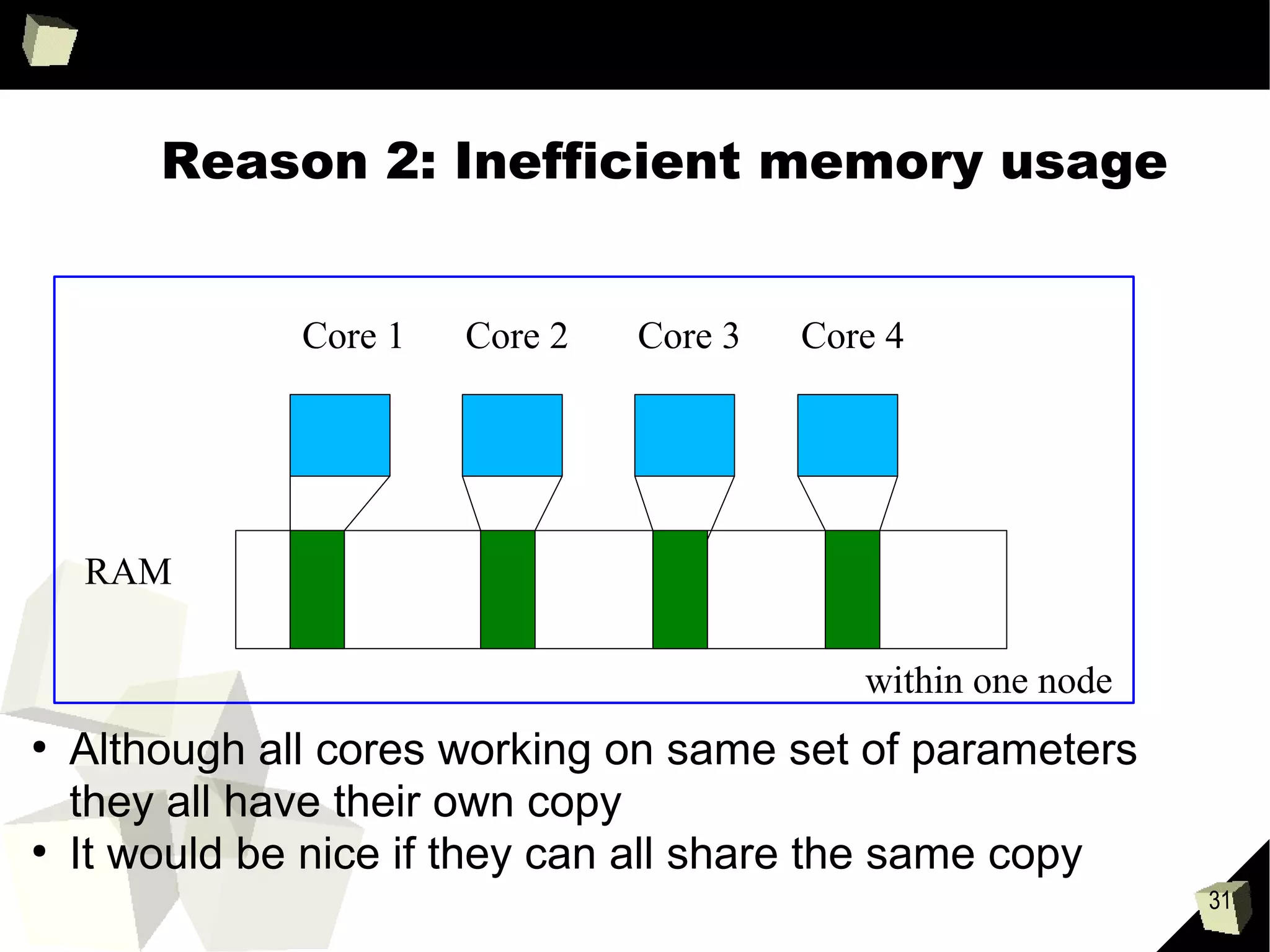
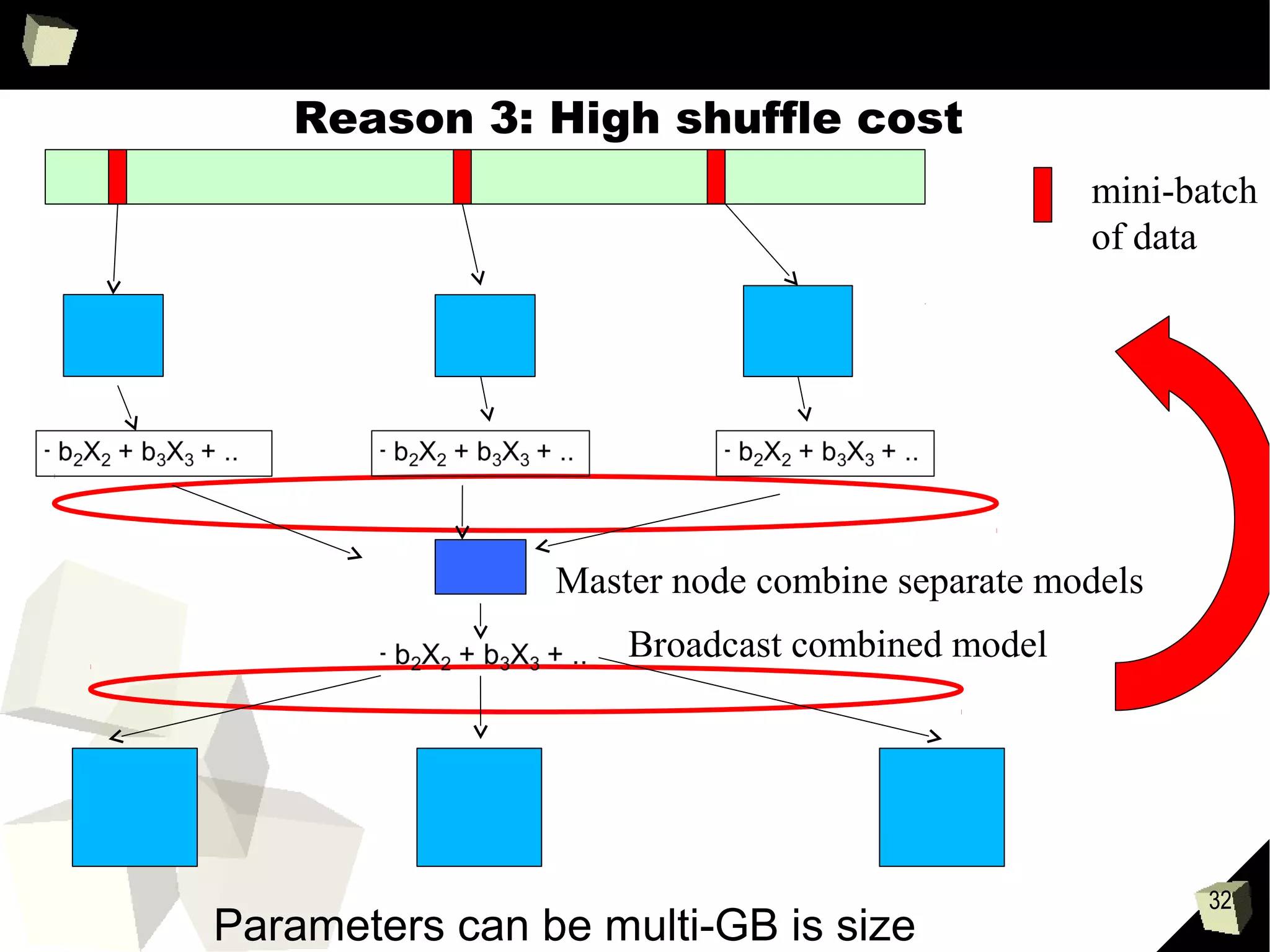
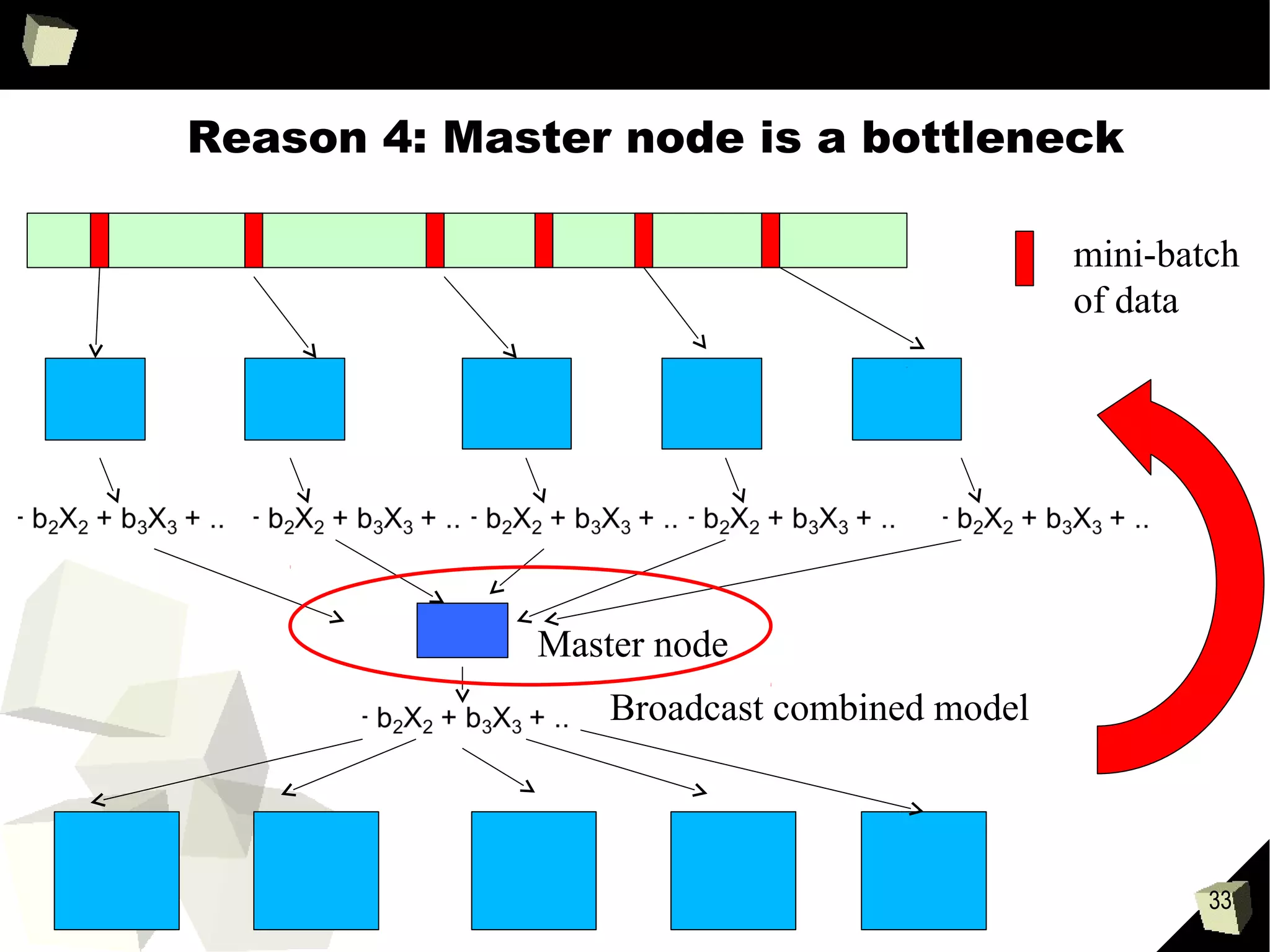
