16
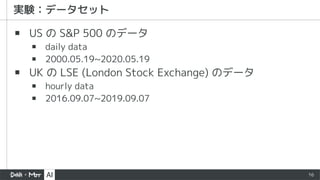
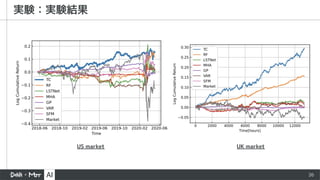
▪ US のS&P 500 のデータ
▪ daily data
▪ 2000.05.19~2020.05.19
▪ UK の LSE (London Stock Exchange) のデータ
▪ hourly data
▪ 2016.09.07~2019.09.07
17.
17
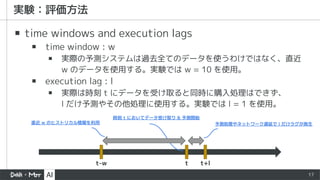
▪ time windowsand execution lags
▪ time window : w
▪ 実際の予測システムは過去全てのデータを使うわけではなく、直近
w のデータを使用する。実験では w = 10 を使用。
▪ execution lag : l
▪ 実際は時刻 t にデータを受け取ると同時に購入処理はできず、
l だけ予測やその他処理に使用する。実験では l = 1 を使用。
18.
18
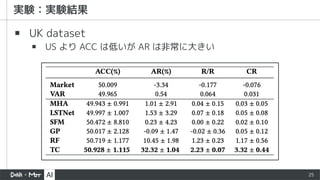
▪ Metrics (全て大きい方が良い)
▪Accuracy (ACC)
▪ +- の二値で計算
▪ Annualized Return (AR)
▪ 年間 cum return を全銘柄について平均したもの
▪ Sharpe Ratio (SR)
▪ 平均 cum return を cum return の標準偏差で割ったもの。変動係数?
▪ Calmar Ratio (CR)
▪ AR_i / MDD_i を全銘柄について平均したもの
19.
19
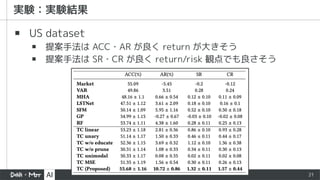
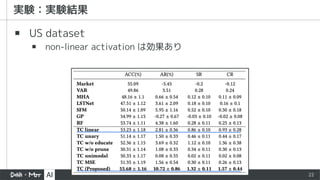
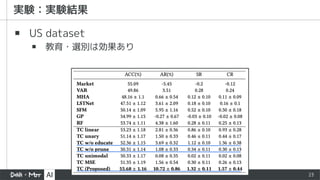
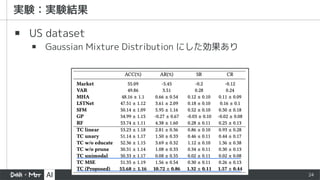
▪ Market
▪ auniform Buy-And-Hold strategy
▪ Vector Auto Regression (VAR)
▪ 過去の各銘柄の値の線形結合 (+誤差)
▪ Random Forest (RF)
▪ Multi Head Attention (MHA)
▪ Long-and Short-Term Networks (LSTNet)
▪ CNN + RNN の DNN






































![[DL Hacks] Deterministic Variational Inference for RobustBayesian Neural Netw...](https://cdn.slidesharecdn.com/ss_thumbnails/adobepdffile2-190628001736-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]SOLAR: Deep Structured Representations for Model-Based Reinforcement L...](https://cdn.slidesharecdn.com/ss_thumbnails/20190816-190816001737-thumbnail.jpg?width=640&height=640&fit=bounds)









