명령형 언어
명령형 언어는“가변”이면서 “공유”되는 상태에만
동시성 프로그래밍을 적용할 수 있는 제약조건이 있다
4.
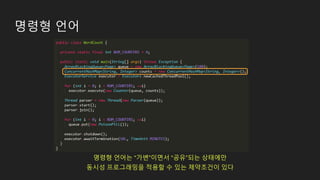
가변 상태의 위험
❖숨겨진가변 상태
➢ 현재 보이는 코드와 사용 중인 API의 문서를 보고서는 가변상태 여부를 파악하기 어렵다.
➢ 아래 코드는 그냥 보기엔 “가변 상태”를 갖지 않기 때문에 스레드 안정성이 보장되어 보인다.
5.
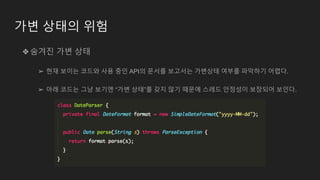
가변 상태의 위험(계속)
❖탈출한 가변 상태
➢ 아래 코드는 players 리스트는 private로 선언되었고,
synchronized를 통해 addPlayer()와 getPlayerIterator() 메서드에 접근하고 있다.
➢ 아래 코드는 겉으로는 “스레드-안정성”을 보장하는 것처럼 보인다.
getPlayerIterator() 의 리턴 값
players.iterator()가 사용되는 동안
addPlayer() 를 호출한다면 문제가 발생할 수 있다.
즉, 사용 중인 iterator의 원본 데이터에
변경이 발생하기 때문이다.
(ConcurrentModificationException)
6.
가변 상태의 위험(계속)
함수형 프로그래밍이
“동시성”, “병렬성”에 유리한 이유
함수형 프로그램은 가변 상태가 존재하지 않는다.
따라서 원천적으로 가변 상태의 위험에서 회피할 수 있다.
7.
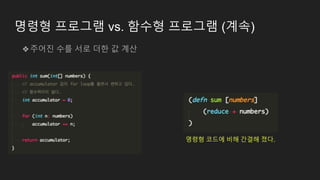
명령형 프로그램 vs.함수형 프로그램
❖주어진 수를 서로 더한 값 계산
Java
Clojure
8.
명령형 프로그램 vs.함수형 프로그램 (계속)
❖주어진 수를 서로 더한 값 계산
syntax : (reduce func [init val] coll)
example :
(reduce + [1 2 3 4 5]) ;;=> 15
(reduce + 1 [2 3]) ;;=> 6
9.
명령형 프로그램 vs.함수형 프로그램 (계속)
❖주어진 수를 서로 더한 값 계산
명령형 코드에 비해 간결해 졌다.
Lazy Sequence
❖Lazy Sequence
➢Lazy Evaluation
➢ 계산의 결과 값이 필요할 때까지 실제 계산을 늦추는 기법
실제 필요할 때 필요한 만큼만 생성하여 작업을 수행하여 성능 향상 가능
➢ (take n coll)
■ Collection에서 처음 n개의 아이템만을 리턴
➢ (iterate f x)
■ 주어진 함수(f)를 초기 값(x)에 적용 시키고,
다음 번 순차 방문 때는 함수를 그 결과에 적용하는 과정을 무한히 반복
■ Returns a lazy sequence of x, (f x), (f (f x))....
12.
참조 투명성
❖참조 투명성
➢어떤 함수가 호출 <위치> 및 <시점>에 관계없이 같은 입력 값에 대해서는 항상 같은 값을 반환
➢ 함수형 프로그램은 모든 함수가 참조 투명성 속성을 가진다.
즉, 계산 순서를 바꿀 수 있기 때문에 함수 코드의 병렬화가 쉬워진다.
➢ (+ (+ 1 2) (+ 3 4)) 코드는 함수 호출 순서에 관계없이 같은 결과 값을 가진다
(+ (+ 1 2) (+ 3 4)) ==> (+ (+ 1 2) 7) ==> (+ 3 7) ==> 10
(+ (+ 1 2) (+ 3 4)) ==> (+ 3 (+ 3 4)) ==> (+ 3 7) ==> 10
13.
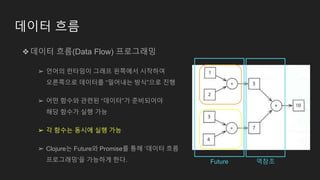
데이터 흐름
❖데이터 흐름(DataFlow) 프로그래밍
➢ 언어의 런타임이 그래프 왼쪽에서 시작하여
오른쪽으로 데이터를 “밀어내는 방식”으로 진행
➢ 어떤 함수와 관련된 “데이터”가 준비되어야
해당 함수가 실행 가능
➢ 각 함수는 동시에 실행 가능
➢ Clojure는 Future와 Promise를 통해 ‘데이터 흐름
프로그래밍’을 가능하게 한다. Future 역참조
14.
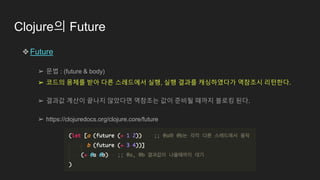
Clojure의 Future
❖Future
➢ 문법: (future & body)
➢ 코드의 몸체를 받아 다른 스레드에서 실행, 실행 결과를 캐싱하였다가 역참조시 리턴한다.