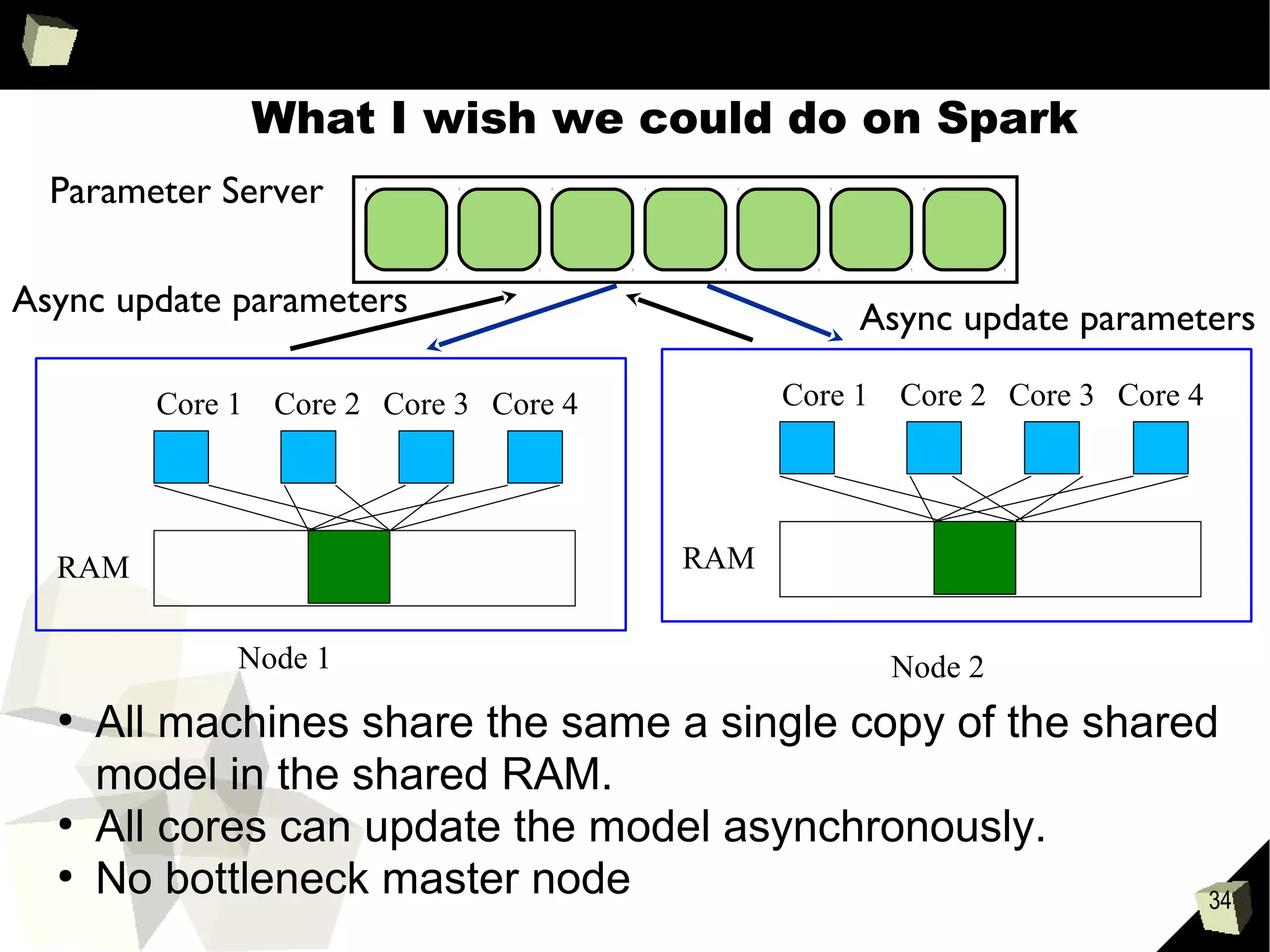
Downloaded 30 times























![36
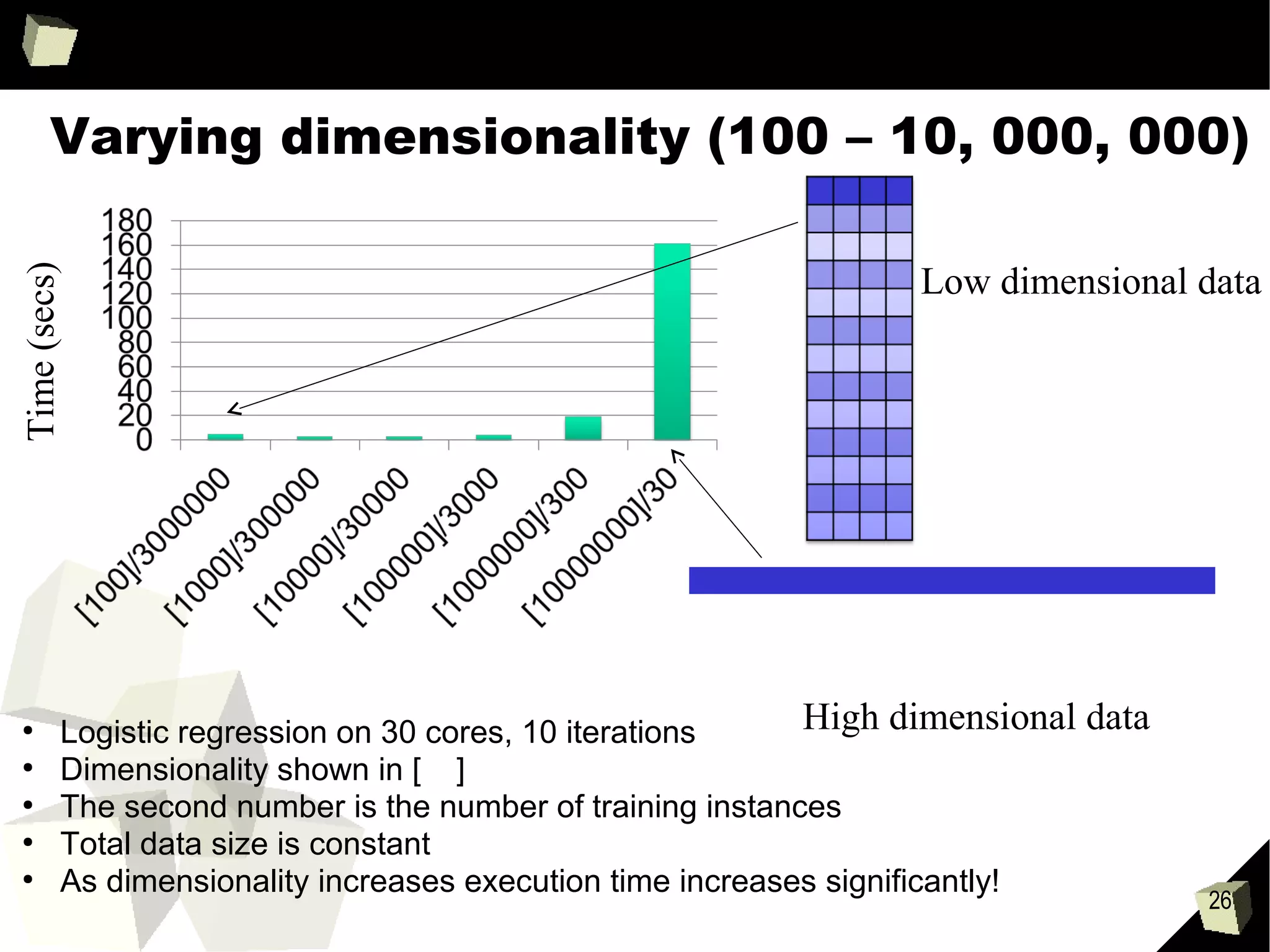
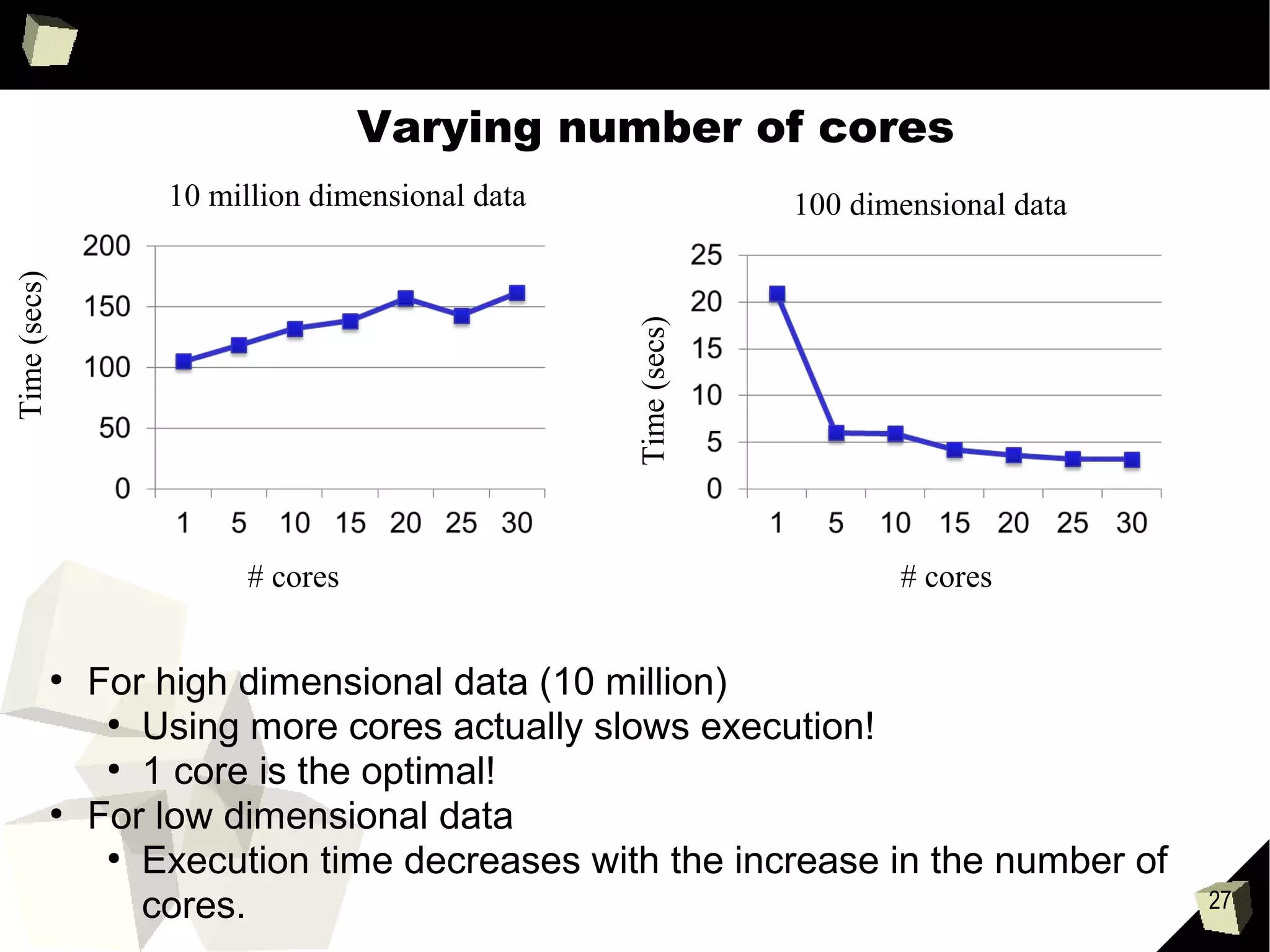
Varying dimensionality (100 – 10, 000, 000)
●
Logistic regression on 30 cores, 10 iterations
●
Dimensionality shown in [ ]
●
The second number is the number of training instances
●
Total data size is constant
●
As dimensionality increases execution time increases significantly!
