Downloaded 22 times









![usage: listASGs.py [-h] [-v] [-e ENVIRONMENT] [-n NAME] [-r REGION] [-a {suspend,resume,set,start,stop,store}] [-w]
[-c CAPACITY] [--excludes EXCLUDES] [-k]
List Autoscaling Groups and Act on them
optional arguments:
-h, --help show this help message and exit
-v, --verbose Up the displayed messages or provide more detail
-e ENVIRONMENT, --environment ENVIRONMENT
Set the environment variable for the filter. You can chose 'all' as well as dev/qa/prd/ops/int/...
-n NAME, --name NAME Set the base stack name for the filter. Default is everything
-r REGION, --region REGION
Set the region. Default is everything
-a {suspend,resume,set,start,stop,store}, --action {suspend,resume,set,start,stop,store}
Determines the action for the script to take
-w, --html Print output in HTML format rather than text
-c CAPACITY, --capacity CAPACITY
Specifies the value for capacity. Enter as '#/#/#' in
min, desired, max order
--excludes EXCLUDES Enter a regular expression to exclude matchnames
-k, --kind Display the underlaying Instance Type](https://image.slidesharecdn.com/costcontrolpresentation2-150801031050-lva1-app6891/85/AWS-Cost-Control-26-320.jpg)

![ i-bdf03614 --> ansible-xyz-AnsibleBob (m3.medium)
i-46d4e196 --> edda-ops1-netflixEdda (m3.xlarge)
i-1a5550c9 --> emr-prd1-CORE (m1.medium) [SPOT]
i-1cd2a2b4 --> emr-prd1-CORE (m3.xlarge) [SPOT]
i-36d3a39e --> emr-prd1-CORE (m3.xlarge) [SPOT]
i-37d3a39f --> emr-prd1-CORE (m3.xlarge) [SPOT]
i-38d3a390 --> emr-prd1-CORE (m3.xlarge) [SPOT]
i-41dca992 --> emr-prd1-CORE (m1.medium) [SPOT]
i-1dd3a3b5 --> emr-prd1-MASTER (m3.xlarge)
i-215550f2 --> emr-prd1-MASTER (m1.medium)
i-69dca9ba --> emr-prd1-MASTER (m1.medium)
