Download to read offline


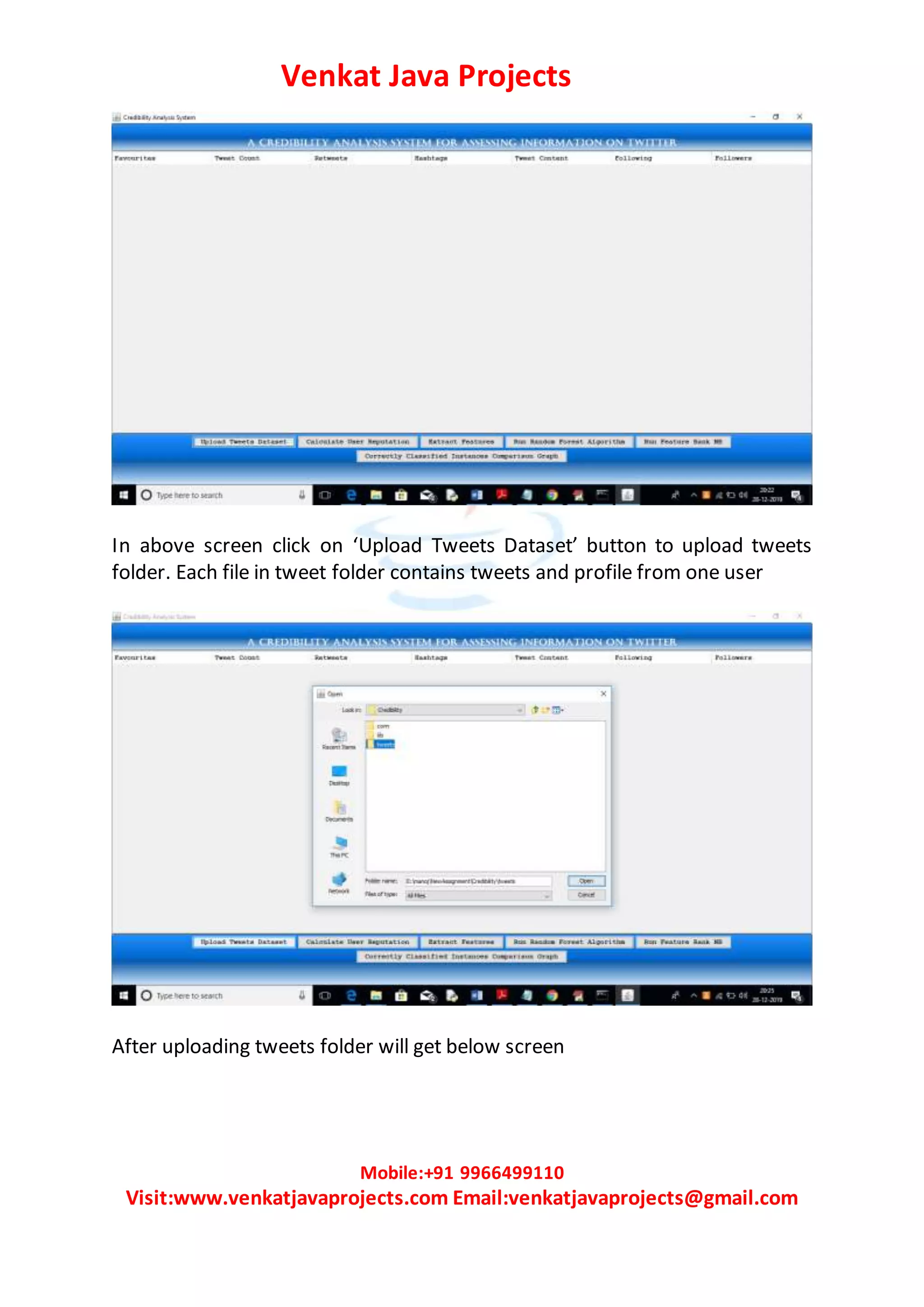
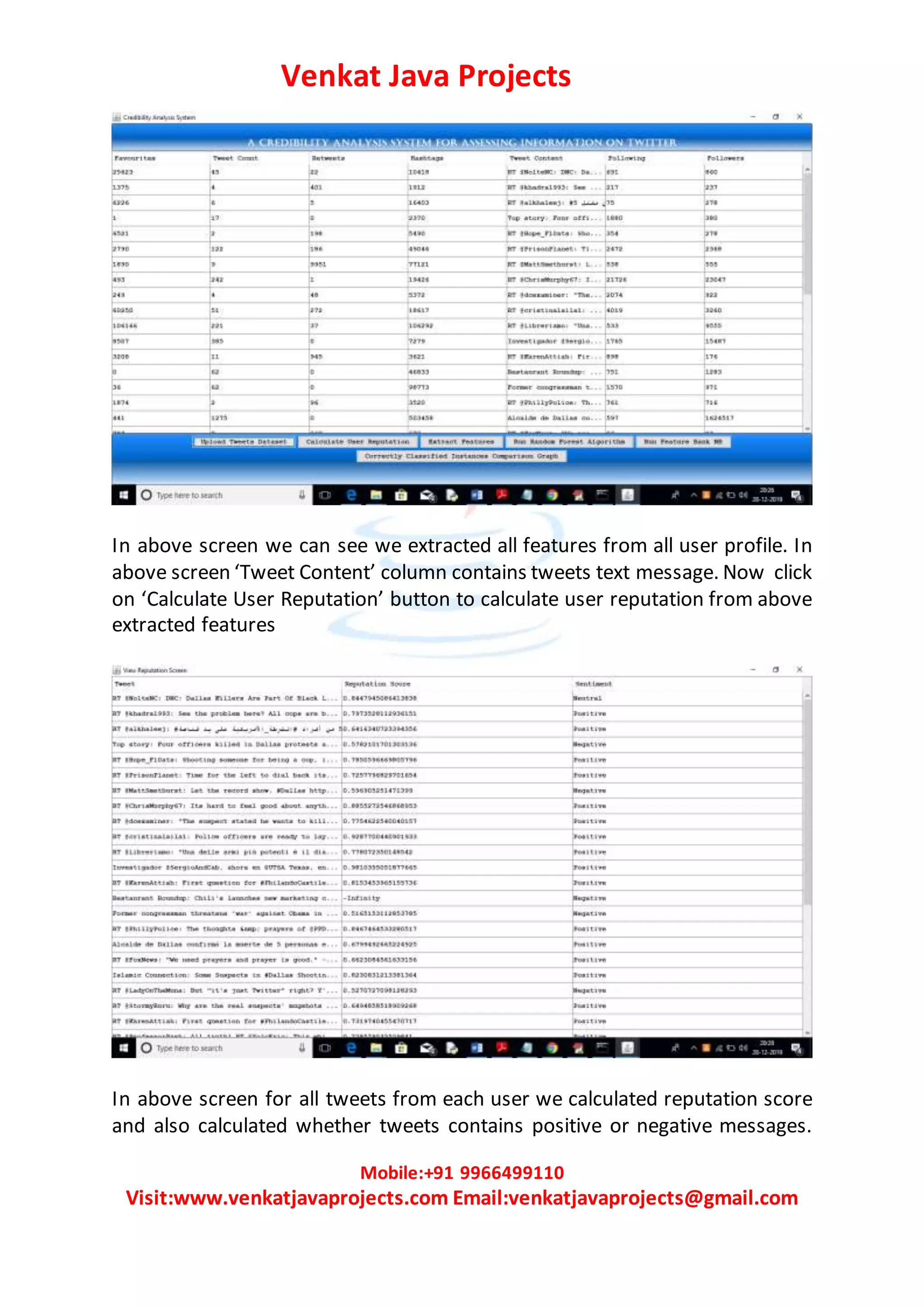
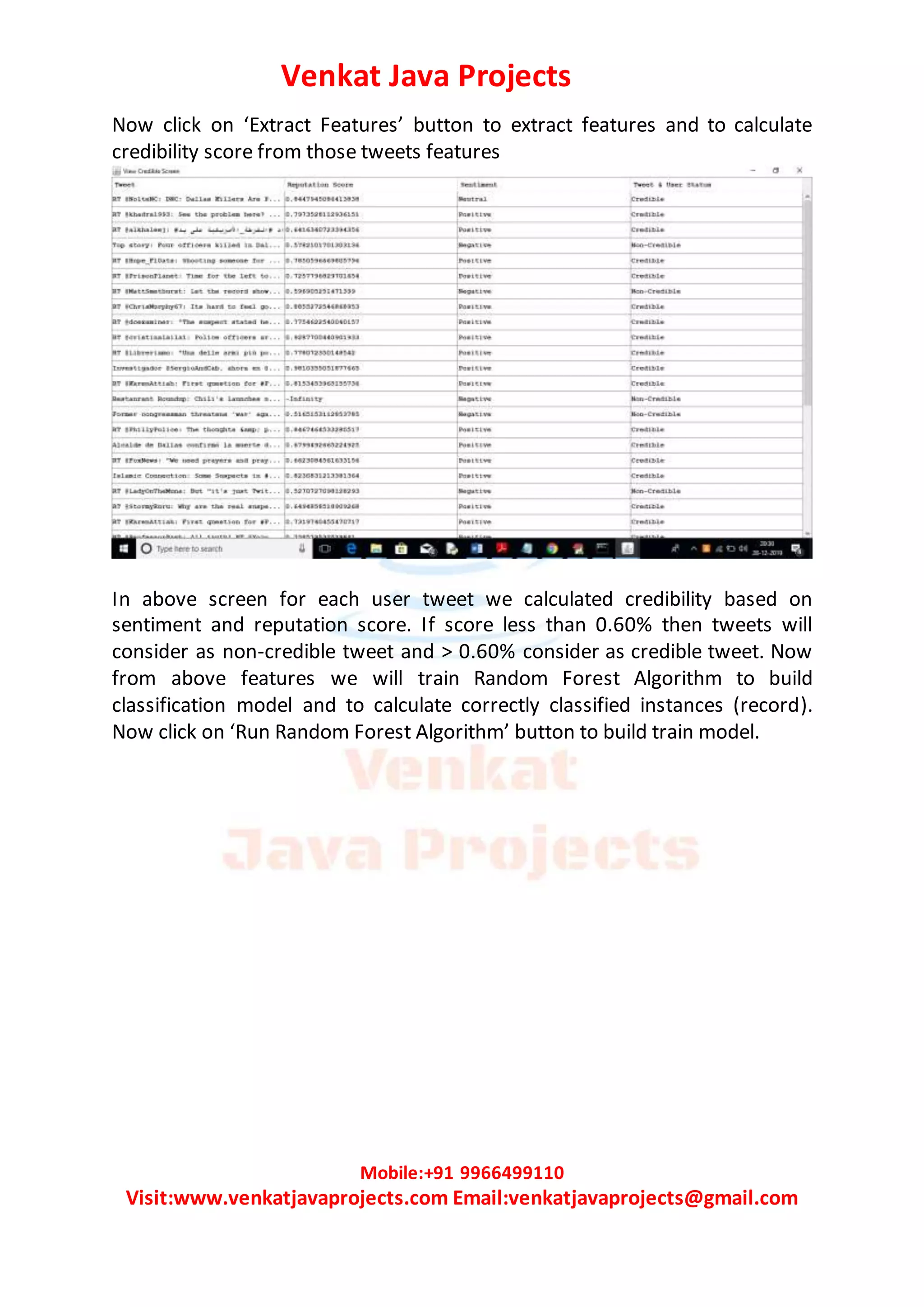
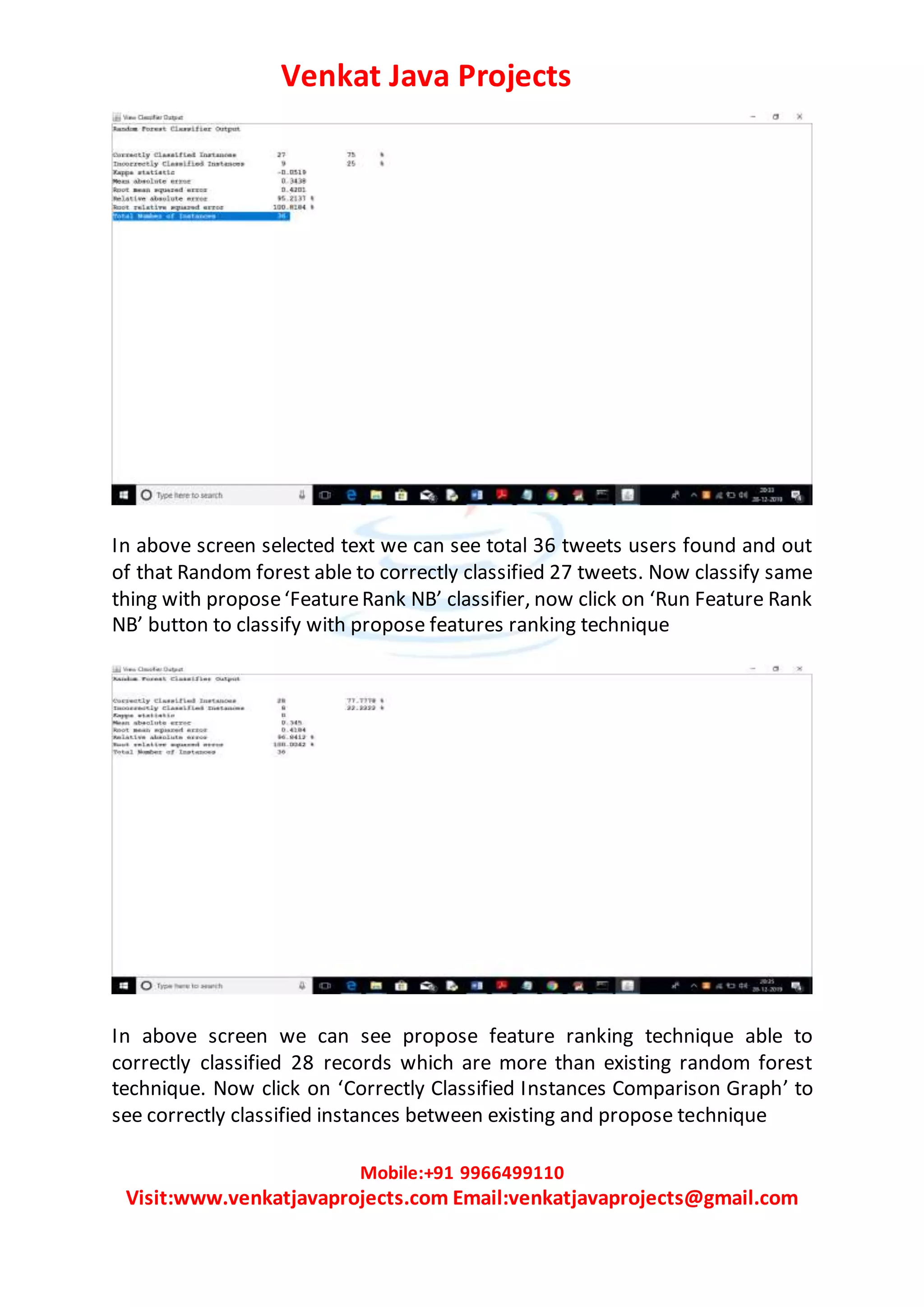


The document describes a credibility analysis system for assessing the credibility of tweets. It uses four components: 1) a reputation based component that calculates a reputation score based on account features like followers, retweets, favorites, etc., 2) a classifier engine like Random Forest or Naive Bayes to classify tweets as genuine or fake, 3) a user experience component using sentiment analysis to analyze the positivity or negativity of tweets, and 4) a feature ranking algorithm to select important tweet features. The system is implemented using a Twitter dataset, calculates reputation scores, extracts features, runs random forest and the proposed FeatureRank NB algorithm for classification, and compares their correctly classified instances.



































































