Download as PDF, PPTX






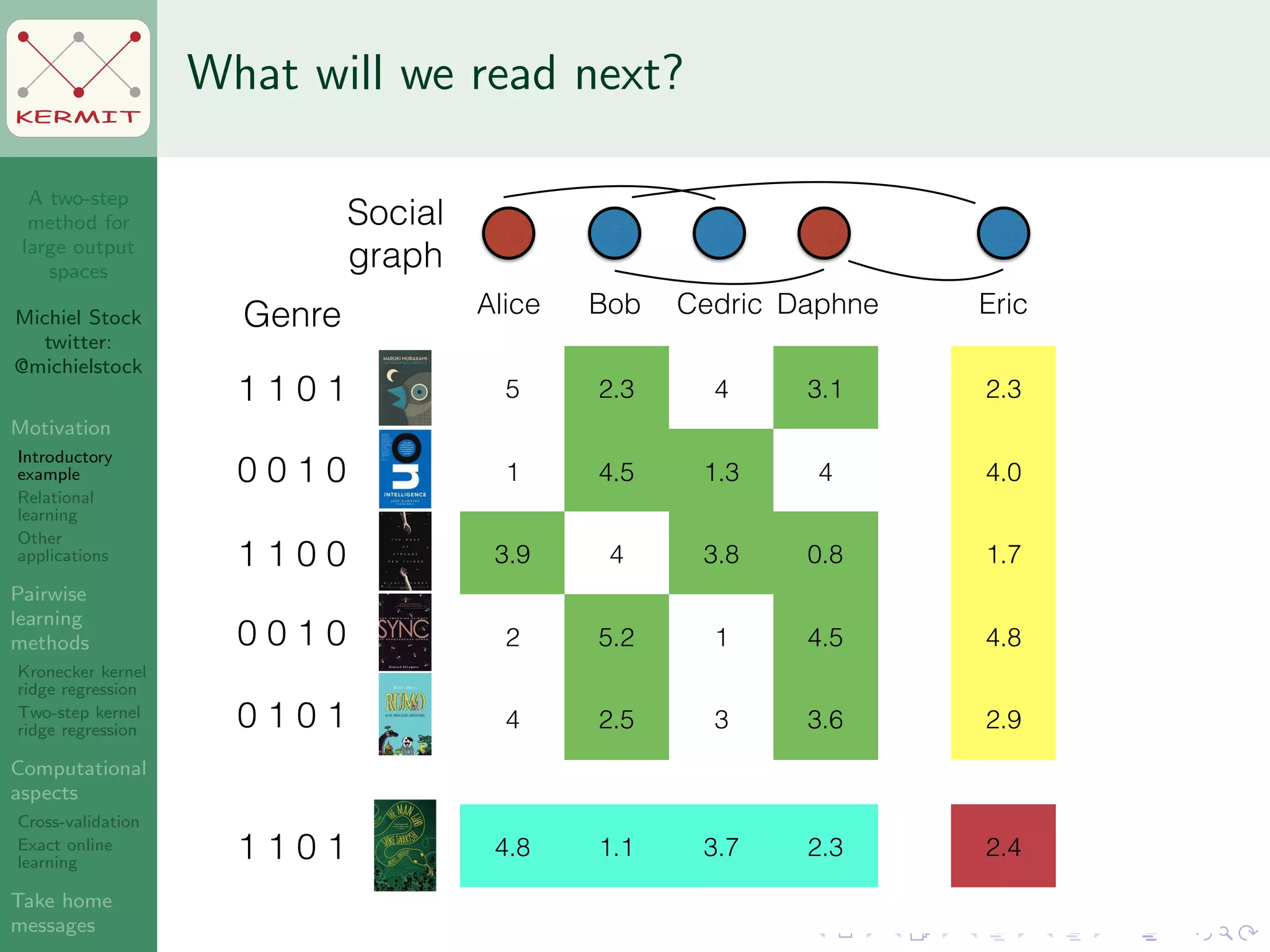
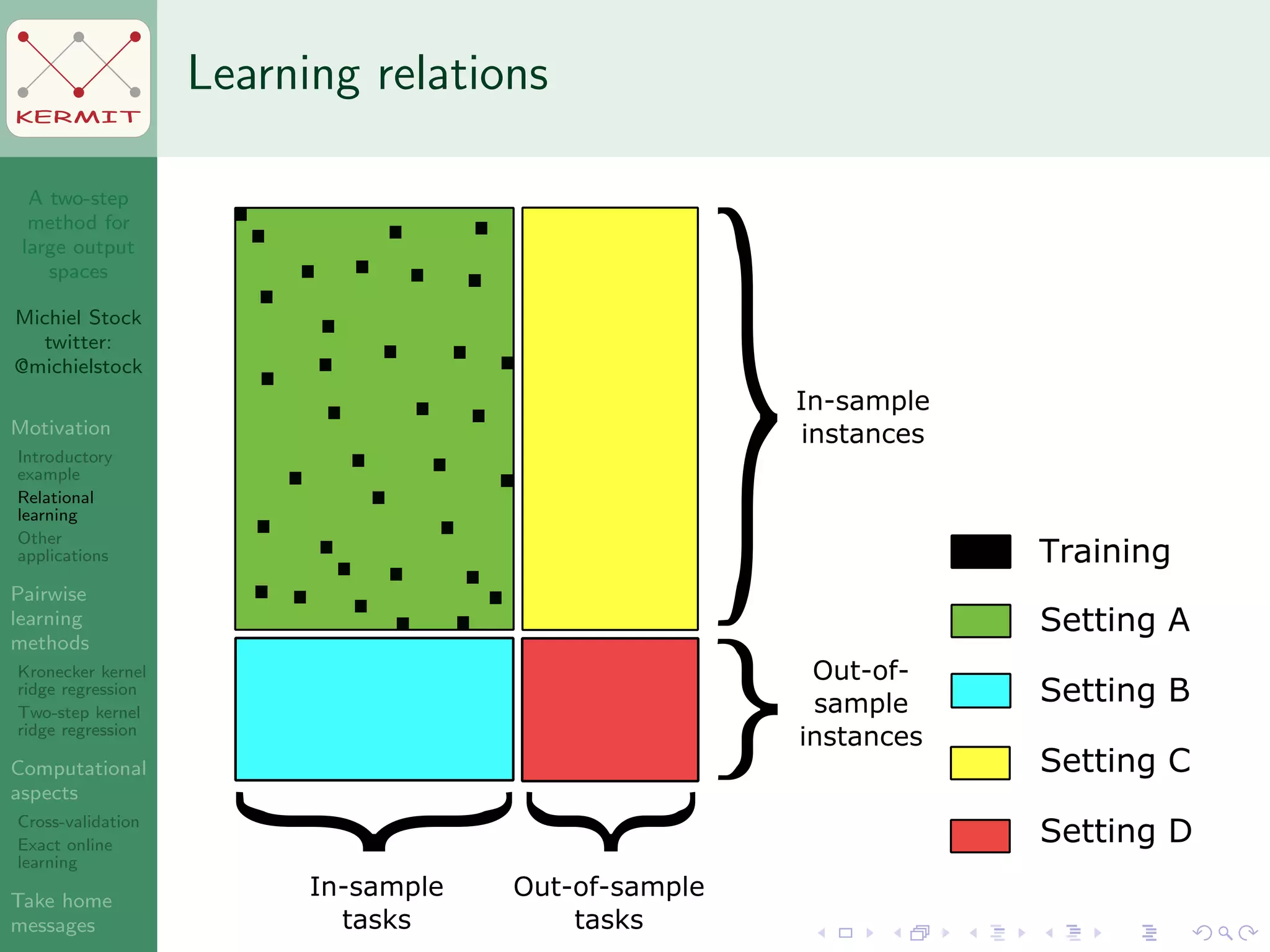