i-48fbcc9b --> emr-prd1-TASK (m1.medium) [SPOT]
i-62fccbb1 --> emr-prd1-TASK (m1.medium) [SPOT]
i-83f9ce50 --> emr-prd1-TASK (m1.medium) [SPOT]
i-84fccb57 --> emr-prd1-TASK (m1.medium) [SPOT]
i-86f9ce55 --> emr-prd1-TASK (m1.medium) [SPOT]
i-8afccb59 --> emr-prd1-TASK (m1.medium) [SPOT]
i-8df9ce5e --> emr-prd1-TASK (m1.medium) [SPOT]
i-8ef9ce5d --> emr-prd1-TASK (m1.medium) [SPOT]
i-aafbcc79 --> emr-prd1-TASK (m1.medium) [SPOT]
i-acfbcc7f --> emr-prd1-TASK (m1.medium) [SPOT]
i-1058a8fe --> experts-beta-experts (c3.xlarge)
i-f00f1b01 --> ftp-ops1-ftp (m3.medium)
i-a6106f75 --> gene-gene-gene (c3.2xlarge) [SPOT]
i-f1c5510b --> internal-access1a-bubblewrapp (m3.medium)
i-97f6676a --> jenkins-ops1-jenkins (c3.large)
i-945ada7d --> lamp-dev-lamptest (m3.medium)
i-8fd25f66 --> logstash-ops-logstash (m3.xlarge) [SPOT]
i-8c8c8ca3 --> nissolr-prd1-nissolrStandAlone-Cloud1 (i2.xlarge)
i-028f8f2d --> nissolr-prd1-nissolrStandAlone-Cloud2 (i2.xlarge)
i-2be6e504 --> nissolr-prd1-nissolrStandAlone-Cloud3 (i2.xlarge)
i-67d59ab1 --> nissolr-prd1-zookeeper1 (t1.micro)
i-afcbac80 --> recommend-dev2-recommend (m3.medium)](https://image.slidesharecdn.com/costcontrolpresentation2-150801031050-lva1-app6891/85/AWS-Cost-Control-29-320.jpg)
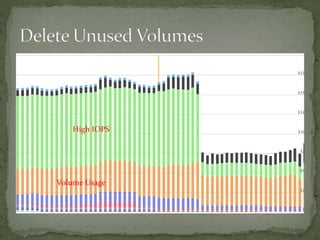
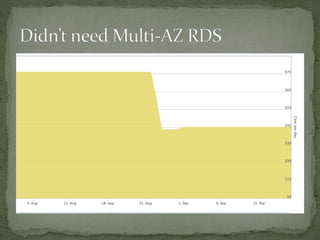
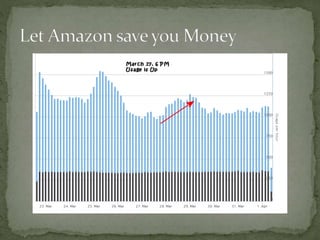
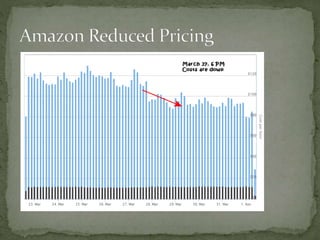
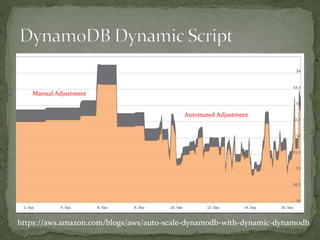
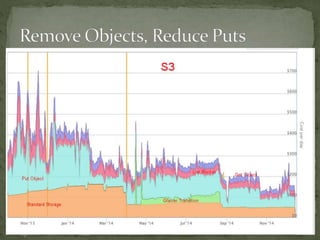
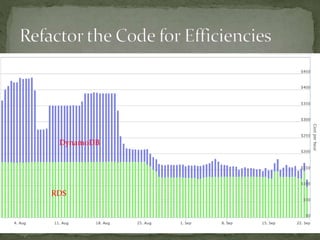
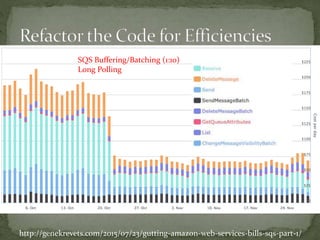
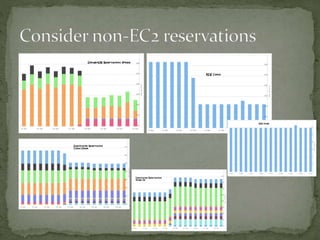

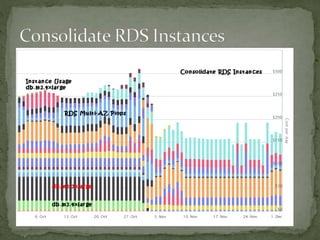
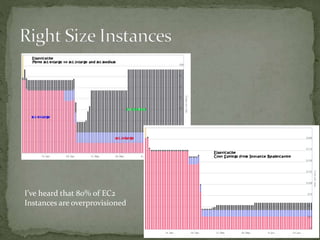
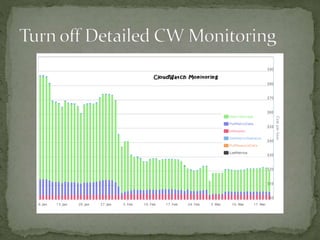

