6
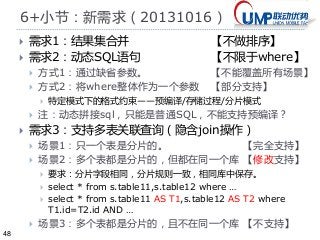
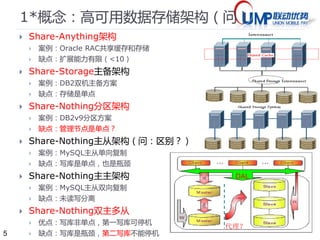
1+概念:数据分片Shard
实现shard 需要改变思维(DB设计,App使用)
尽量避免join - 关联查询
数据冗余/ 反范式
例:数据冗余for shard
shard before – comment(id, blog_id, content)
shard after – comment(id, blog_id, content, user_id)
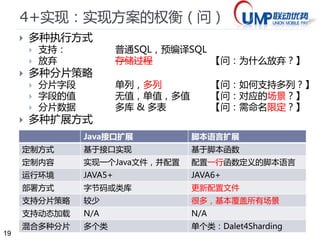
常见shard 策略
垂直分片
按功能分【如:论坛,博客】
水平分片
2 * N 【如定单,购买者与网店各一份】
N / n 【按日期或ID 范围分区】
Hash(N) % n 【按hash 分】
分区表查找法
7.
7
A
P
P
User1
User2
DAL
Proxy
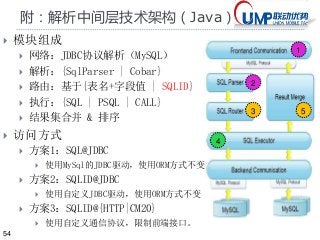
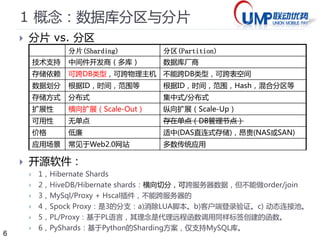
1*概念:数据访问层DAL实现
实现方式
进程内DAL API 接口组件
Java: Hibernate Shard,HiveDB, …
Python: Pyshards
进程外DAL Proxy 服务器
MySQL:MySql/Proxy,Amoeba,Cobar
PgSQL: PL/Proxy (Skype), PgPool-II
考虑因素:
业务场景:业务应用多少?——有很多
功能需求:需求是否固定?——不固定
分片规则:是否一成不变?——不确定
User1
User2
DAL
API
A
P
P
18
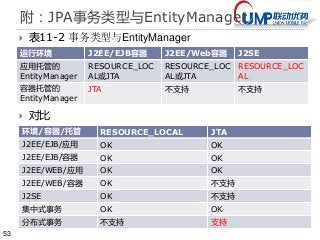
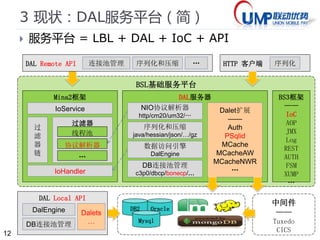
3*现状:多库同表的读写分离(问)
类名:Dalet4PSqlid
测试:DalClientsTest2.test_sqlrw_ok()
配置:
在dal_vrdb中配置虚拟数据库(第一为写库,其他为读库)
vdb.testdb = NWR111,testdb,testdb1,testdb2
在dal_psqlid中配置,以REST风格根据GET/PUT操作来区分读写。
GET.sql_select_user1 = SELECT id,other FROM user1 WHERE username like '%lius%'
PUT.sql_update_user1= UPDATE user1 SET `id`=id WHERE username like '%lius%’
PUT.sql_select_user1 = SELECT id,other FROM user1 WHERE username like '%lius%
PUT.psql_select_user1= SELECT id,other FROM user1 WHERE username like '%lius%
测试(使用vdb.testdb而不是testdb)
http://localhost:8081/dal/psqlid2/vdb.testdb/sql_select_user1.txt 读库读(testdb1,testdb2)
http://localhost:8081/dal/psqlid2/vdb.testdb/sql_select_user1.txt?METHOD=PUT 写库写操作
http://localhost:8081/dal/psqlid2/vdb.testdb/sql_update_user1.txt?METHOD=PUT 写库读操作
http://localhost:8081/dal/psqlid2/testdb/sql_select_user1.txt 直接操作写库
http://localhost:8081/dal/psqlid2/testdb1/sql_select_user1.txt 直接操作读库
http://localhost:8081/dal/psqlid2/vdb.testdb/psql_select_user1.txt?METHOD=PUT 预编译
问题:如表名也不同?插入后查询操作间隔小于复制延迟?
