Download to read offline












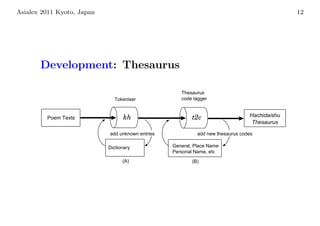
![Asialex 2011 Kyoto, Japan 13
(A) Corpus: Poems (OP)
KW00029800|A|KANEMI NO ¯=kanemi no ¯
O o
KW00029800|B|Tatsutahime[NOUN-PLNAME:TATSUTAHIME]/→
tamukuru[KASHIMO2-ATTR:TAMUkuru],kami[NOUN:KAMI]→
no[SUB]are[RAHEN-REAL]ba[CAUS]koso[KP]/→
aki[NOUN:AKI]no[CON],konoha[NOUN:KOnoHA]no[SUB]/→
nusa[NOUN:NUSA]to[P-CRD],chiru[RA4DAN-FF:CHIru]→
rame[CJR-REAL]/
Figure 2: Format of the database of a poem: → indicates continuing to the
next line without breaks; the first line, which includes |A|, indicates
the name of the poet; the second line which includes |B|, indicates
the contents of the poem and added information.](https://image.slidesharecdn.com/asialex201103slide02-111211080321-phpapp02/85/Asialex201103slide02-13-320.jpg)

![Asialex 2011 Kyoto, Japan 15
(B) Tokenisation:
original text
↓
tokenising
/ / / /[ ]/ / / / / / / / / /[ ]
↓
converting into predicative form
/ / / /[ ]/ / / / / / / / / /[ ]
Figure 4: Tokenisation of poem texts](https://image.slidesharecdn.com/asialex201103slide02-111211080321-phpapp02/85/Asialex201103slide02-15-320.jpg)





![Asialex 2011 Kyoto, Japan 22
Residual
CT ( ) ( )
OP — —— — — — — — — — — — — — —— —
CT ( ) ( ) ( ) ( )
OP — — [ ] — — — — — —
Figure 11: Example of the matching process in the case of kks 298 in Ko-
machiya (1982)](https://image.slidesharecdn.com/asialex201103slide02-111211080321-phpapp02/85/Asialex201103slide02-22-320.jpg)
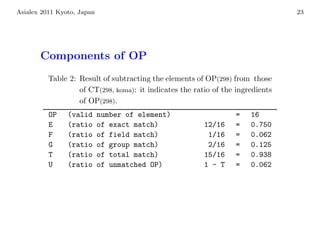







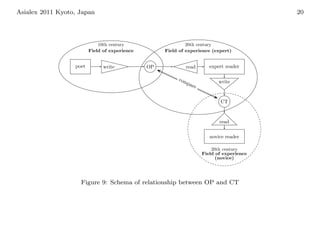
The document discusses: 1. The development of a thesaurus of classical Japanese poetic vocabulary to better understand the connotations of words over time and how their usage changed. 2. The thesaurus is being developed using materials from the Hachidaishu, eight anthologies of Japanese poetry compiled between 905-2105 CE. 3. The thesaurus development involves processing the poetry data through a tokenizer, code converter, and other tools to extract and categorize the vocabulary terms according to their attributes.



















![Notes on Hokusai's prints [MetMuseum]](https://cdn.slidesharecdn.com/ss_thumbnails/10797802-120104092536-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)


