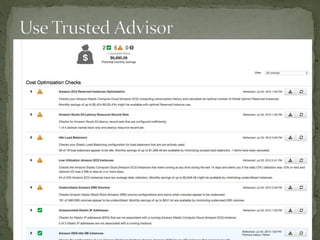
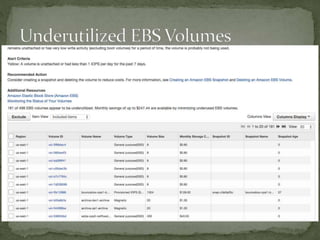

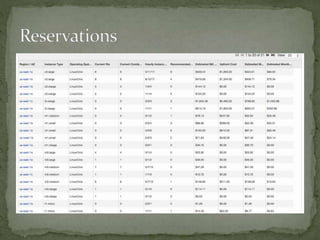
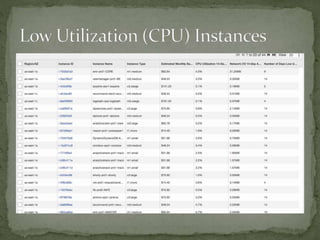
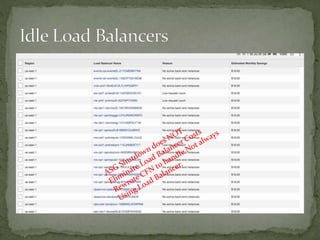
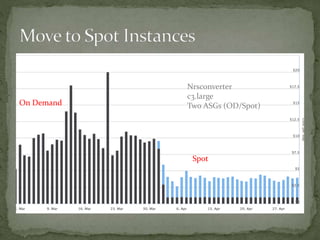
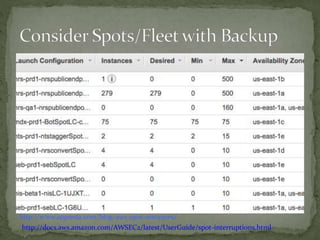

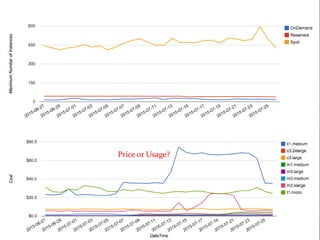
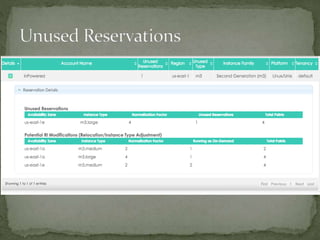
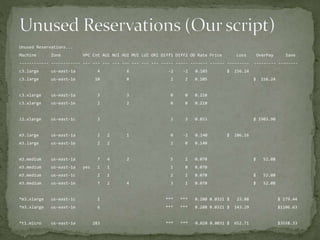

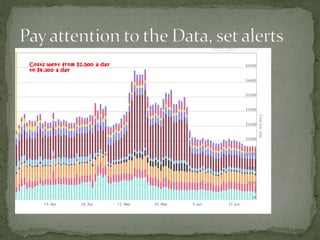
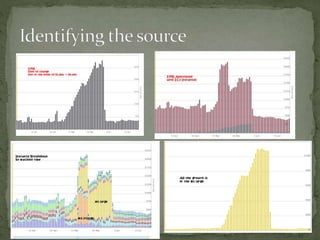







