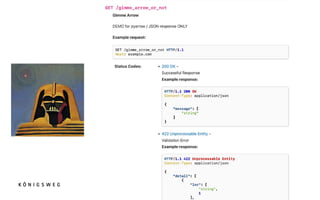
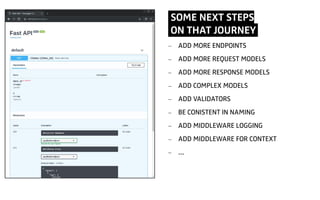
The document discusses key aspects of FastAPI, a high-performance web framework, emphasizing its ease of use, scalability, and automatic documentation features. It also explores various use cases, challenges in implementation, and the importance of closely related libraries like Pydantic and Starlette for effective API development. Throughout, the speaker shares personal insights and lessons learned from working with FastAPI while highlighting community resources and documentation practices.












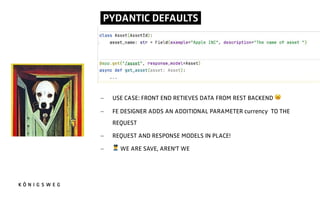
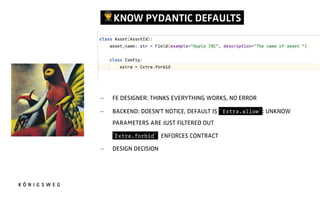
![PYDANTIC.
- PYDANTIC PARSES THE INPUT DATA
- IF THE DATA CANNOT BE CASTED INTO THE TYPE PYDANTIC RAISES A
USER FRIEDLY EXCEPTION
- ["1", "2", "3"] is a valid List[int] -> [1, 2, 3]
h"ps://docs.pydan.c.dev](https://image.slidesharecdn.com/5thingsfastapipyconit-230607213302-013ea66e/85/5-Things-about-fastAPI-I-wish-we-had-known-beforehand-15-320.jpg)