Time(secs)
Low dimensional data
High dimensional data](https://image.slidesharecdn.com/apache-spark-melbourne-april-meetup-150409035837-conversion-gate01/75/Apache-spark-melbourne-april-2015-meetup-36-2048.jpg)
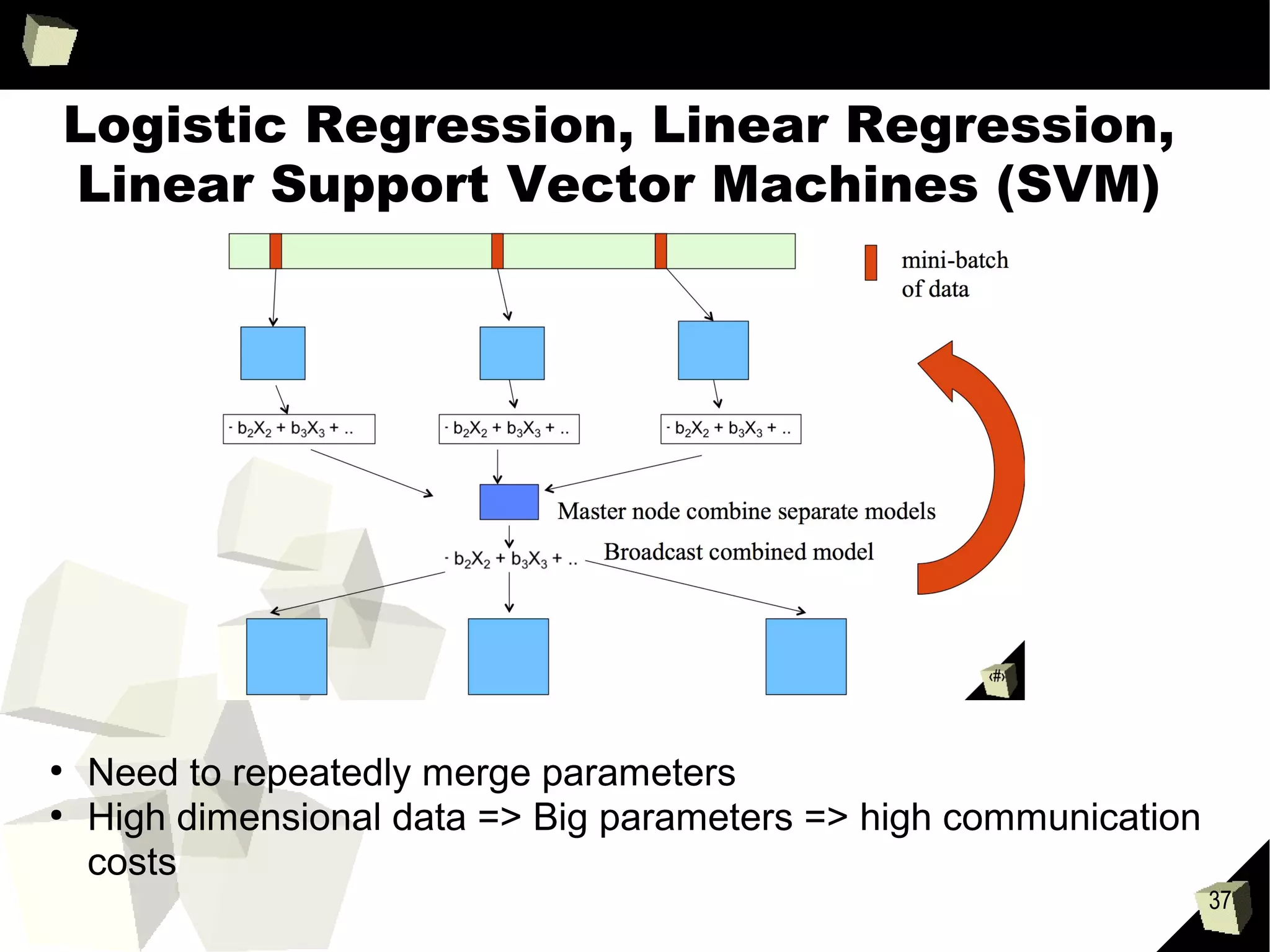






