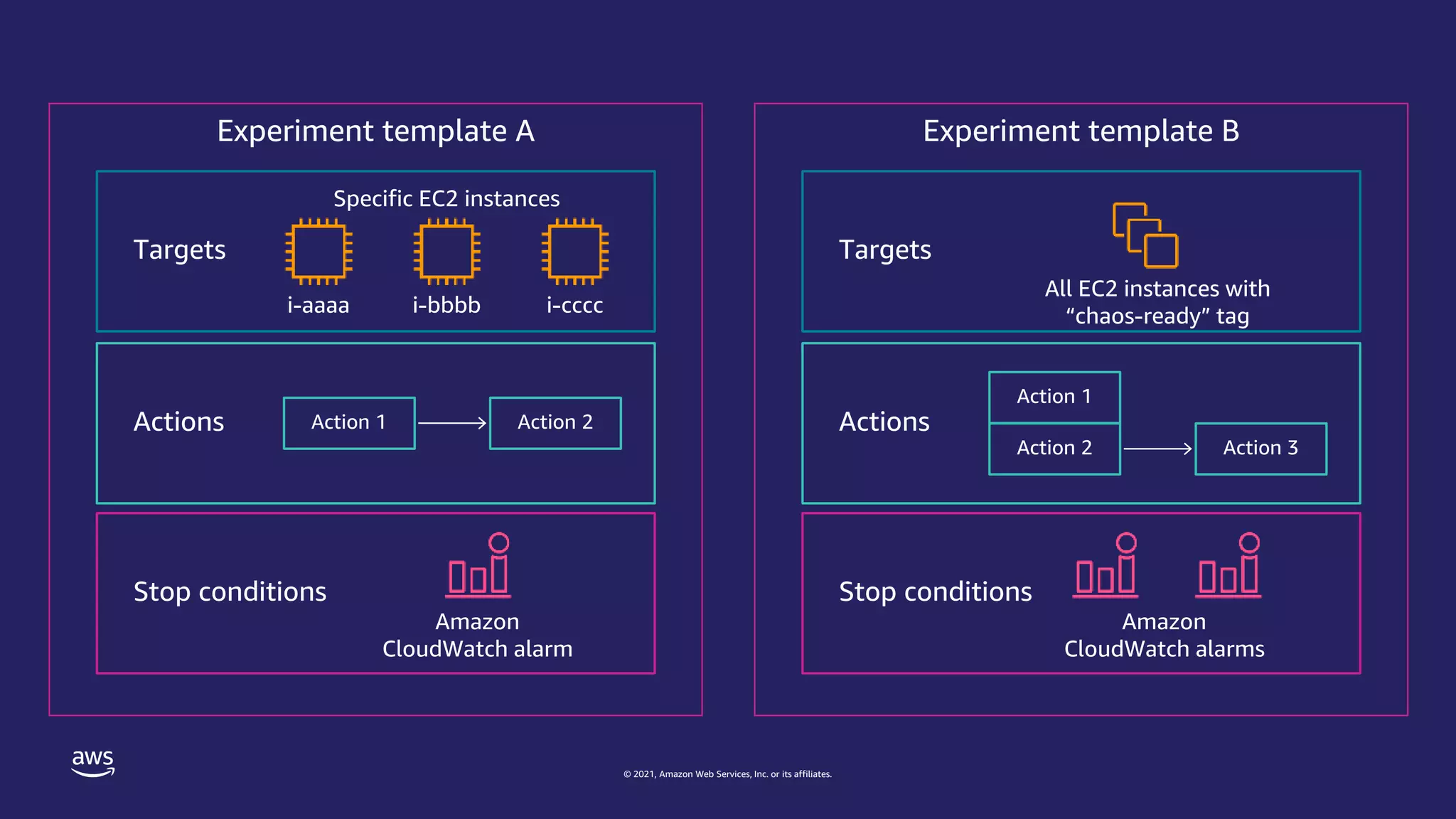

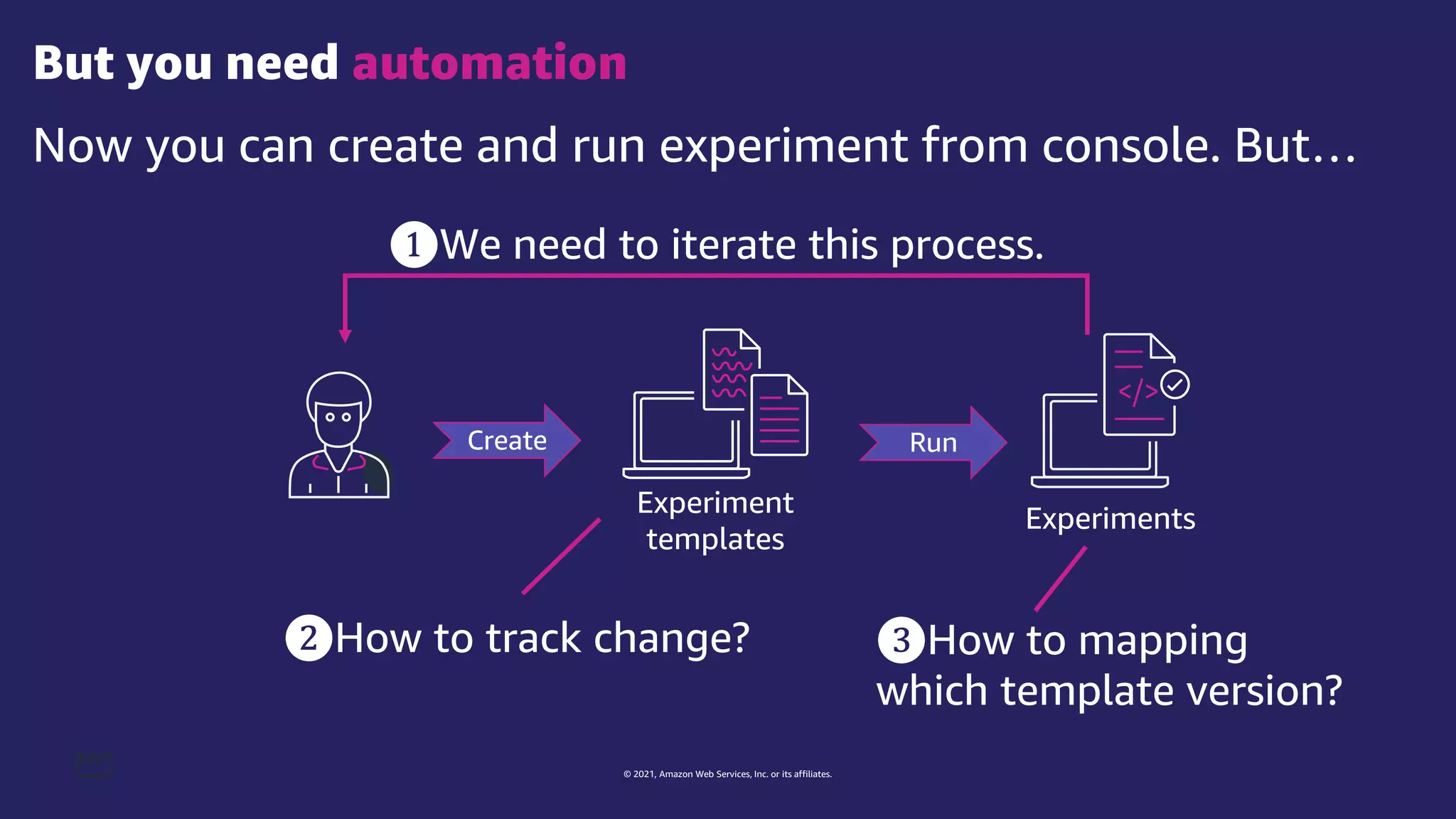

![© 2021, Amazon Web Services, Inc. or its affiliates.
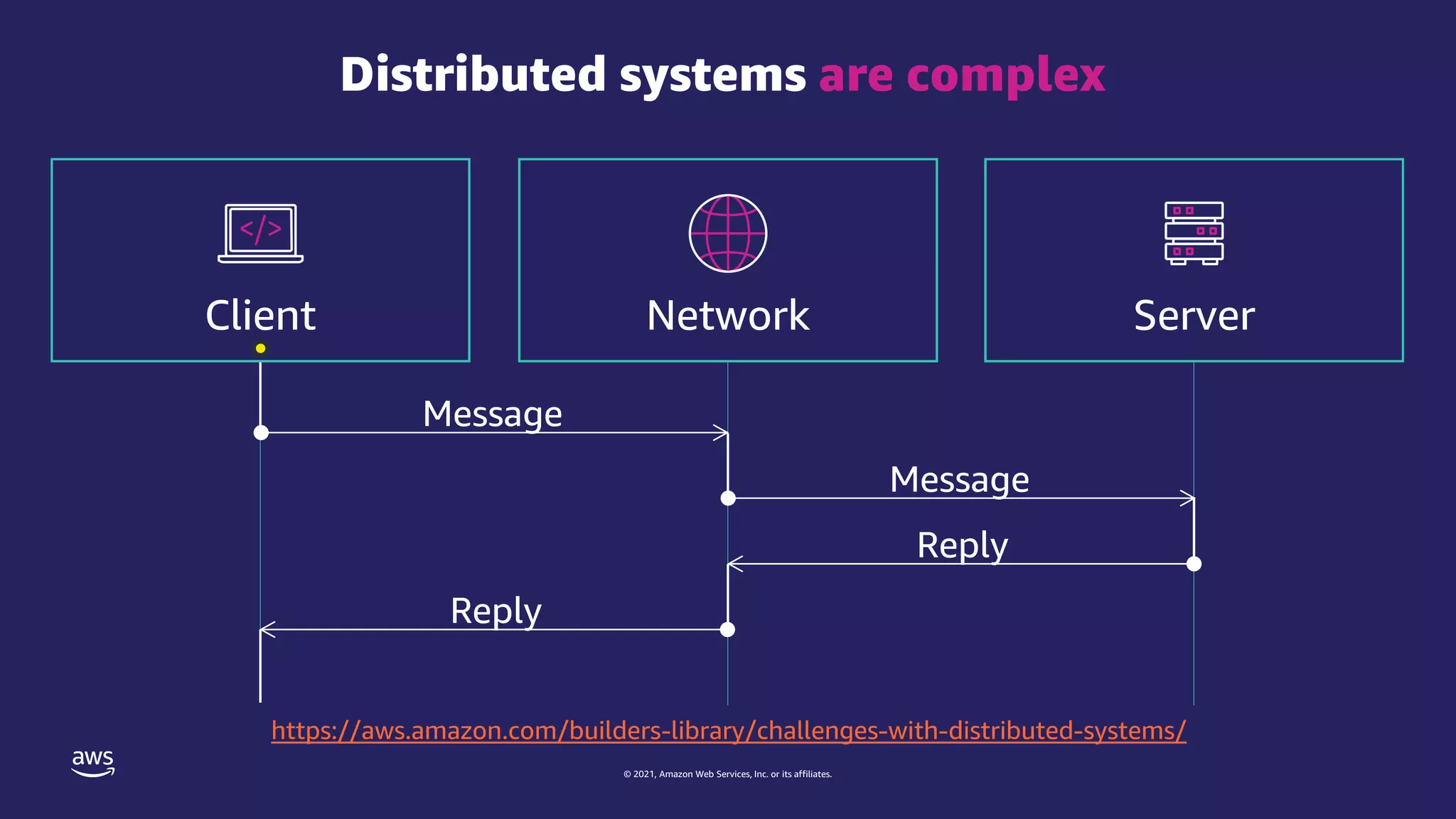
Experiment template as JSON
{
"tags": {
"Name": "StopAndRestartRandomeInstance"
},
"description": ”FIS Stop and Restart One Random Instance",
"roleArn": "arn:aws:iam::0123456789:role/MyFISExperimentRole",
"stopConditions": [
{
"source": "aws:cloudwatch:alarm",
"value": "arn:aws:cloudwatch:0123456789:alarm:No_Traffic"
}
],
"targets": {
"myInstance": {
"resourceTags": {
"Purpose": "chaos-ready"
},
"resourceType": "aws:ec2:instance",
"selectionMode": "COUNT(1)”
}
},
"actions": {
"StopInstances": {
"actionId": "aws:ec2:stop-instances",
"description": "stop the instances",
"parameters": {
"startInstancesAfterDuration": ”PT5M"
},
"targets": {
"Instances": "myInstance"
}
}
}
}
Description
IAM role
Stop conditions
Targets
Actions
Name](https://image.slidesharecdn.com/jawspankrationletwriteyourexperimenttemplate-211121000622/75/AWS-FIS-21-2048.jpg)