19.
19
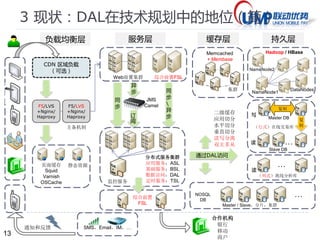
3 现状:同库多表的查询(问)
类名:Dalet4PSqlid
配置:在dal_psqlid中配置语句。
GET.user_cross0 = select * from user1,user2;
GET.user_union0 = select * from user1 union all select * from user2;
GET.user_cross = select user1.other,user2.other from user1,user2;
GET.user_union =select other from user1 union all select other from user2;
测试:
http://localhost:8081/dal/psqlid2/testdb/user_cross.txt
http://localhost:8081/dal/psqlid2/testdb/user_union.txt
问题:
上面两个查询语句的区别?
#2 【修改历史】
Version 5.0.20130606 初期版本。
Version 5.1.20130608 +写库读操作修改测试验证。+脚本语言选择。*设计原则。
Version 5.2.20130619 +性能测试,+用例和测试
Version 5.2.20130620 +其它新需求,+功能测试(黄进),*性能自试(殷舒),*设计方案,+实现方案(比较),+发布地址
Version 5.3.20130621 *其它新需求(TODO)
Version 5.3.20130624 *相关约定(+SHARDING_FIRST),
Version 5.3.20130626 +例9单列分片普通SQL全局优先查询,+实现:新旧读写分离方式对比,*背景问题,*背景需求,
Version 5.3.20130626 *需求满足度(改为:需求和示例),个别细节修改(分片类型,新旧方式的对比)
Version 5.4.20130626 评审。隐藏部分内容(高可用数据存储架构,DAL技术选择,DAL服务平台,DAL地位,现状多表分离和多表查)
Version 5.5.20130628 发布。*新需求(陈瑛琦)支持DB2导出的归档数据文件;*相关约定:分隔符逗号改分号?!
Version 5.5.20130709 +新需求-结果合并
Version 5.6.20130802 +例10-x:多表分页
Version 5.6.20130814 *其他:框架拆分
Version 5.7.20131016 +例10-0:多表分页查询的参数
Version 5.7.20131016 +小节:新需求(TODO-1016)
Version 5.8.20140312 +数据分片,DAL实现,已有DAL方案
--------
分享:http://www.slideshare.net/nikeliu/20130626dal51-h
标题:联动优势数据访问层DAL架构和实践之五:访问分片数据
Architecture and Practice for DAL (5) Data Sharding
Architecture and Practice for Data Access Layer (5) Data Sharding
联动优势数据访问层DAL架构和实践之五:分片数据分片
说明:
How to implement a dalet to access sharding databases.