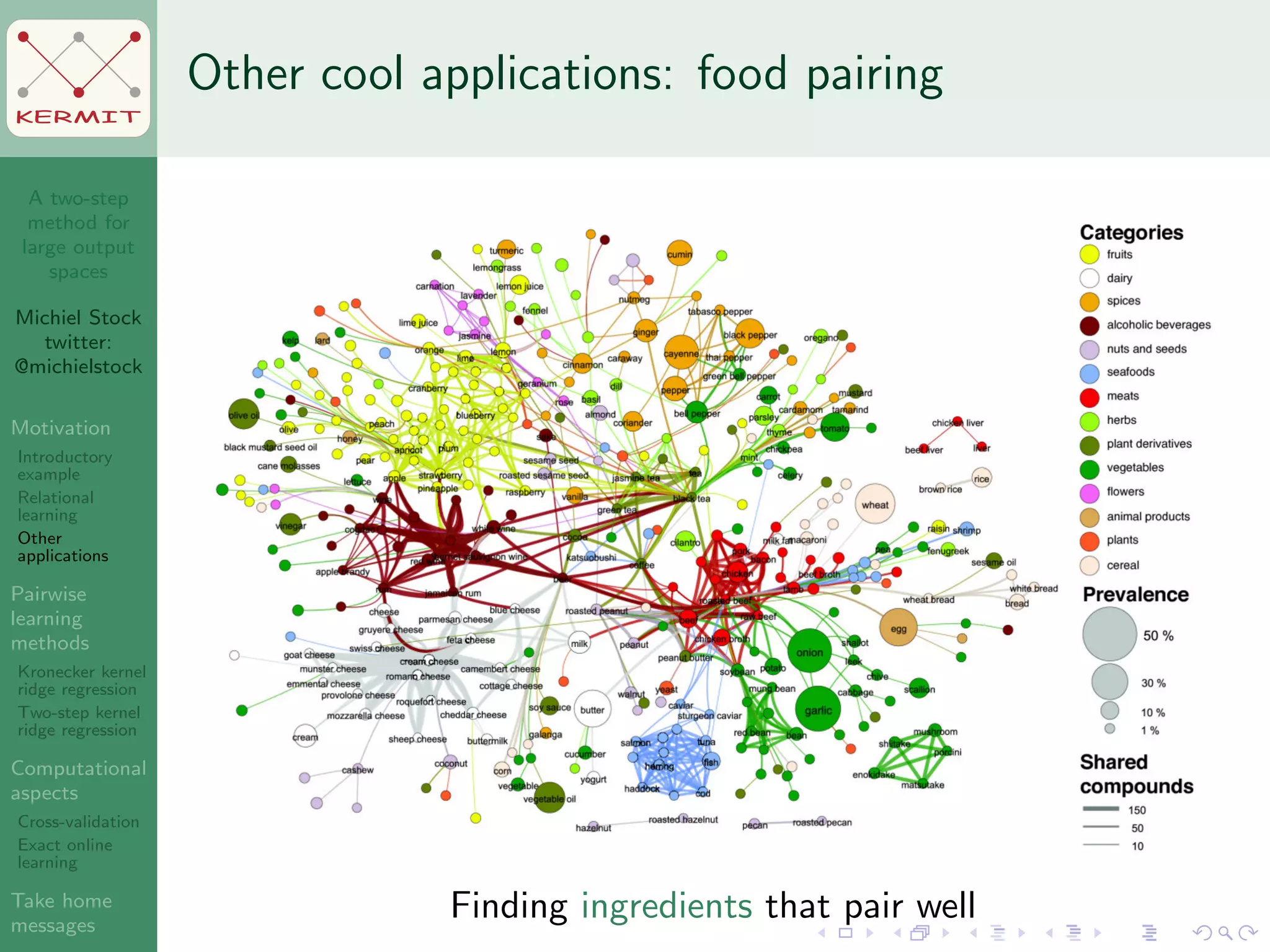
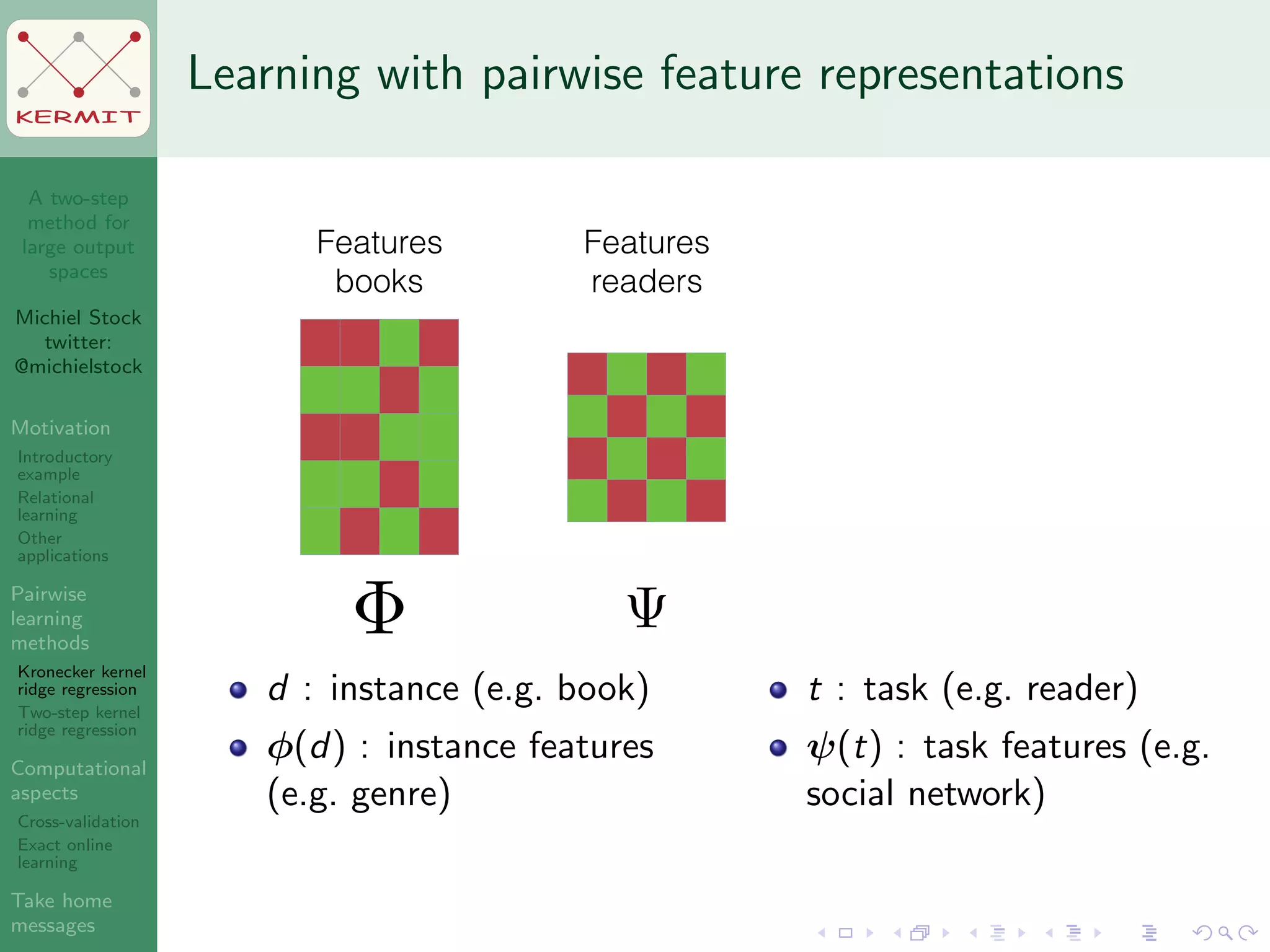
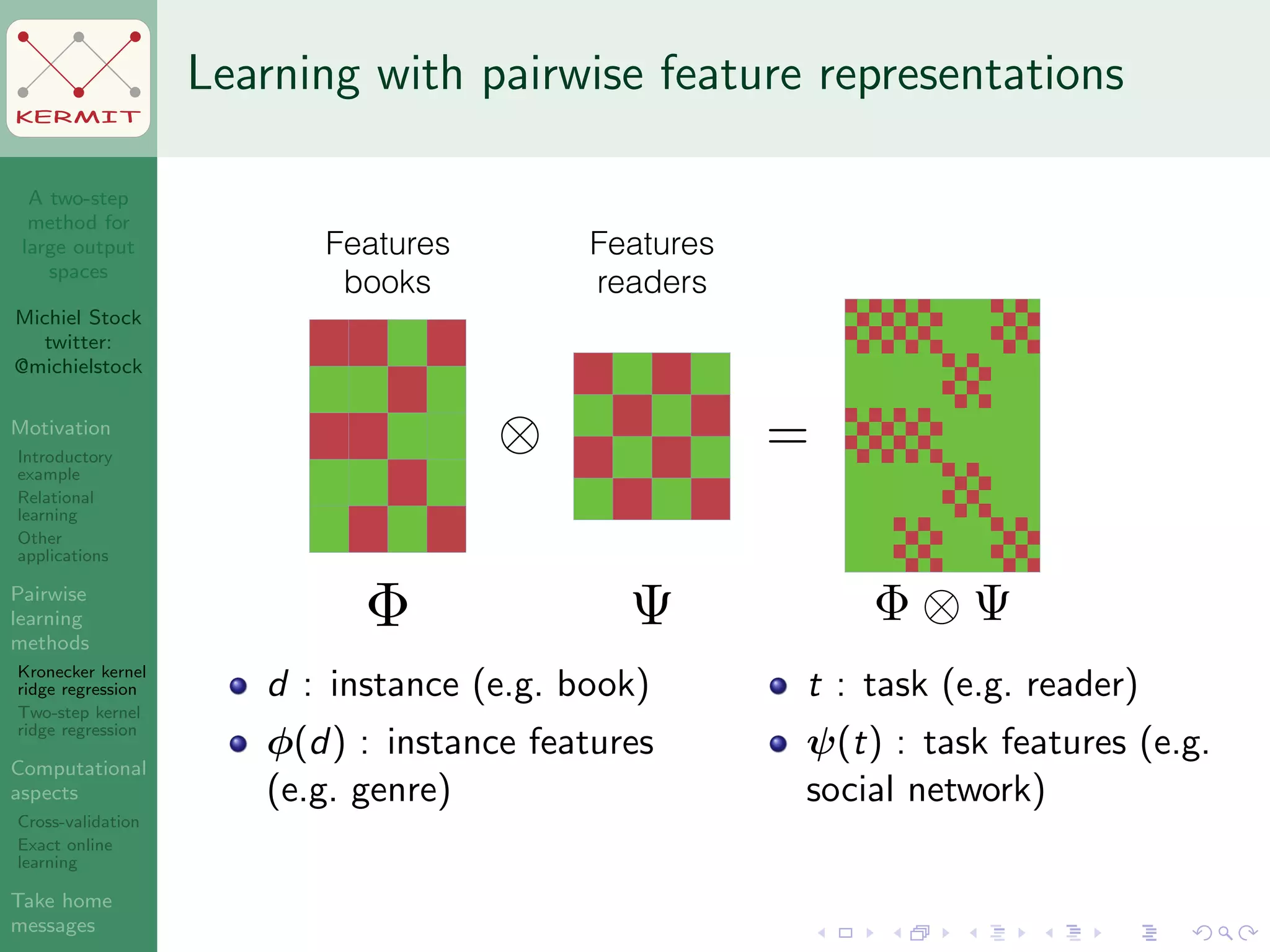