![© 2021, Amazon Web Services, Inc. or its affiliates.
Actions
"actions": {
"StopInstances": {
"actionId": "aws:ec2:stop-instances",
"parameters": {
"startInstancesAfterDuration": ”PT5M"
},
"targets": {
"Instances": "AllTaggedInstances"
}
},
"TerminateInstances": {
"actionId": "aws:ec2:terminate-instances",
"parameters": {},
"targets": {
"Instances": "RandomInstancesInAZ"
},
"startAfter": [
"StopInstances"
]
}
}](https://image.slidesharecdn.com/jawspankrationletwriteyourexperimenttemplate-211121000622/75/AWS-FIS-26-2048.jpg)
![© 2021, Amazon Web Services, Inc. or its affiliates.
Actions
"actions": {
"StopInstances": {
"actionId": "aws:ec2:stop-instances",
"parameters": {
"startInstancesAfterDuration": ”PT5M"
},
"targets": {
"Instances": "AllTaggedInstances"
}
},
"TerminateInstances": {
"actionId": "aws:ec2:terminate-instances",
"parameters": {},
"targets": {
"Instances": "RandomInstancesInAZ"
},
"startAfter": [
"StopInstances"
]
}
}
There are two actions
StopInstances
TerminateInstances](https://image.slidesharecdn.com/jawspankrationletwriteyourexperimenttemplate-211121000622/75/AWS-FIS-27-2048.jpg)
![© 2021, Amazon Web Services, Inc. or its affiliates.
Actions
"actions": {
"StopInstances": {
"actionId": "aws:ec2:stop-instances",
"parameters": {
"startInstancesAfterDuration": ”PT5M"
},
"targets": {
"Instances": "AllTaggedInstances"
}
},
"TerminateInstances": {
"actionId": "aws:ec2:terminate-instances",
"parameters": {},
"targets": {
"Instances": "RandomInstancesInAZ"
},
"startAfter": [
"StopInstances"
]
}
}
Specify action identifier.
Each AWS FIS action has an identifier
with the following format:
aws:<service-name>:<action-type>
See the document for details.
https://docs.aws.amazon.com/fis/latest/userguide/fis-
actions-reference.html](https://image.slidesharecdn.com/jawspankrationletwriteyourexperimenttemplate-211121000622/75/AWS-FIS-28-2048.jpg)
![© 2021, Amazon Web Services, Inc. or its affiliates.