按照许超前的说法(见http://www.slideshare.net/xcq/ss-3629618),其实现的DAL与memcache比较,其性能差异主要在协议解析和查询分析上。
和已有DAL软件(如许超前DAL手机之家、陈思儒Amoeba/贺贤懋Cobar等)不一样,在前端访问方式的选择上,抛弃JDBC方式,而是为同一个dalet数据服务,同时提供自定义TCP长连接和HTTP长连接两种接口。
因而通过抛弃JDBC可以获得多方面的好处——
1)可减少S端协议解析和查询分析的开销;
2)也简化C端编程。
3)后端存储就不再限于RDB了,而可以是任意NOSQL、文件、缓存、甚至是Tuxedo等在线服务。
4)可以实现无状态了,更容易横向扩展。
5)从接口上就可消除join等关键字的误用,避免引起服务端负担过重。
--------
#19 GET.user_cross = select other from user1, user2;
GET.user_union = select other from user1 union all select other from user2;
# GET http://localhost:8081/dal/psqlid2/testdb/user_cross.txt
[{"other":"刘胜"},{"other":"吴锋海"},{"other":"彭飞"},{"other":"赵军"},{"other":"刘胜"},{"other":"吴锋海"},{"other":"彭
飞"},{"other":"赵军"},{"other":"刘胜"},{"other":"吴锋海"},{"other":"彭飞"},{"other":"赵军"},{"other":"刘胜"},{"other":"吴锋海"},{"other":"彭飞"},{"other":"赵军"}]
# GET http://localhost:8081/dal/psqlid2/testdb/user_union.txt
[{"other":"刘胜"},{"other":"吴锋海"},{"other":"彭飞"},{"other":"赵军"},{"other":"刘胜"},{"other":"吴锋海"},{"other":"彭飞"},{"other":"赵军"}]
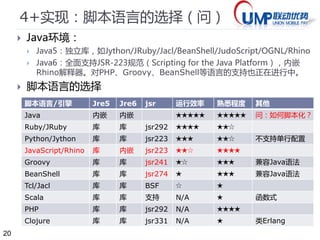
#24 JSR-223: Scripting for the Java Platform
JSR-241: Groovy – A New Standard Programming Language for the Java Platform
JSR-274: Standardizing BeanShell
JSR 292: Supporting Dynamically Typed Languages on the Java Platform
JSR-331: Java Constraint Programming API
https://code.google.com/p/red5/source/browse/java/scripting/branches/paulg_0.6/doc/engines.txt?spec=svn1276&r=1276
This is JSR-223 script engine for the Groovy language. Groovy is available for download at http://groovy.codehaus.org/. We have built and tested Groovy version 1.0 JSR-06.
This is JSR-223 script engine for JRuby - Java implementation of Ruby language. JRuby is available for download at http://jruby.sourceforge.net/. We have built and tested with JRuby version 0.9.0.
This is JSR-223 script engine for the Jacl language. Jacl is Java implementation of Tcl (Tool Command Language). This is available for download at http://tcljava.sourceforge.net/. We have built and tested with Jacl version 1.3.3.
This is JSR-223 script engine for the JudoScript language. JudoScript is available for download at http://www.judoscript.com/. We have built and tested with Judo version 0.9.
This is JSR-223 script engine for Jython - Java implementation of Python. Jython is available for download at http://www.jython.org/. We have built and tested with Jython version 2.1.
This is JSR-223 script engine for OGNL - Object Graph Navigation Language. OGNL is available for download at http://www.ognl.org/. We have built and tested with OGNL 2.6.9.
This is JSR-223 script engine for the Rhino / Javascript / ECMA language. Rhino is available for download at http://rhino.mozilla.org/. We have built and tested Groovy version 1.6 R2.