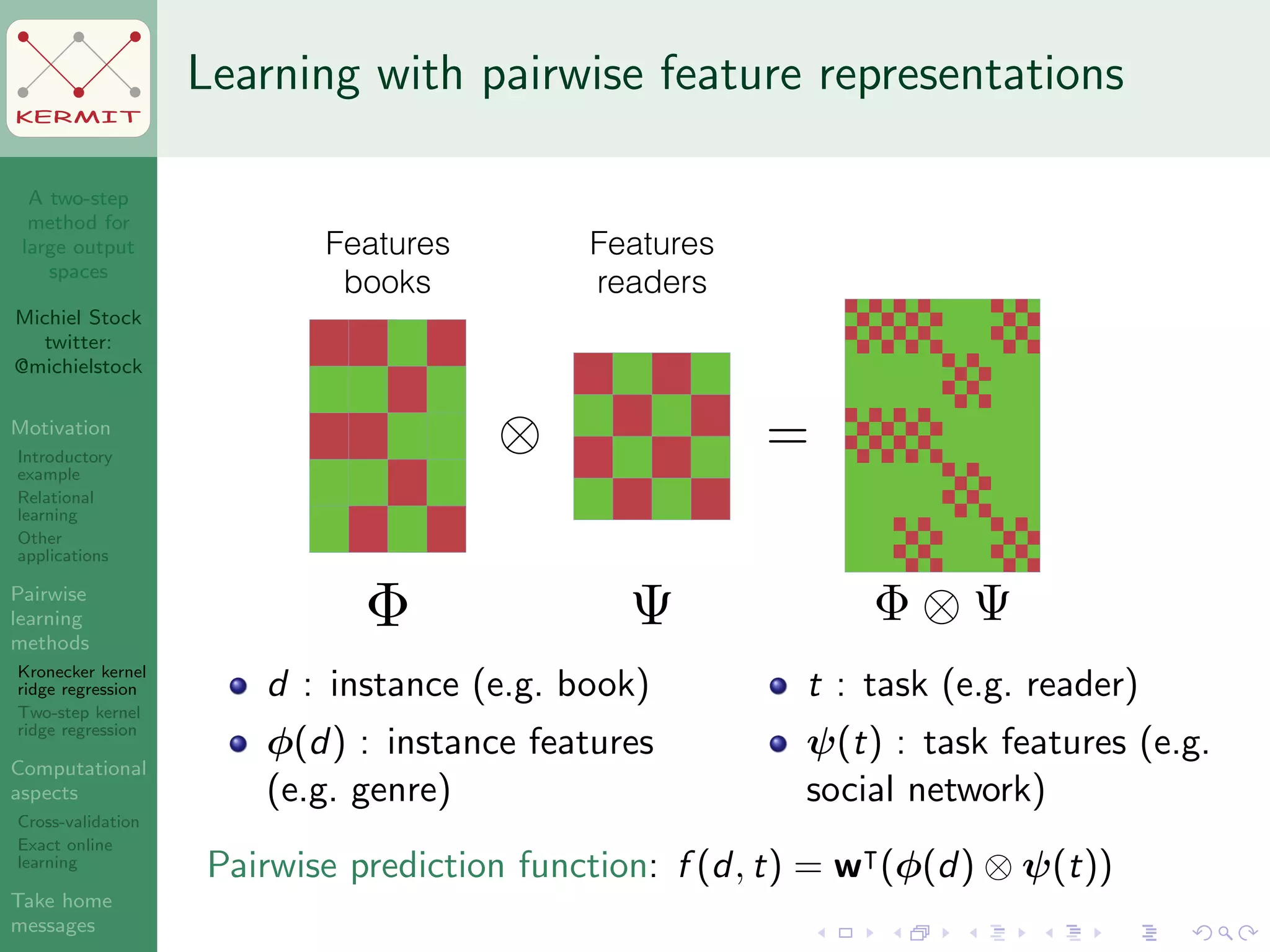
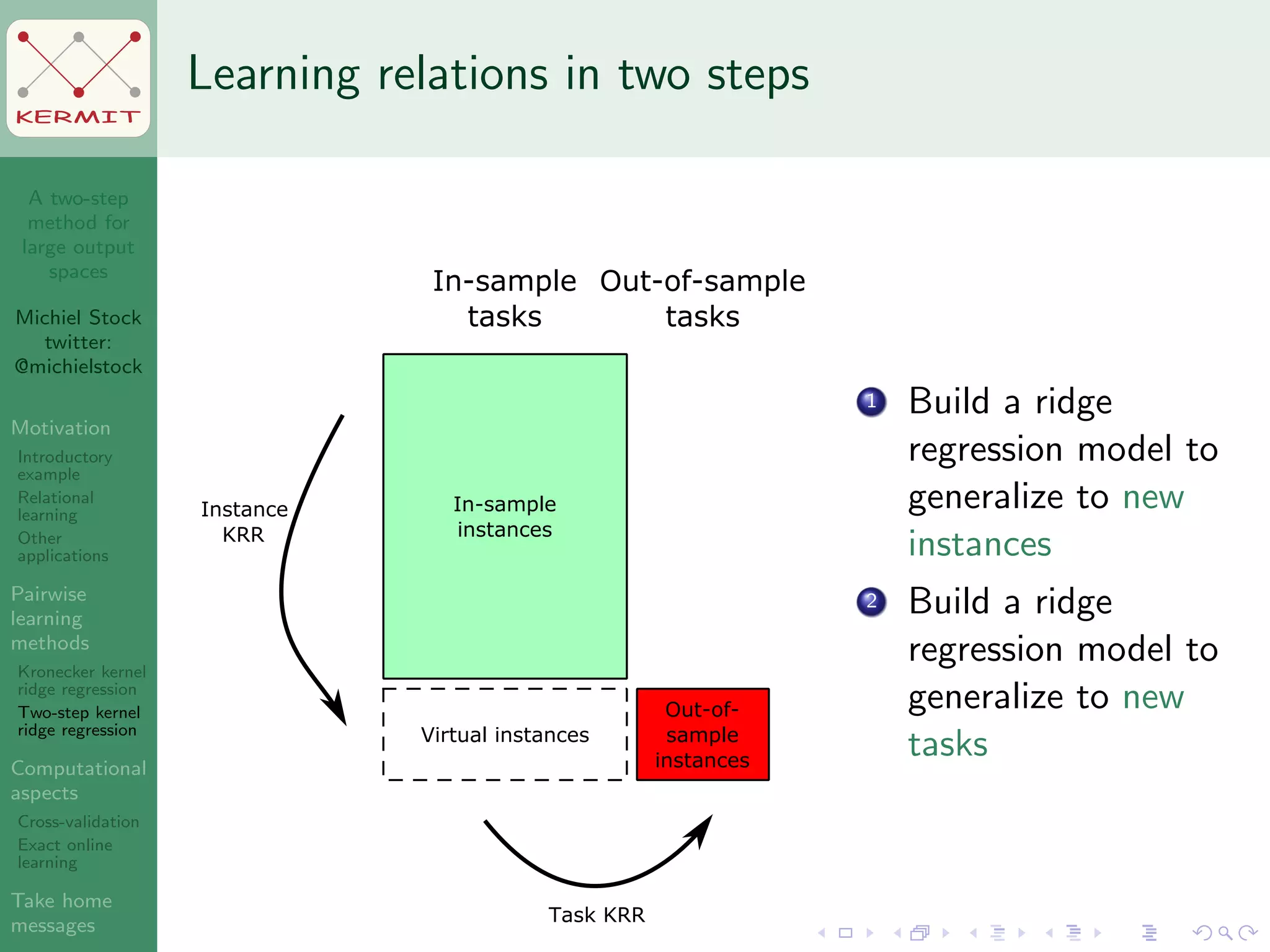


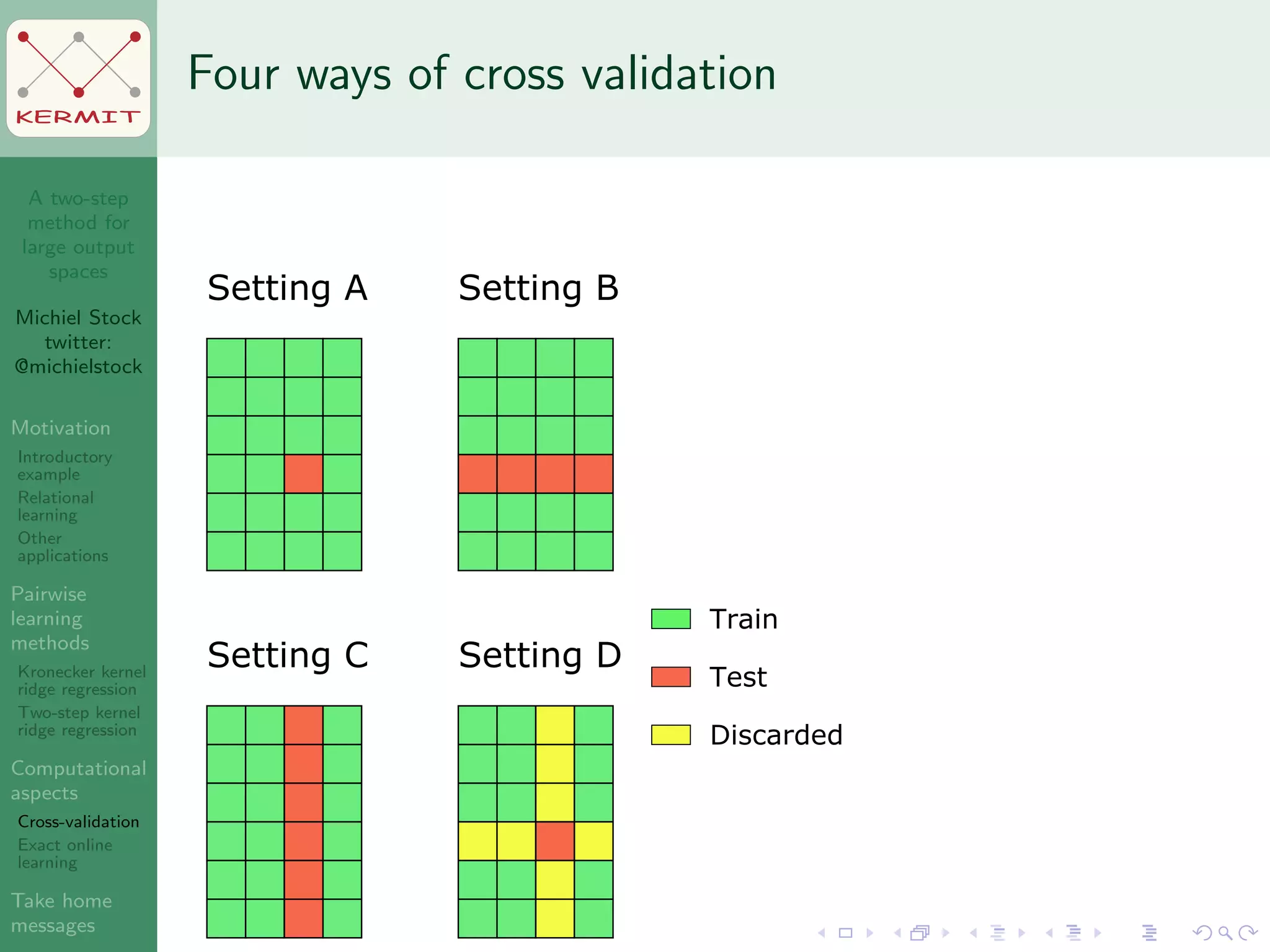