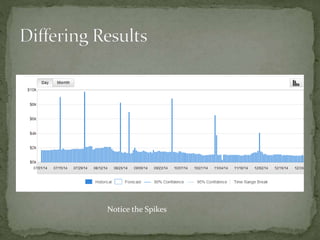
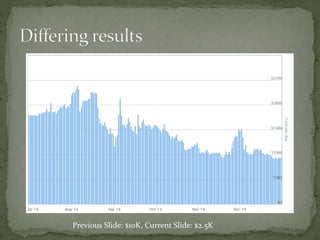
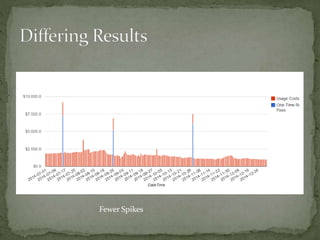
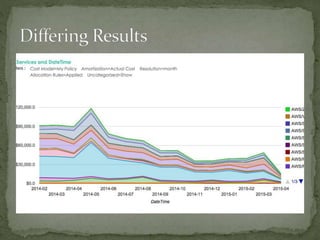
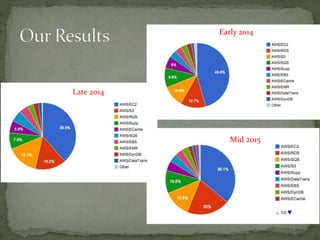
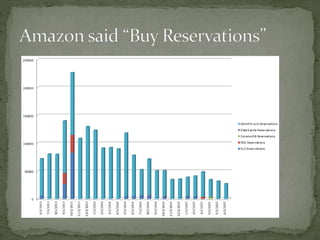
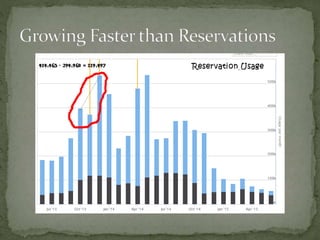
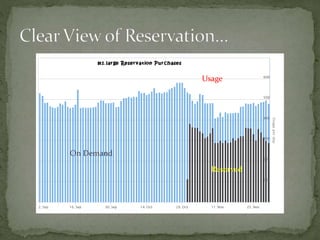
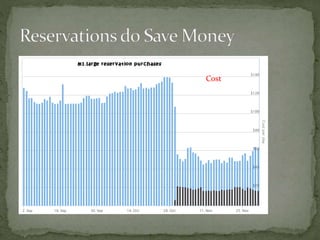
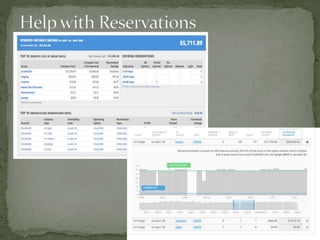
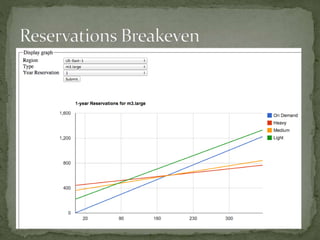
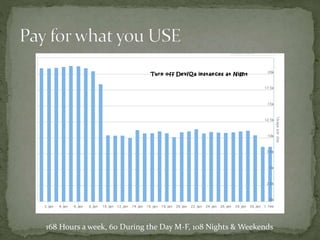
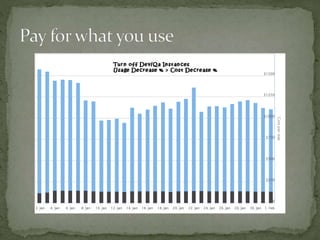
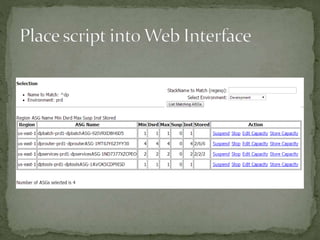
The document provides a comprehensive overview of cost management strategies for AWS services, emphasizing the importance of tracking various service costs such as EC2, RDS, S3, and others. It suggests tools like AWS Cost Explorer and Teevity for visibility, along with practical tips for reducing expenses, such as using tagging, proper instance management, and leveraging reserved instances. Additionally, it highlights the necessity of creating a culture of cost awareness and continuous monitoring to optimize AWS costs effectively.




















![ManageYourCostsAndGovernYourUsageOnAWS[1]](https://cdn.slidesharecdn.com/ss_thumbnails/cf3985ff-4d18-4267-8d6c-8f6235ce73aa-160606135134-thumbnail.jpg?width=640&height=640&fit=bounds)

































