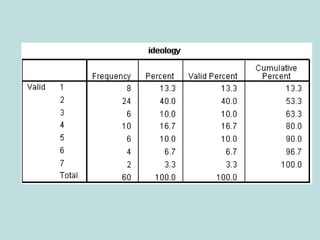
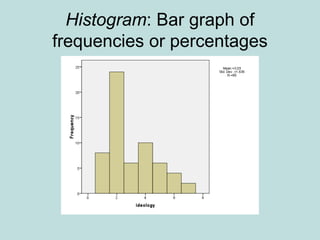
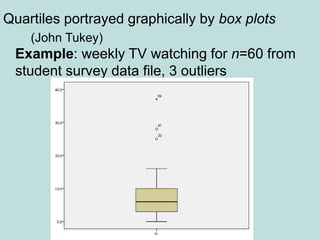
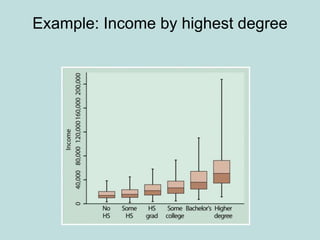
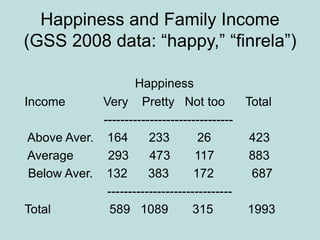
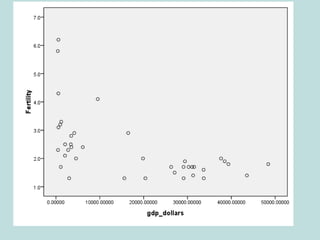
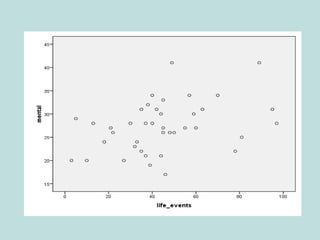
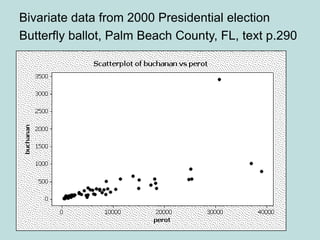
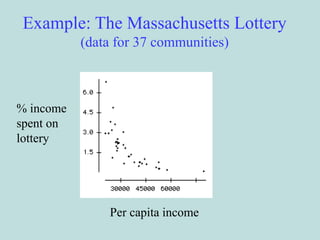
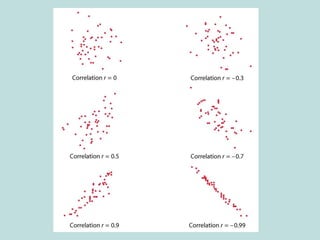
This document provides an overview of descriptive statistics techniques for summarizing and describing data, including both categorical and quantitative variables. It discusses frequency distributions, histograms, stem-and-leaf plots, numerical descriptions of center and variability (mean, median, standard deviation), bivariate descriptions using tables, scatterplots and correlation, and simple linear regression. The goal of descriptive statistics is to organize and summarize sample data in order to make inferences about the underlying population.