Downloaded 177 times












![customSchema = StructType([
StructField("time", TimestampType(),True),
StructField("host", StringType(),True),
StructField("source", StringType(),True),
StructField ("event",
MapType(StringType(), StringType()))
])
JSON Generic Specified Schema
StructType => MapType
Print Schema
Specify Schema
spark.read.json("record*.json").printSchema
spark.read.schema(customSchema).json("record*.json")](https://image.slidesharecdn.com/sparksummiteast2017-keepingsparkontracknon-build-170209192327/75/Keeping-Spark-on-Track-Productionizing-Spark-for-ETL-13-2048.jpg)











![DataFrame Joins
df = spark.read.options(header='true').csv('/mnt/mwc/csv_join_empty')
df_duplicate = df.join(df, df['id'] == df['id'])
df_duplicate.printSchema()
(2) Spark Jobs
root
|-- id: string (nullable = true)
|-- name1: string (nullable = true)
|-- id: string (nullable = true)
|-- name2: string (nullable = true)](https://image.slidesharecdn.com/sparksummiteast2017-keepingsparkontracknon-build-170209192327/75/Keeping-Spark-on-Track-Productionizing-Spark-for-ETL-26-2048.jpg)



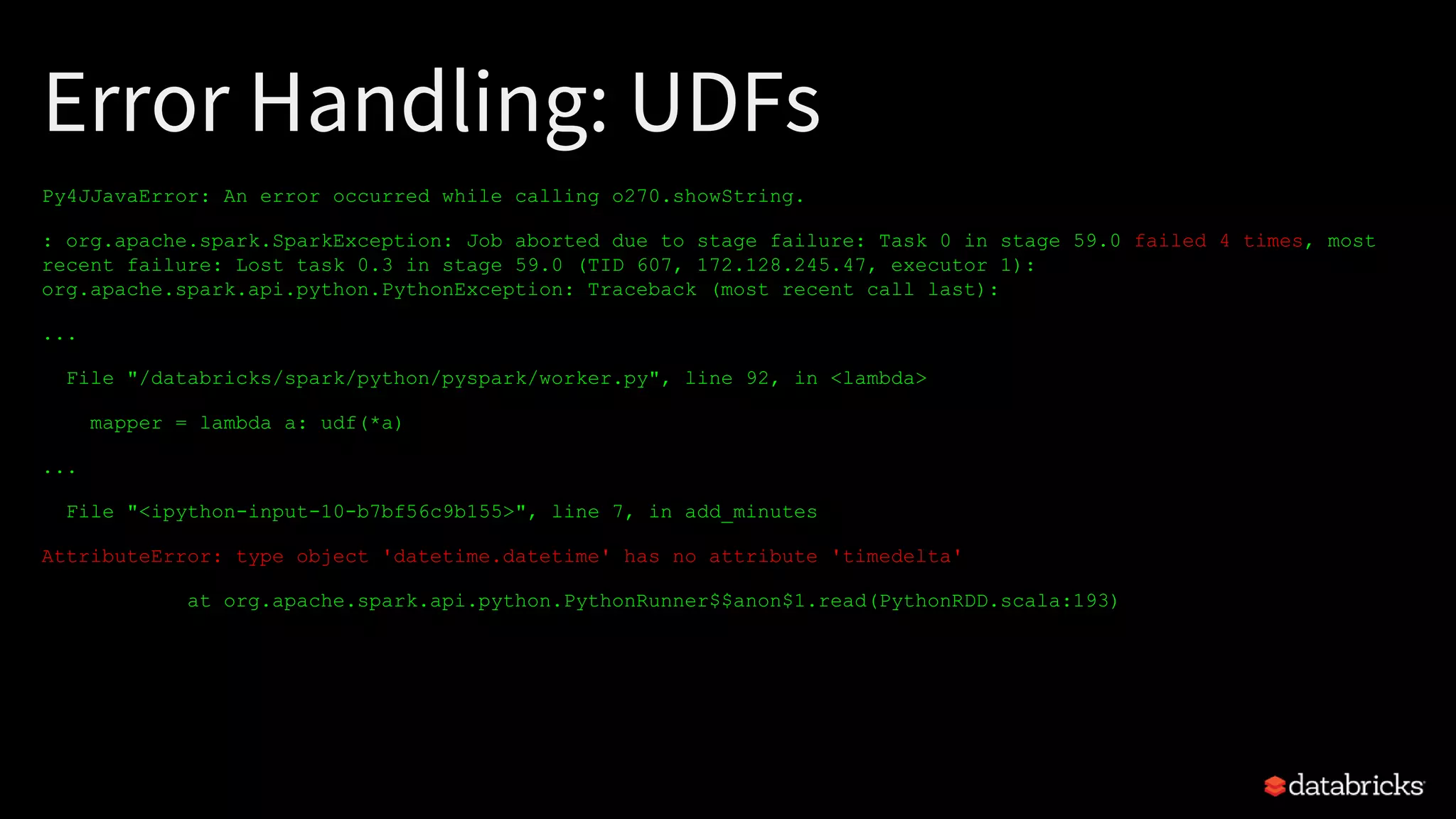

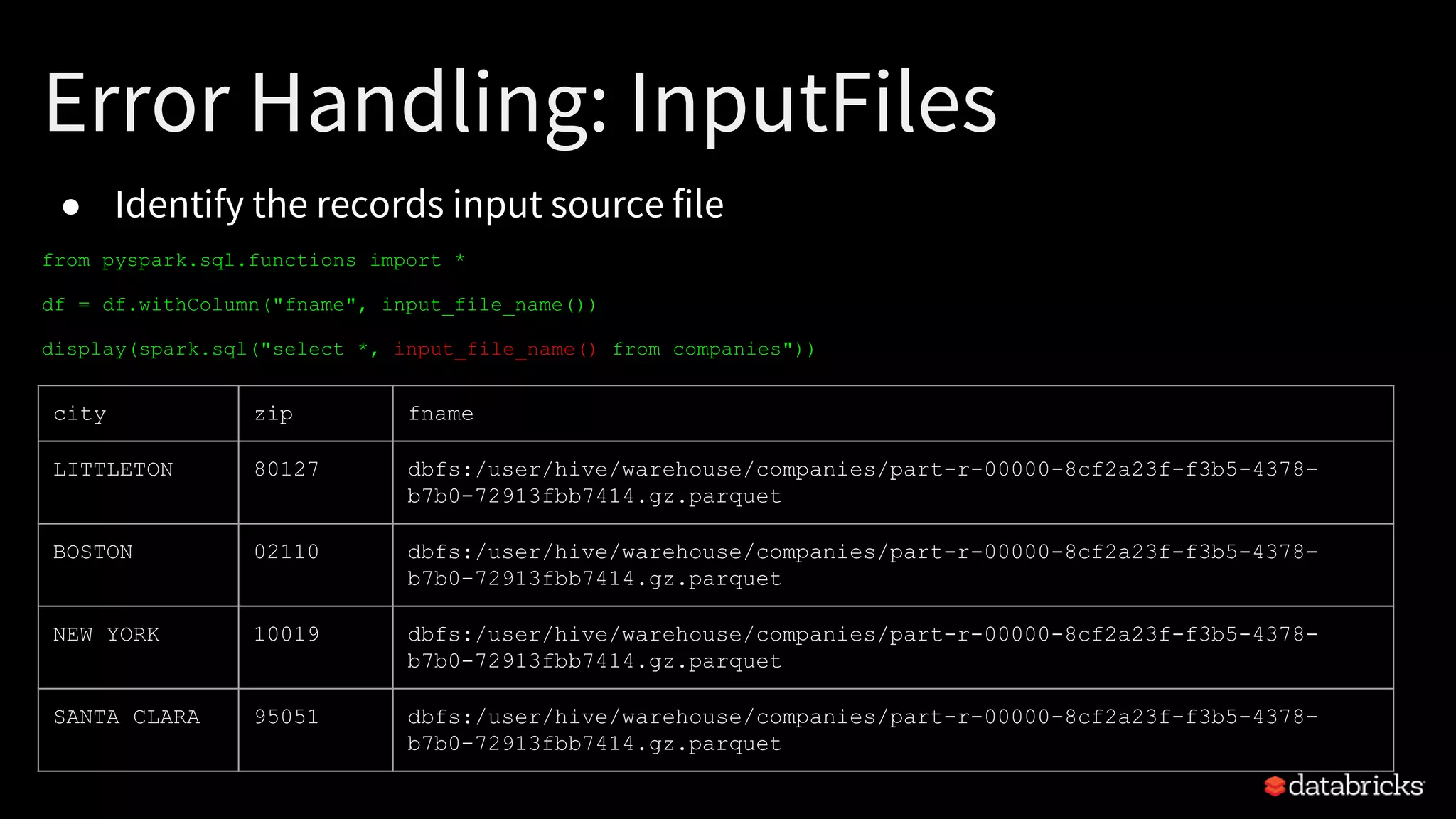