➢ 결과값 계산이 끝나지 않았다면 역참조는 값이 준비될 때까지 블로킹 된다.
➢ https://clojuredocs.org/clojure.core/future
15.
Clojure의 Promise
❖Promise
➢ Future와공통점
■ 값이 비동기적으로 준비된다
■ 값이 리턴되기 전까지 블로킹 된다
■ 역참조가 가능하다 : deref or @
➢ Future와 차이점
■ 실행될 코드 없이도 Promise를 만들 수 있다
■ deliver를 통해 값이 설정된다
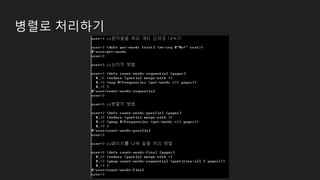
병렬로 처리하기
❖reduce vs.fold
➢ fold
■ clojure.core.reducers 패키지에 있는 함수
■ 분할 - 정복 전략을 통해 Parallel 하게 수행 가능 (reduce 동작을 병렬로 수행)
■ syntax : (fold [n] [combinef] reducef coll)
➢ reduce 함수를 fold 함수로 변경 : sum 함수를 병렬로 수행하도록 수정
약 2.5배 성능 향상
18.
clojure.core.reducers 라이브러리
❖clojure.core.reducers
➢ Alibrary for reduction and parallel folding
➢ 어떻게 축소시켜야 하는지에 대해 설명하는 일종의 조리법
➢ 실제 결과를 리턴하는 대신, 어떤 결과를 만들 수 있는 표현을 담는 조리법을 리턴
■ reduce 또는 fold에 전달되기 전까지 실행되지 않는다.
■ 중간 단계의 열이 만들어질 필요가 없기 때문에 더 효율적
■ fold가 컬렉션 내부에서 일어나는 모든 동작의 체인을 병렬화하는 것을 허용
19.
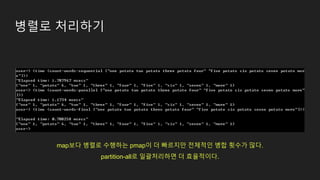
병렬로 처리하기
❖map vs.pmap
➢ map : (map f coll)
■ 함수(f)와 열(coll)이 주어지면
열(coll)에 담긴 각 요소에 함수(f)를 적용한 결과를 담은 새로운 열을 리턴
➢ pmap : (pmap f coll)
■ map과 동일하지만, 함수(f)가 병렬로 실행
❖partition-all
➢ 문법 : (partiton-all n) (partition-all n coll) (partiton-all n step coll)
➢ 하나의 열(coll)을 여러 개(n)의 열로 묶거나 분할한다.





![명령형 프로그램 vs. 함수형 프로그램 (계속)
❖주어진 수를 서로 더한 값 계산
syntax : (reduce func [init val] coll)
example :
(reduce + [1 2 3 4 5]) ;;=> 15
(reduce + 1 [2 3]) ;;=> 6](https://image.slidesharecdn.com/7-3-161024002258/85/7-3-8-320.jpg)





![병렬로 처리하기
❖reduce vs. fold
➢ fold
■ clojure.core.reducers 패키지에 있는 함수
■ 분할 - 정복 전략을 통해 Parallel 하게 수행 가능 (reduce 동작을 병렬로 수행)
■ syntax : (fold [n] [combinef] reducef coll)
➢ reduce 함수를 fold 함수로 변경 : sum 함수를 병렬로 수행하도록 수정
약 2.5배 성능 향상](https://image.slidesharecdn.com/7-3-161024002258/85/7-3-17-320.jpg)















![[추천] 색인기법 김성현](https://cdn.slidesharecdn.com/ss_thumbnails/random-110424155234-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)































![[SICP] 3.4 Concurrency : Time is of the essence - 병행성 : 시간은 중요하다.](https://cdn.slidesharecdn.com/ss_thumbnails/3-4-090608224115-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)