#30 GET.users_GetById3= select username,other from {SHARDING_TABLES} where id='{SHARDING_KEY1}'
GET.users_GetById3.js= function getTables(id) { if (id<100) return "testdb:user"; else return "testdb:user2"; }
#32 GET.user_GetById3x= select username,create_at from {SHARDING_TABLES} where username like '%{name}%'
GET.user_GetById3x.js= function getTables(dt6) { if (dt6>"201300") return "testdb:user2"; else return "testdb:user1"; }
#######################################################
http://localhost:8081/dal/shard2/user_GetById3x.txt?SHARDING_KEY1=201001&name=liu
http://localhost:8081/dal/shard2/user_GetById3x.txt?SHARDING_KEY1=201301&name=liu
#36 PUT.trans7_PutNoId3 = insert into {SHARDING_TABLES} (`id`, `dtime`, `content`) VALUES ('{id}', '{dtime}', '{content}')
PUT.trans7_PutNoId3.js= function getTables() { var day = new Date().getDay(); return "testdb:trans_"+day; }
#######################################################
# http://localhost:8081/dal/shard2/trans7_GetNoId3.txt
# http://localhost:8081/dal/shard2/trans7_PutNoId3.txt&id=99&dtime=20130606000099&content=NewTrans99
#38 CPU:Intel(R) Xeon(R) 1.86GHz *4
MEM:4G
##############################################################################
Dalet4Sharding
Server Software:
Server Hostname: 10.10.38.135
Server Port: 8082
Document Path: /dal/shard2/users_GetById16.txt?SHARDING_KEY1=1
Document Length: 132 bytes
Concurrency Level: 100
Time taken for tests: 9.997571 seconds
Complete requests: 10000
Failed requests: 0
Write errors: 0
Keep-Alive requests: 10000
Total transferred: 2740548 bytes
HTML transferred: 1320264 bytes
Requests per second: 1000.24 [#/sec] (mean)
Time per request: 99.976 [ms] (mean)
Time per request: 1.000 [ms] (mean, across all concurrent requests)
Transfer rate: 267.67 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 0 0 0.2 0 3
Processing: 2 98 65.5 82 723
Waiting: 2 98 65.5 82 723
Total: 2 98 65.6 82 723
Percentage of the requests served within a certain time (ms)
50% 82
66% 97
75% 112
80% 124
90% 161
95% 203
98% 299
99% 398
100% 723 (longest request)
##############################################################################
##############################################################################
Dalet4PSqlid
Server Software:
Server Hostname: 10.10.38.135
Server Port: 8082
Document Path: /dal/psqlid/testdb-db2/sql_select.txt?tables=sharding.t_test
Document Length: 101 bytes
Concurrency Level: 100
Time taken for tests: 10.467854 seconds
Complete requests: 10000
Failed requests: 0
Write errors: 0
Keep-Alive requests: 10000
Total transferred: 2430729 bytes
HTML transferred: 1010303 bytes
Requests per second: 955.31 [#/sec] (mean)
Time per request: 104.679 [ms] (mean)
Time per request: 1.047 [ms] (mean, across all concurrent requests)
Transfer rate: 226.69 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 0 0 0.2 0 3
Processing: 2 103 60.5 87 593
Waiting: 2 103 60.5 87 593
Total: 2 103 60.6 87 596