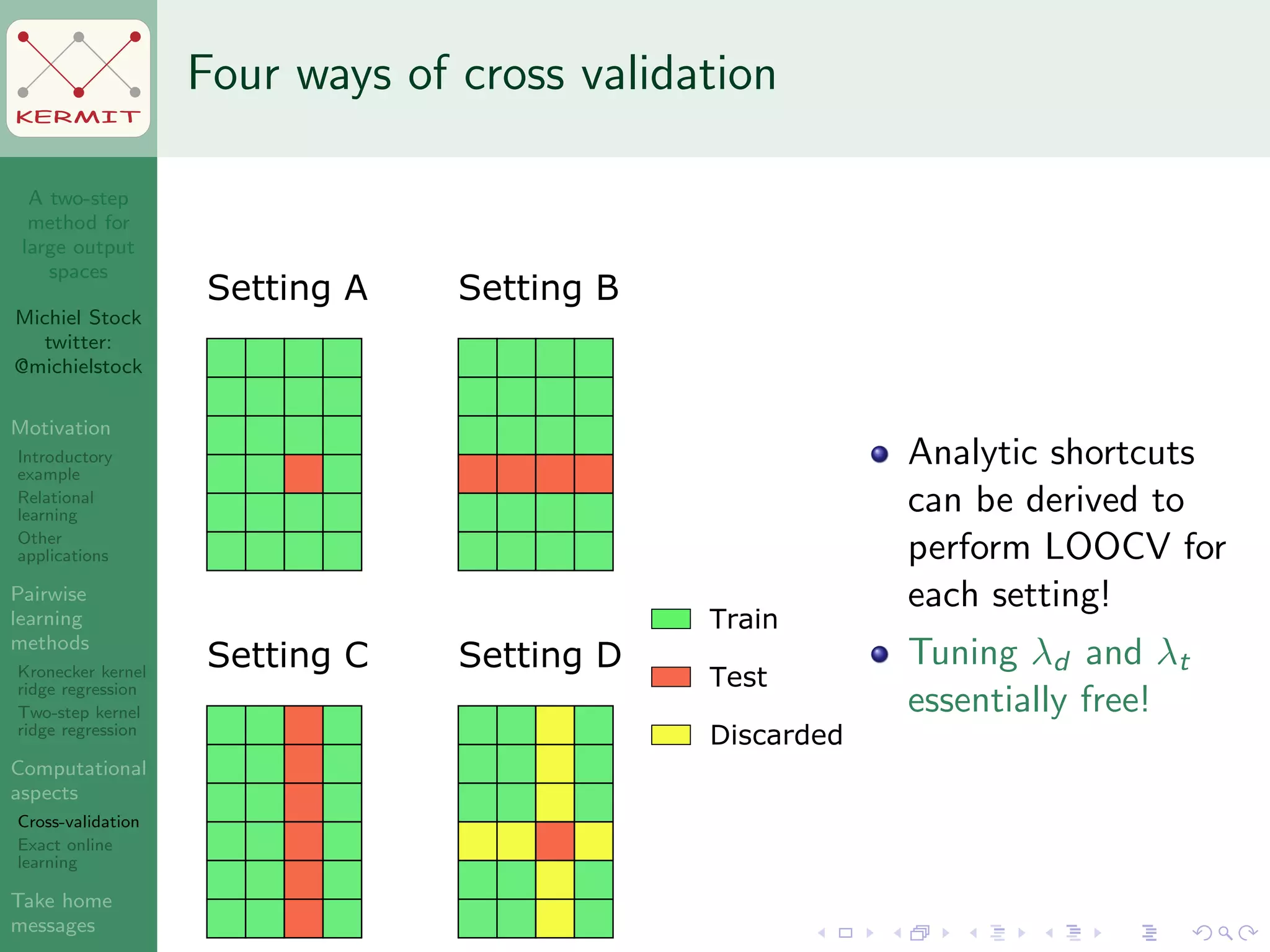
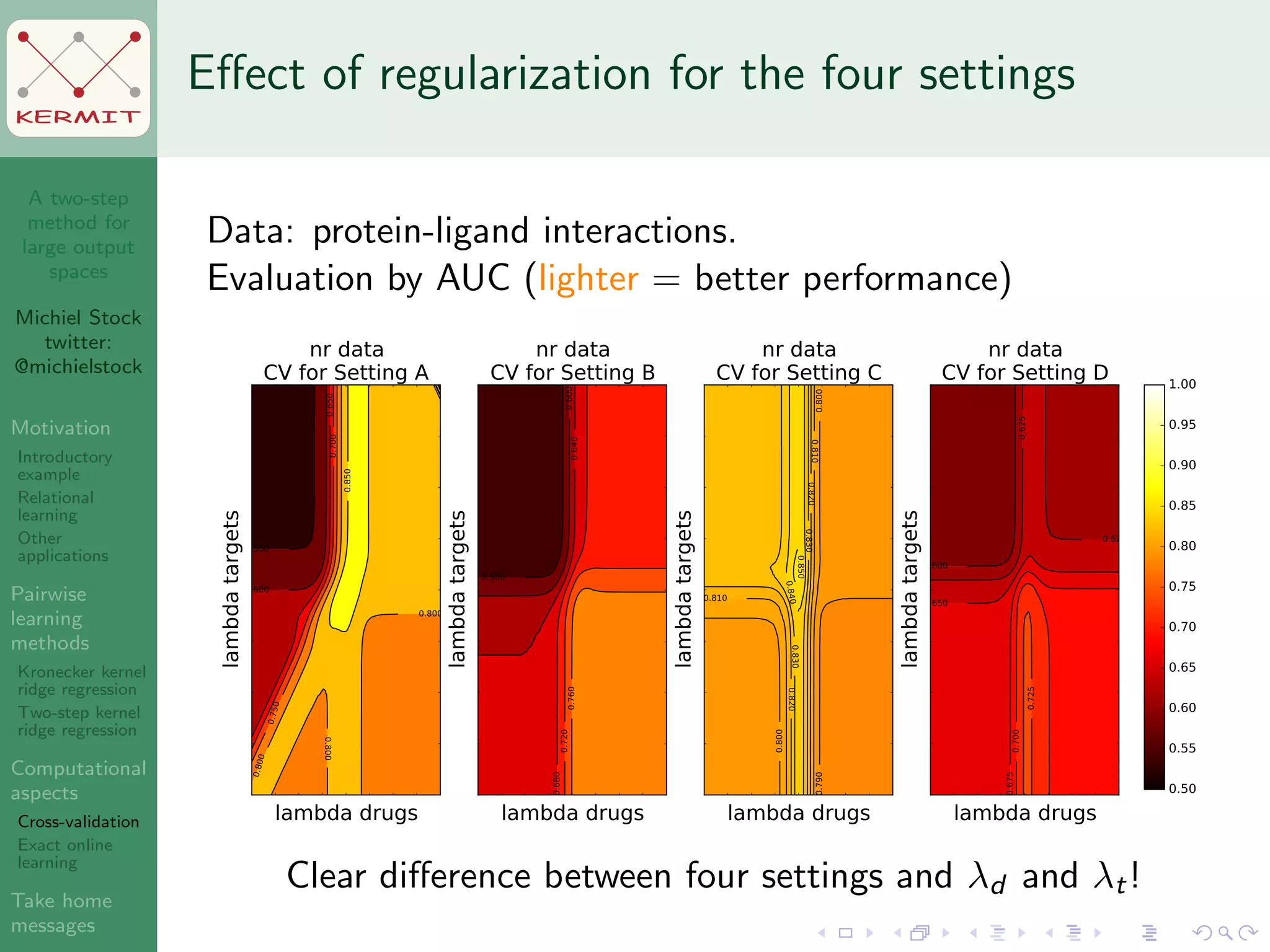
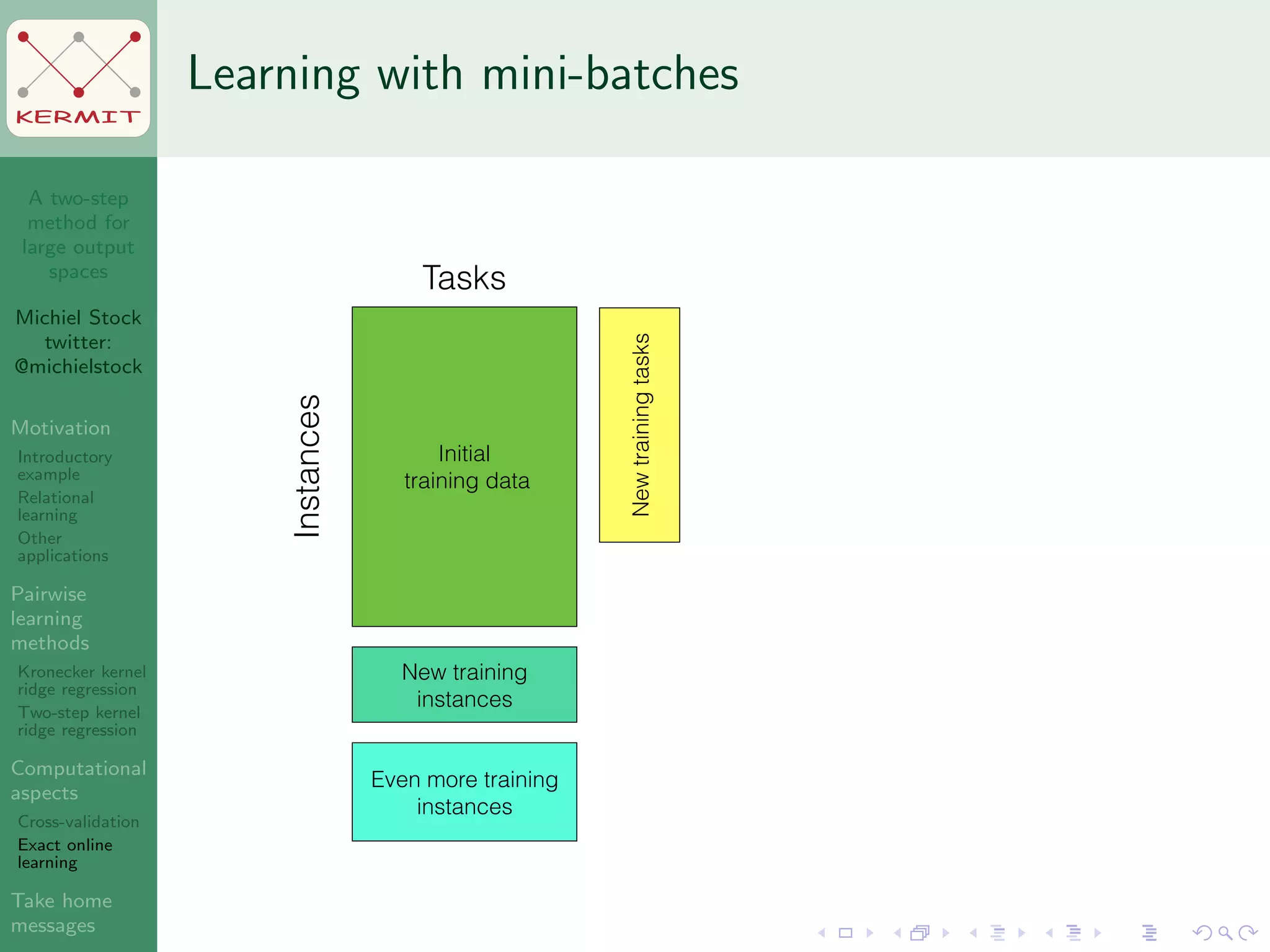