Actions
"actions": {
"StopInstances": {
"actionId": "aws:ec2:stop-instances",
"parameters": {
"startInstancesAfterDuration": ”PT5M"
},
"targets": {
"Instances": "AllTaggedInstances"
}
},
"TerminateInstances": {
"actionId": "aws:ec2:terminate-instances",
"parameters": {},
"targets": {
"Instances": "RandomInstancesInAZ"
},
"startAfter": [
"StopInstances"
]
}
}
Some of actions have parameters.
You can check it in the document.
https://docs.aws.amazon.com/fis/latest/userguide/fis-
actions-reference.html](https://image.slidesharecdn.com/jawspankrationletwriteyourexperimenttemplate-211121000622/75/AWS-FIS-29-2048.jpg)
![© 2021, Amazon Web Services, Inc. or its affiliates.
Actions
"actions": {
"StopInstances": {
"actionId": "aws:ec2:stop-instances",
"parameters": {
"startInstancesAfterDuration": ”PT5M"
},
"targets": {
"Instances": "AllTaggedInstances"
}
},
"TerminateInstances": {
"actionId": "aws:ec2:terminate-instances",
"parameters": {},
"targets": {
"Instances": "RandomInstancesInAZ"
},
"startAfter": [
"StopInstances"
]
}
}
You need to specify targets.
What is a target will be described later.](https://image.slidesharecdn.com/jawspankrationletwriteyourexperimenttemplate-211121000622/75/AWS-FIS-30-2048.jpg)
![© 2021, Amazon Web Services, Inc. or its affiliates.
Actions
"actions": {
"StopInstances": {
"actionId": "aws:ec2:stop-instances",
"parameters": {
"startInstancesAfterDuration": ”PT5M"
},
"targets": {
"Instances": "AllTaggedInstances"
}
},
"TerminateInstances": {
"actionId": "aws:ec2:terminate-instances",
"parameters": {},
"targets": {
"Instances": "RandomInstancesInAZ"
},
"startAfter": [
"StopInstances"
]
}
}
You can specify the order of actions
with this attribute.](https://image.slidesharecdn.com/jawspankrationletwriteyourexperimenttemplate-211121000622/75/AWS-FIS-31-2048.jpg)
![© 2021, Amazon Web Services, Inc. or its affiliates.
Actions
"actions": {
"StopInstances": {
"actionId": "aws:ec2:stop-instances",
"parameters": {
"startInstancesAfterDuration": ”PT5M"
},
"targets": {
"Instances": "AllTaggedInstances"
}
},
"TerminateInstances": {
"actionId": "aws:ec2:terminate-instances",
"parameters": {},
"targets": {
"Instances": "RandomInstancesInAZ"
},
"startAfter": [
"StopInstances"
]
}
}](https://image.slidesharecdn.com/jawspankrationletwriteyourexperimenttemplate-211121000622/75/AWS-FIS-32-2048.jpg)
![© 2021, Amazon Web Services, Inc. or its affiliates.
"targets": {
"AllTaggedInstances": {
"resourceType": "aws:ec2:instance",
"resourceTags": {
"Purpose": "chaos-ready"
},
"selectionMode": "ALL"
},
"RandomInstancesInAZ": {
"resourceType": "aws:ec2:instance",
"resourceTags": {
"Purpose": "chaos-ready"
},
filters: [
{
path: 'Placement.AvailabilityZone’,
values: [‘us.east.1a’]
},
{
path: 'State.Name’,
values: ['running’]
}
]
"selectionMode": ”PERCENT(50)"
}
Targets](https://image.slidesharecdn.com/jawspankrationletwriteyourexperimenttemplate-211121000622/75/AWS-FIS-33-2048.jpg)
![© 2021, Amazon Web Services, Inc. or its affiliates.
"targets": {
"AllTaggedInstances": {
"resourceType": "aws:ec2:instance",
"resourceTags": {
"Purpose": "chaos-ready"
},
"selectionMode": "ALL"
},
"RandomInstancesInAZ": {
"resourceType": "aws:ec2:instance",
"resourceTags": {
"Purpose": "chaos-ready"
},
filters: [
{
path: 'Placement.AvailabilityZone’,
values: [‘us.east.1a’]
},
{
path: 'State.Name’,
values: ['running’]
}
]
"selectionMode": "PERCENT(50)"
}
Targets
There are two targets
AllTarggedInstances
RandomInstancesInAZ](https://image.slidesharecdn.com/jawspankrationletwriteyourexperimenttemplate-211121000622/75/AWS-FIS-34-2048.jpg)
![© 2021, Amazon Web Services, Inc. or its affiliates.