Percentage of the requests served within a certain time (ms)
50% 87
66% 105
75% 119
80% 131
90% 171
95% 213
98% 296
99% 359
100% 596 (longest request)
##############################################################################
#43 select id from {SHARDING_TABLES} where 1=1 limit {LIMIT_OFFSET},{LIMIT_ROWS}
SELECT * FROM (Select id,rownumber() over(ORDER BY id ASC) AS rn from {SHARDING_TABLES}) AS a WHERE a.rn >{LIMIT_OFFSET} AND a.rn<={LIMIT_OFFSET2}
JS函数返回格式 db1:s.tbl11,s.tbl12;db2:s2.tbl21,s2.tbl22;…
db1:s.tbl11,s.tbl12;db2:s2.tbl21,s2.tbl22;…
#49 缺点:在预编译/存储过程/分片模式下,对sql有特定的格式约束。
建议彻底杜绝跨库的Join操作。(优化join的方法就是不要join )
只要是多表关联查询本质上都是join操作。(可以支持,假设分片字段一致,分片规则一致。)
SELECT * FROM A,B WHERE A.ID = B.ID;
SELECT * FROM A JOIN B ON A.ID = B.ID;
SELECT * FROM A JOIN B USING(ID);
查询两表数据,这三条sql有什么不同——用MySQL的EXPLAIN 检测发现性能没有区别,只是写法不同








![11
2*背景:需求
最终目的:替核心数据库减负,同时降低开发难度
数据冗余:根据读写操作,使用不同的库。【Full-DB】
横向拆分:根据应用拆分多个库。【ShardDB】
纵向拆分:根据数据拆分多个库和多个表。【ShardDB】
需求细分: 【 实际场景千变万化]
后端访问方式: 【暂不考虑NOSQL存储】
基于JDBC的访问【普通SQL/预编译SQL/存储过程】
数据分片策略:
按读写操作的类型【读写分离】
按分片数据库库名【相同库相同表,相同库不同表】
按分片数据库表名【不同库相同表,不同库不同表】
以不变应万变
按单个分片字段的类型【整数ID值,字符串DT时间】
按单个分片字段值个数
没有分片字段值(全局) 【全局查询】
单个分片字段值(单条) 【单表查询】
两个分片字段值(范围) 【多表查询】
如何
按多个分片字段值分片,通过计算产生单一分片关键字【如hash】](https://image.slidesharecdn.com/20130626dal51h-130703025849-phpapp01/85/20130626-DAL-5-11-320.jpg)











![28
5 例1:单列分片普通SQL全局查询
0,场景
根据单一字段进行分片,不区分分片字段类型。
客户端未提交SHARDING_KEY1和SHARDING_KEY2参数值。
5,配置(dal_sharding文件)
GET.users_GetNoId3= select username,other from {SHARDING_TABLES} where
username like '{name}%'
GET.users_GetNoId3.js= function getTables() { return “testdb:user1;testdb:user2;
twitter:user_1;twitter:user_2”; }
7,测试地址和返回值
http://localhost:8081/dal/shard2/users_GetNoId.txt?name=lius 【返回】
{"twitter:user_2":[],"twitter:user_1":[{"username":"lius_1","other":"刘胜
_1"}],"testdb:user2":[{"username":"lius2","other":"刘胜
"}],"testdb:user1":[{"username":"lius","other":"刘胜"}]}
其他:
容错:自动处理js脚本返回中包含的空格。](https://image.slidesharecdn.com/20130626dal51h-130703025849-phpapp01/85/20130626-DAL-5-28-320.jpg)
![29
5 例2:单列分片普通SQL单表查询(单条)
0,场景
根据单一字段进行分片,不区分分片字段类型。
客户端只提交SHARDING_KEY1参数值,无SHARDING_KEY2参数值。
5,配置(dal_sharding文件)
GET.users_GetById3= select username,other from {SHARDING_TABLES} where
id='{SHARDING_KEY1}'
GET.users_GetById3.js= function getTables(id) { if (id<100) return "testdb:user1"; else
return "testdb:user2"; }
7,测试地址和返回值
http://localhost:8081/dal/shard2/users_GetById.txt?SHARDING_KEY1=1 【返回】
{"testdb:user1":[{"username":"lius","other":"刘胜"}]}
http://localhost:8081/dal/shard2/users_GetById.txt?SHARDING_KEY1=101 【返回】
{“testdb:user2”:[{“username”:“lius2”,“other”:“刘胜”}]}](https://image.slidesharecdn.com/20130626dal51h-130703025849-phpapp01/85/20130626-DAL-5-29-320.jpg)
![30
5 例3:单列分片普通SQL多表查询(范围)
0,场景
根据单一字段进行分片,不区分分片字段类型。
客户端同时提交SHARDING_KEY1和SHARDING_KEY2参数值。
5,配置(dal_sharding文件)
GET.psql_GetByRange3 = select id,other from {SHARDING_TABLES} where
id>{SHARDING_KEY1} AND id<{SHARDING_KEY2}