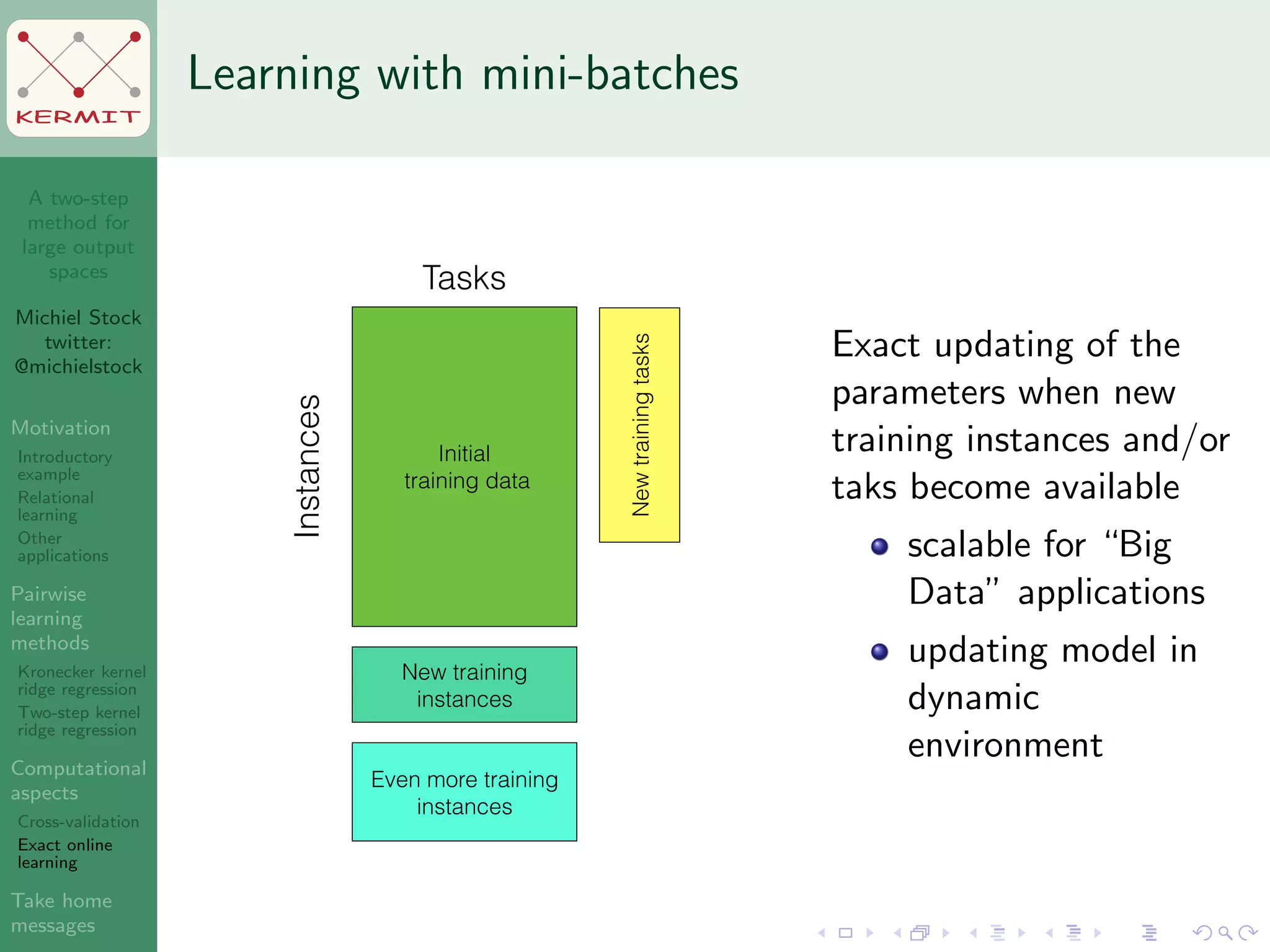






The document presents a two-step method for handling large output spaces in machine learning, focusing on techniques such as kernel ridge regression and cross-validation. It emphasizes the incorporation of task features and offers applications in areas like drug design and social network analysis. The method supports exact online learning and allows for efficient model updates in dynamic environments.







