"targets": {
"AllTaggedInstances": {
"resourceType": "aws:ec2:instance",
"resourceTags": {
"Purpose": "chaos-ready"
},
"selectionMode": "ALL"
},
"RandomInstancesInAZ": {
"resourceType": "aws:ec2:instance",
"resourceTags": {
"Purpose": "chaos-ready"
},
filters: [
{
path: 'Placement.AvailabilityZone’,
values: [‘us.east.1a’]
},
{
path: 'State.Name’,
values: ['running’]
}
]
"selectionMode": "PERCENT(50)"
}
Targets
You must specify exactly one resource type.
And when you specify a target for an action,
the target must be the resource type supported by the action
Resource types supported by AWS FIS
• aws:ec2:instance
• aws:ec2:spot-instance
• aws:ecs:cluster
• aws:eks:nodegroup
• aws:iam:role
• aws:rds:cluster
• aws:rds:db](https://image.slidesharecdn.com/jawspankrationletwriteyourexperimenttemplate-211121000622/75/AWS-FIS-35-2048.jpg)
![© 2021, Amazon Web Services, Inc. or its affiliates.
"targets": {
"AllTaggedInstances": {
"resourceType": "aws:ec2:instance",
"resourceTags": {
"Purpose": "chaos-ready"
},
"selectionMode": "ALL"
},
"RandomInstancesInAZ": {
"resourceType": "aws:ec2:instance",
"resourceTags": {
"Purpose": "chaos-ready"
},
filters: [
{
path: 'Placement.AvailabilityZone’,
values: [‘us.east.1a’]
},
{
path: 'State.Name’,
values: ['running’]
}
]
"selectionMode": "PERCENT(50)"
}
Targets You can use tags to specify AWS resources for target.
Of course you can use ARN using resourceArns
attribute instead tag.](https://image.slidesharecdn.com/jawspankrationletwriteyourexperimenttemplate-211121000622/75/AWS-FIS-36-2048.jpg)
![© 2021, Amazon Web Services, Inc. or its affiliates.
"targets": {
"AllTaggedInstances": {
"resourceType": "aws:ec2:instance",
"resourceTags": {
"Purpose": "chaos-ready"
},
"selectionMode": "ALL"
},
"RandomInstancesInAZ": {
"resourceType": "aws:ec2:instance",
"resourceTags": {
"Purpose": "chaos-ready"
},
filters: [
{
path: 'Placement.AvailabilityZone’,
values: [‘us.east.1a’]
},
{
path: 'State.Name’,
values: ['running’]
}
]
"selectionMode": "PERCENT(50)"
}
Targets
You can use resource filter to specify resource with specific attributes.
You can describe the path to reach an attribute in the output of the
Describe action for a resource.
(ex: for aws:ec2:instance , DescribeInstances API action is used)
More details , see following document:
https://docs.aws.amazon.com/fis/latest/userguide/targets.html#target-filters](https://image.slidesharecdn.com/jawspankrationletwriteyourexperimenttemplate-211121000622/75/AWS-FIS-37-2048.jpg)
![© 2021, Amazon Web Services, Inc. or its affiliates.
"targets": {
"AllTaggedInstances": {
"resourceType": "aws:ec2:instance",
"resourceTags": {
"Purpose": "chaos-ready"
},
"selectionMode": "ALL"
},
"RandomInstancesInAZ": {
"resourceType": "aws:ec2:instance",
"resourceTags": {
"Purpose": "chaos-ready"
},
filters: [
{
path: 'Placement.AvailabilityZone’,
values: [‘us.east.1a’]
},
{
path: 'State.Name’,
values: ['running’]
}
]
"selectionMode": "PERCENT(50)"
}
Targets
You can scope identified resources using selectionMode.
Default is "ALL”(all identified resources will be target).
You can use two other methods to scope.
• COUNT(n)
• PERCENT(n)](https://image.slidesharecdn.com/jawspankrationletwriteyourexperimenttemplate-211121000622/75/AWS-FIS-38-2048.jpg)
![© 2021, Amazon Web Services, Inc. or its affiliates.
"targets": {
"AllTaggedInstances": {
"resourceType": "aws:ec2:instance",
"resourceTags": {
"Purpose": "chaos-ready"
},
"selectionMode": "ALL"
},
"RandomInstancesInAZ": {
"resourceType": "aws:ec2:instance",
"resourceTags": {
"Purpose": "chaos-ready"
},
filters: [
{
path: 'Placement.AvailabilityZone’,
values: [‘us.east.1a’]
},
{
path: 'State.Name’,
values: ['running’]
}
]
"selectionMode": ”PERCENT(50)"
}
Targets](https://image.slidesharecdn.com/jawspankrationletwriteyourexperimenttemplate-211121000622/75/AWS-FIS-39-2048.jpg)
![© 2021, Amazon Web Services, Inc. or its affiliates.
"stopConditions": [
{
"source": "aws:cloudwatch:alarm",
"value": "arn:aws:cloudwatch:0123456789:alarm:No_Traffic"
}
],
Stop conditions
You can specify CloudWatch alarm
to stop your experiment if it reach the threshold. “none” or “aws:cloudwatch:alarm ”
ARN of the CloudWatch alarm.