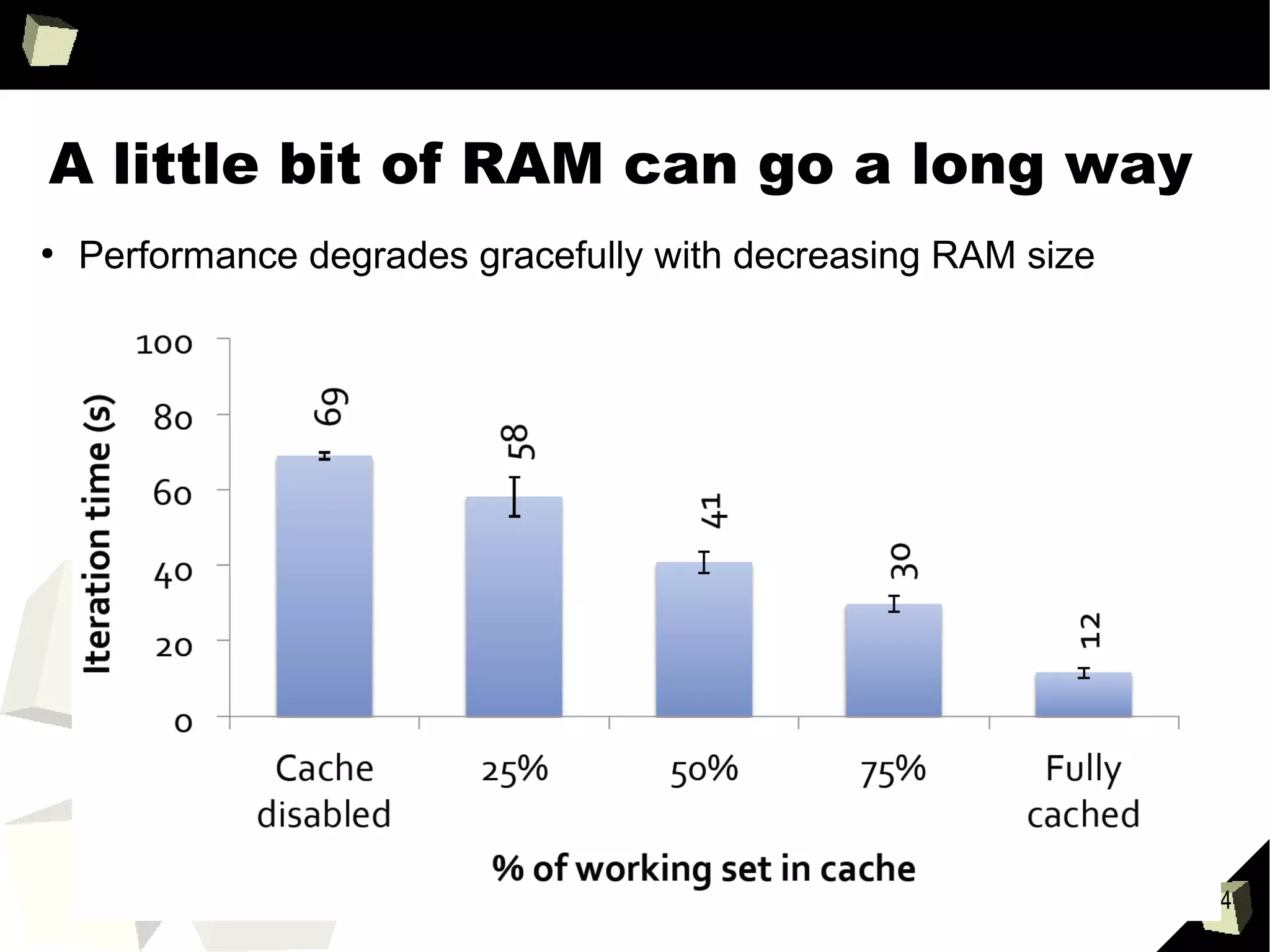












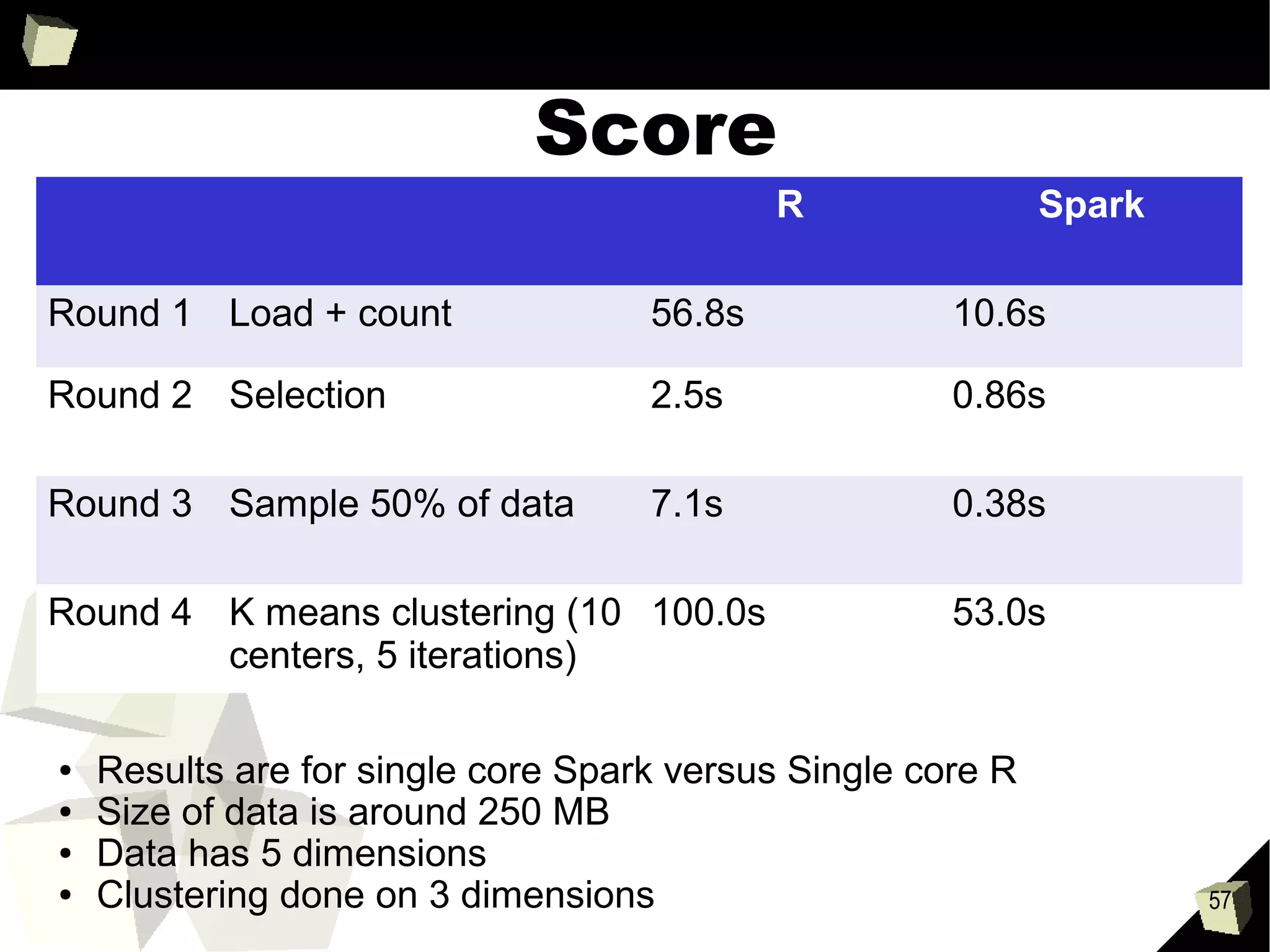












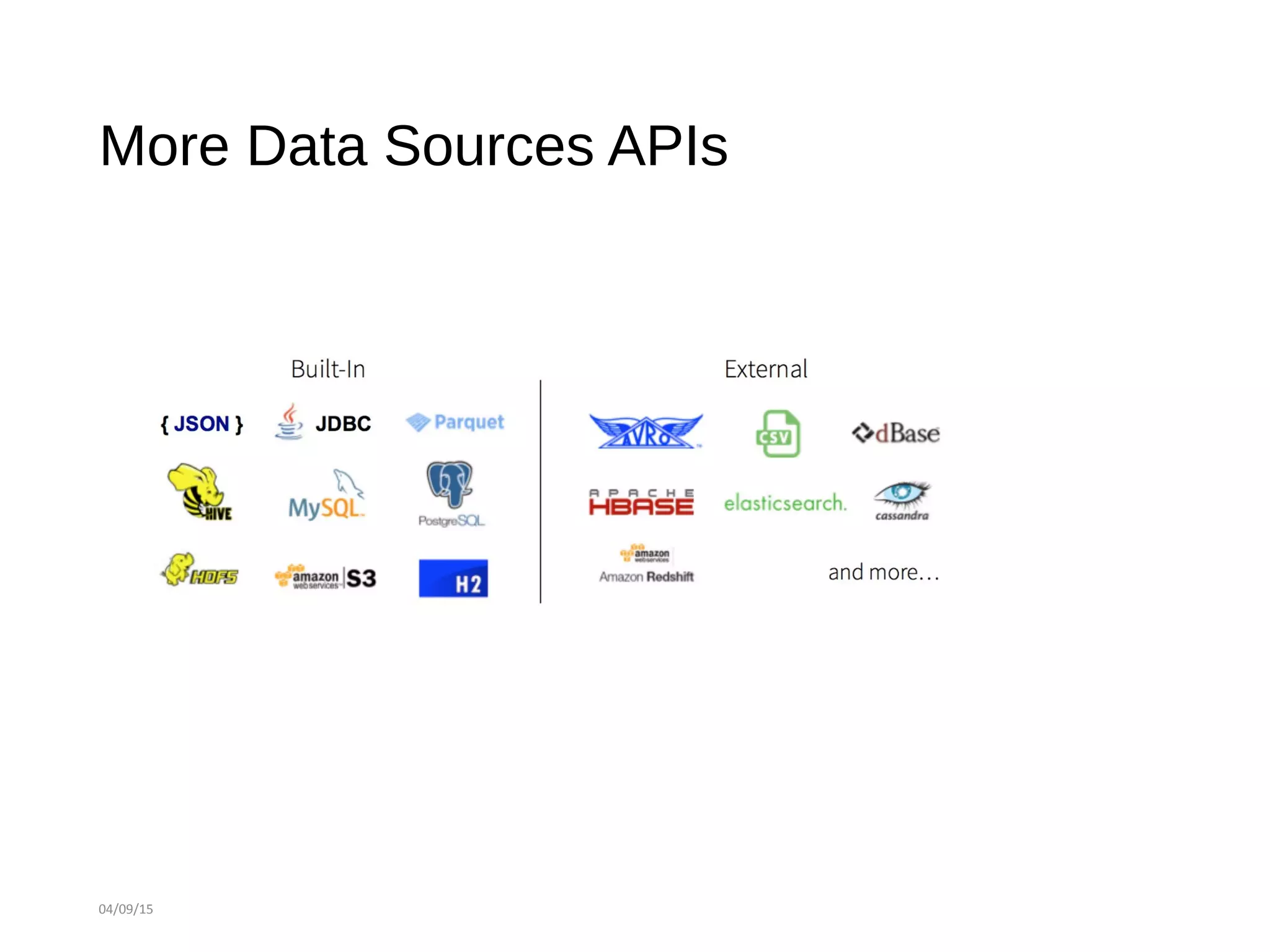
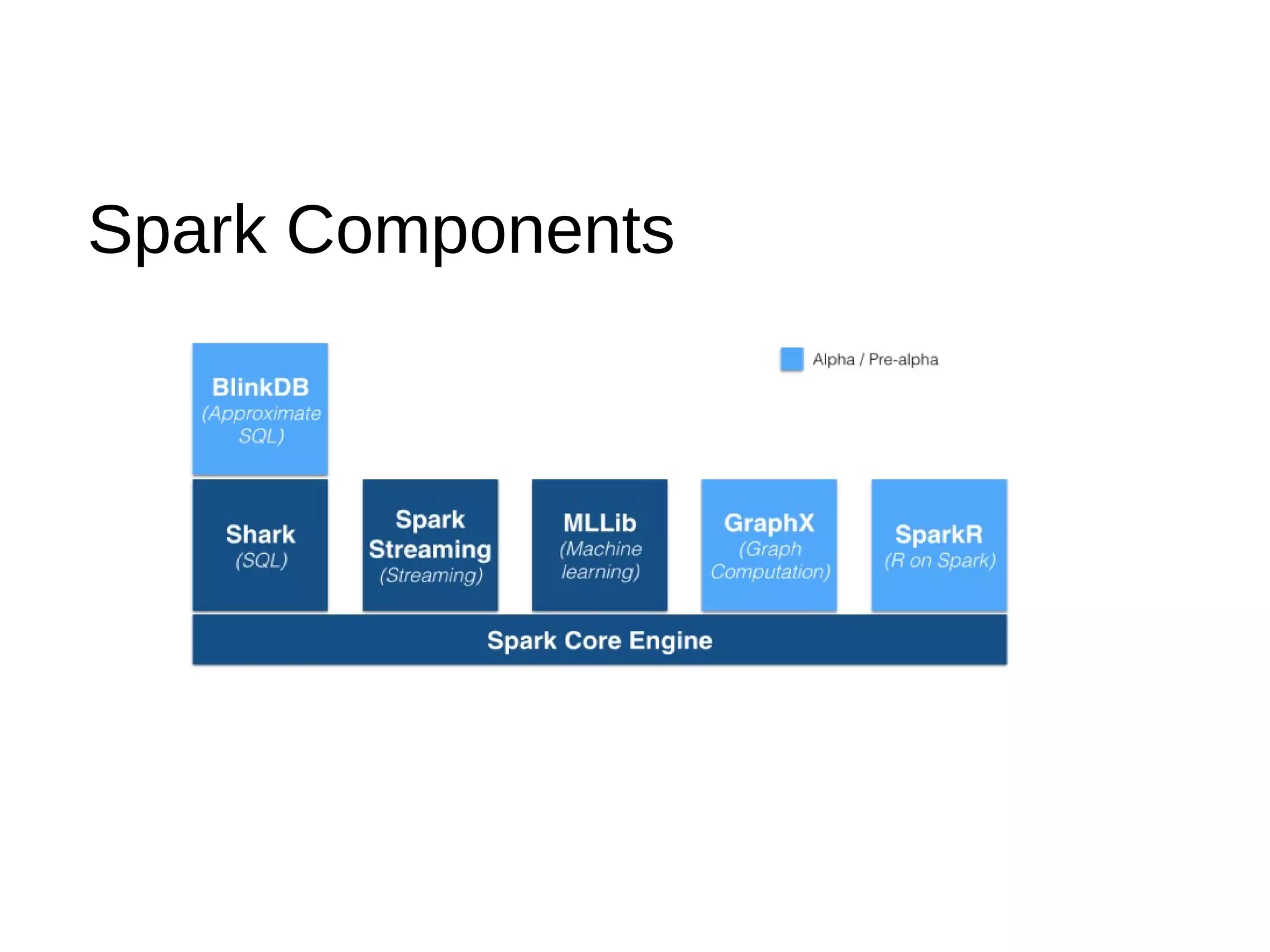
This document provides an agenda and summaries for a meetup on introducing DataFrames and R on Apache Spark. The agenda includes overviews of Apache Spark 1.3, DataFrames, R on Spark, and large scale machine learning on Spark. There will also be discussions on news items, contributions so far, what's new in Spark 1.3, more data source APIs, what DataFrames are, writing DataFrames, and DataFrames with RDDs and Parquet. Presentations will cover Spark components, an introduction to SparkR, and Spark machine learning experiences.




















































































