The document provides information about Amazon EC2 instances, including:
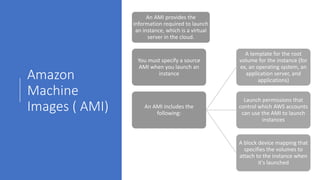
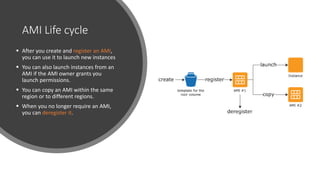
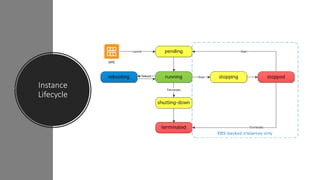
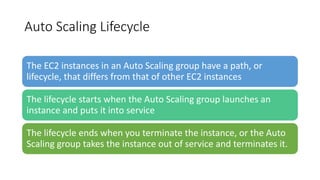
- EC2 instances are virtual computing environments that run in the AWS cloud. They are launched using Amazon Machine Images which contain the operating system and software.
- Instance types determine the hardware specifications of an instance and there are different types optimized for compute, memory, storage or accelerated computing.
- Security groups act as virtual firewalls that control inbound and outbound traffic using rules.
- Instances have private IP addresses for communication within a VPC and may be assigned public IP addresses for internet access.


















































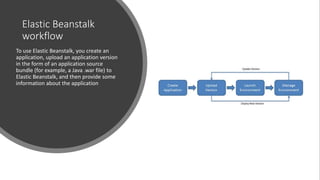















![[AWS Builders] AWS와 함께하는 클라우드 컴퓨팅](https://cdn.slidesharecdn.com/ss_thumbnails/awsbuildersaws101webinarcloudcomputingchoelkang-190305081301-thumbnail.jpg?width=640&height=640&fit=bounds)


































