(It’s required if the source is a CloudWatch alarm.)](https://image.slidesharecdn.com/jawspankrationletwriteyourexperimenttemplate-211121000622/75/AWS-FIS-40-2048.jpg)
![© 2021, Amazon Web Services, Inc. or its affiliates.
Experiment template as JSON
{
"tags": {
"Name": "StopAndRestartRandomeInstance"
},
"description": ”FIS Stop and Restart One Random Instance",
"roleArn": "arn:aws:iam::0123456789:role/MyFISExperimentRole",
"stopConditions": [
{
"source": "aws:cloudwatch:alarm",
"value": "arn:aws:cloudwatch:0123456789:alarm:No_Traffic"
}
],
"targets": {
"myInstance": {
"resourceTags": {
"Purpose": "chaos-ready"
},
"resourceType": "aws:ec2:instance",
"selectionMode": "COUNT(1)”
}
},
"actions": {
"StopInstances": {
"actionId": "aws:ec2:stop-instances",
"description": "stop the instances",
"parameters": {
"startInstancesAfterDuration": ”PT5M"
},
"targets": {
"Instances": "myInstance"
}
}
}
}
Description
IAM role
Stop conditions
Targets
Actions
Name](https://image.slidesharecdn.com/jawspankrationletwriteyourexperimenttemplate-211121000622/75/AWS-FIS-41-2048.jpg)

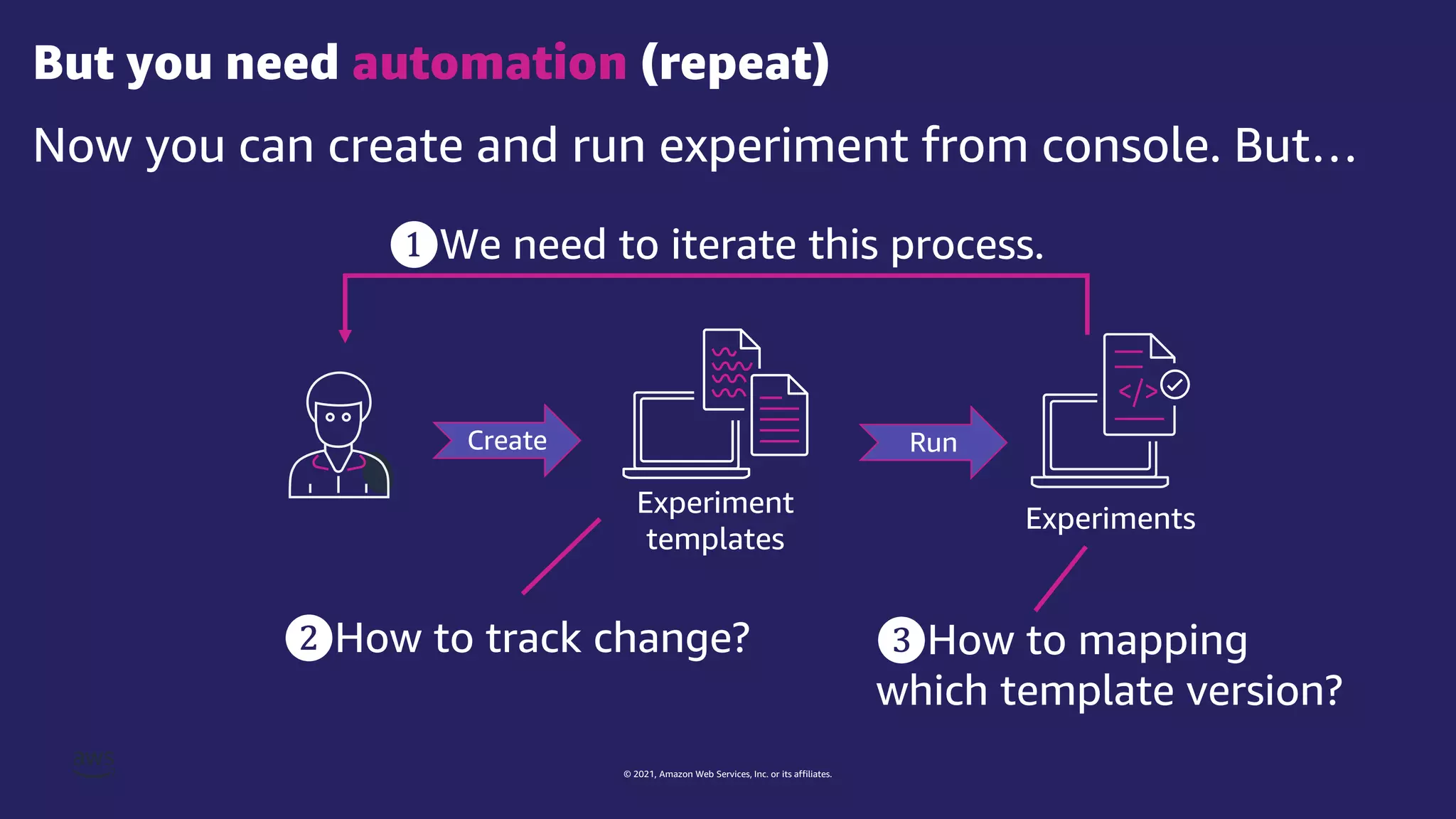
![© 2021, Amazon Web Services, Inc. or its affiliates.