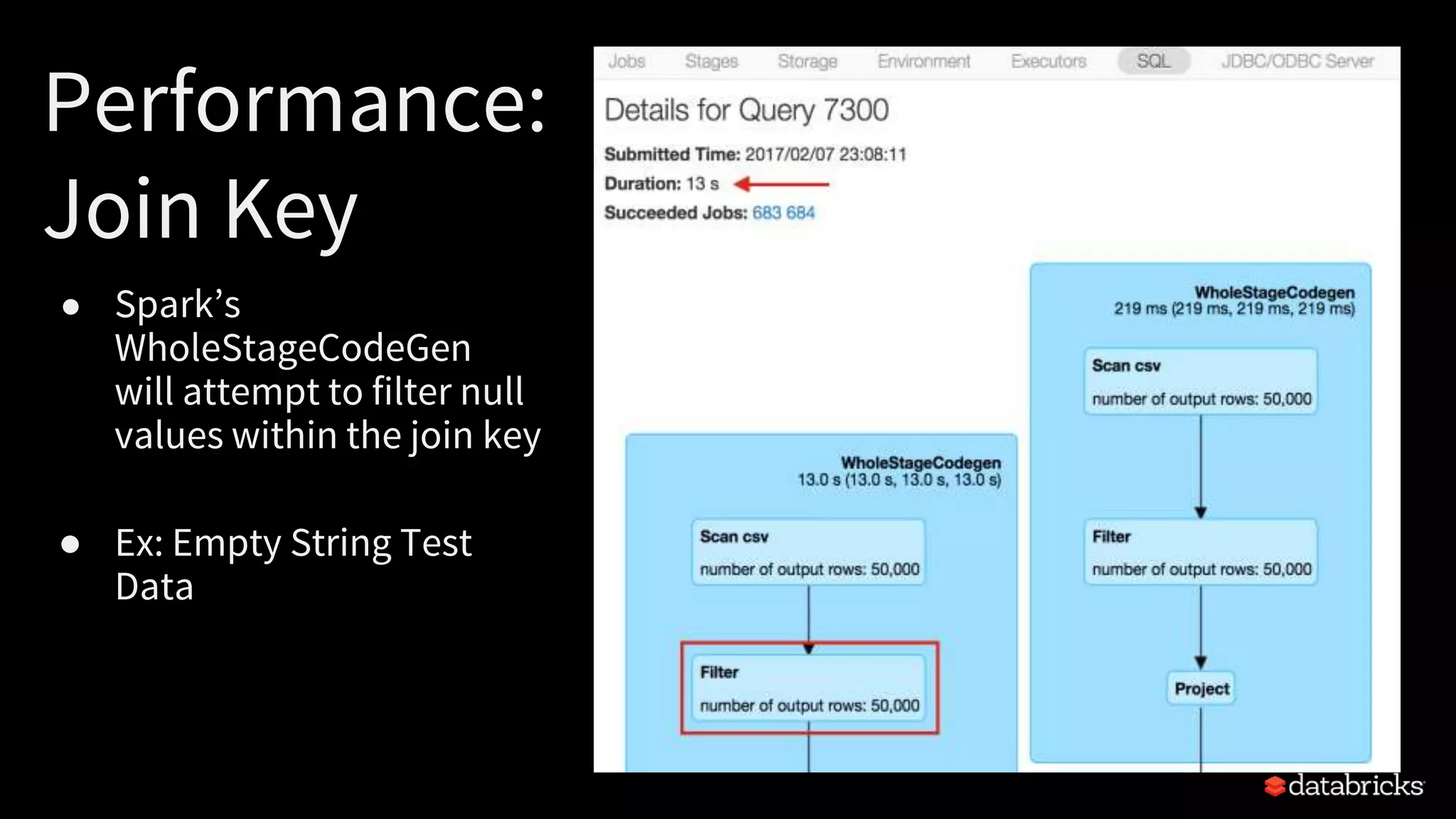
The document discusses best practices for productionizing Apache Spark for ETL processes, focusing on metadata management, performance optimization, and schema handling. Key points include transforming raw files into efficient binary formats, strategies for error handling, and optimizing data partitioning for better efficiency. Examples of JSON schema handling and optimization techniques for Spark SQL joins are also provided.










































































