Using VCS to track change experiment template
{
"tags": { "Name": "StopAndRestartRandomeInstance"},
"description": ”FIS Stop and Restart One Random Instance",
"roleArn": "arn:aws:iam::0123456789:role/MyFISExperimentRole",
"stopConditions": [{
"source": ”none",
}],
...
}
{
"tags": { "Name": "StopAndRestartRandomeInstance” },
"description": ”FIS Stop and Restart One Random Instance",
"roleArn": "arn:aws:iam::0123456789:role/MyFISExperimentRole",
"stopConditions": [{
"source": "aws:cloudwatch:alarm",
"value": "arn:aws:cloudwatch:0123456789:alarm:No_Traffic"
}],
...
}
Version 1:
Version 2:
Add stop condition
Github
Bitbucket
Git repository
AWS CodeCommit
etc…](https://image.slidesharecdn.com/jawspankrationletwriteyourexperimenttemplate-211121000622/75/AWS-FIS-44-2048.jpg)
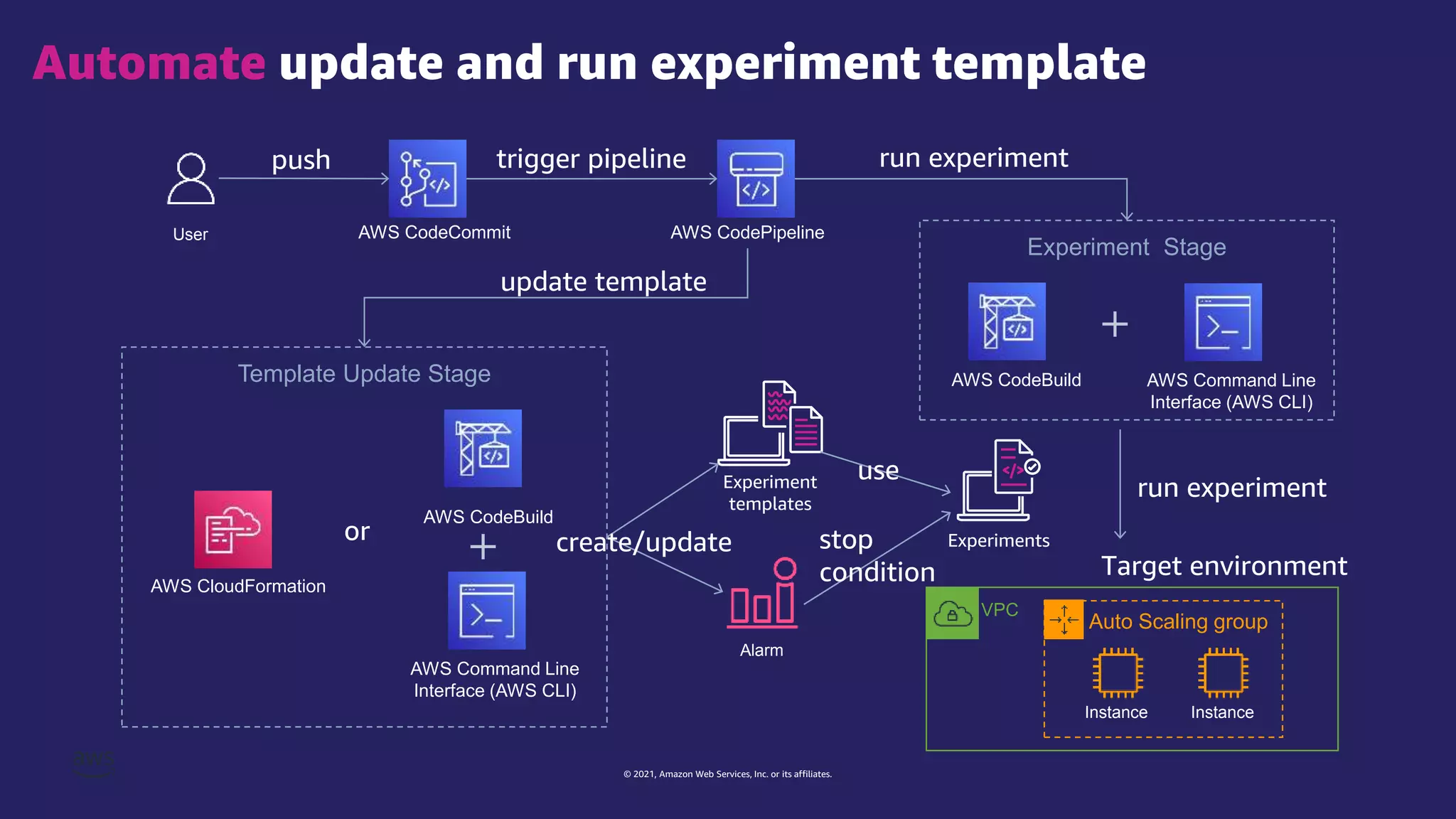


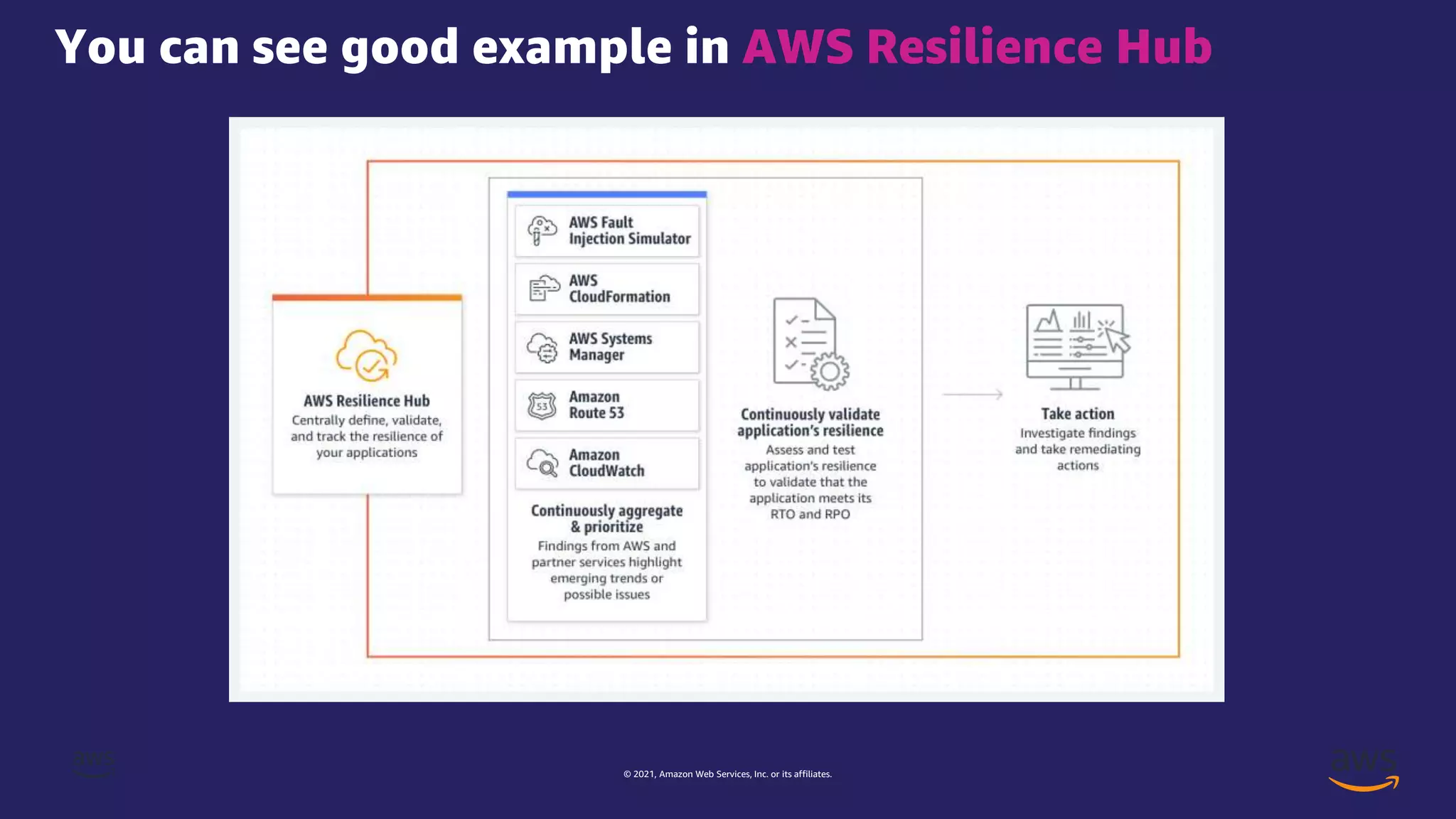


The document discusses experiment templates for AWS Fault Injection Simulator (FIS). It explains that experiment templates define actions and targets for chaos engineering experiments using FIS. The document provides examples of JSON templates that specify actions like stopping EC2 instances, targets like instances tagged for chaos, and ordering of actions. It also describes the required and optional fields for defining actions, targets, and experiments in templates to automate chaos experiments with FIS.




















![[AWSマイスターシリーズ] リザーブドインスタンス&スポットインスタンス](https://cdn.slidesharecdn.com/ss_thumbnails/20130213aws-meister-reloaded-rispotpublic-130214051435-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)





![[A23] Oracle移行を簡単に。レプリケーションテクノロジーを使いこなす by Keishi Miyachi](https://cdn.slidesharecdn.com/ss_thumbnails/a23iti-140625000518-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
















