GET.psql_GetByRange3.js = function getTables(id1,id2) { if (id1>=100) return
"testdb:user2"; else if (id2<=100) return "testdb:user1"; else return
"testdb:user1;testdb:user2"; }
7,测试地址和返回值
http://localhost:8081/dal/shard2/users_GetByRange3.txt?SHARDING_KEY1=2&SHARD
ING_KEY2=102 【返回】{"testdb:user2":[{"id":101,"other":"刘胜
"}],"testdb:user1":[{"id":4,"other":"赵军"}]}
http://localhost:8081/dal/shard2/users_GetByRange3.txt?SHARDING_KEY1=3&SHARD
ING_KEY2=99 【返回】{"testdb:user1":[{"id":4,"other":"赵军"}]}
http://localhost:8081/dal/shard2/users_GetByRange3.txt?SHARDING_KEY1=100&SHA
RDING_KEY2=102 【返回】{“testdb:user2”:[{“id”:101,“other”:“刘胜”}]}](https://image.slidesharecdn.com/20130626dal51h-130703025849-phpapp01/85/20130626-DAL-5-30-320.jpg)
![31
5 例4:多列分片普通SQL查询
0,场景
根据多个字段混合计算的值进行分片,不区分分片字段类型。
客户端根据分片策略,使用多个字段的值计算生成SHARDING_KEY1/2等参数值。
服务端配置的SQL语句中无字段直接对应SHARDING_KEY1/2参数。而由JS脚本识别处理
SHARDING_KEY1/2参数。
5,配置(dal_sharding文件)
GET.user_GetById3x= select username,create_at from {SHARDING_TABLES} where
username like '%{name}%'
GET.user_GetById3x.js= function getTables(dt6) { if (dt6>"201300") return
"testdb:user2"; else return "testdb:user1"; }
7,测试地址和返回值
http://localhost:8081/dal/shard2/user_GetById3x.txt?SHARDING_KEY1=201001&name
=liu 【返回】{"testdb:user1":[{"id":1,"username":"lius"}]}
http://localhost:8081/dal/shard2/user_GetById3x.txt?SHARDING_KEY1=201301&name
=liu 【返回】{"testdb:user2":[{"id":101,"username":"lius2"}]}](https://image.slidesharecdn.com/20130626dal51h-130703025849-phpapp01/85/20130626-DAL-5-31-320.jpg)
![32
5 例5:单列分片预编译单表查询(字符串)
0,场景
按单一字段进行分片,不区分分片字段类型。但是,其他预编译参数需要区分类型。
客户端只提交SHARDING_KEY1参数值,无SHARDING_KEY2参数值。
5,配置(dal_sharding文件)
GET.psql_GetById3int = select id,username from {SHARDING_TABLES} where
id={SHARDING_KEY1} OR username={name.string}
GET.psql_GetById3int.js = function getTables(id) { if (id<100) return "testdb:user1";
else return "testdb:user2"; }
GET.psql_GetById3str = select id,username from {SHARDING_TABLES} where
username='{SHARDING_KEY1}'
GET.psql_GetById3str.js = function getTables(str) { if (str.indexOf("2")==-1) return
"testdb:user1"; else return "testdb:user2"; }
7,测试地址和返回值
http://localhost:8081/dal/shard2/psql_GetById3str.txt?SHARDING_KEY1=lius 【返回】
{"testdb:user1":[{"id":1,"username":"lius"}]}
http://localhost:8081/dal/shard2/psql_GetById3str.txt?SHARDING_KEY1=lius2 【返回】
{"testdb:user2":[{"id":101,"username":"lius2"}]}
http://localhost:8081/dal/shard2/psql_GetById3int.txt?SHARDING_KEY1=2&name.string=lius
http://localhost:8081/dal/shard2/psql_GetById3int.txt?SHARDING_KEY1=102&name.string=lius2
问题(见例6)](https://image.slidesharecdn.com/20130626dal51h-130703025849-phpapp01/85/20130626-DAL-5-32-320.jpg)
![33
5 例6:单列分片预编译多表查询(整型)
0,场景
按单一字段进行分片,分片字段不区分int和String类型,其他字段需要区分。
客户端同时提交SHARDING_KEY1和SHARDING_KEY2参数值。
5,配置(dal_sharding文件)
GET.psql_ByRange3int = select id,other from {SHARDING_TABLES} where
id>{SHARDING_KEY1} AND id<{SHARDING_KEY2}
GET.psql_ByRange3int.js = function getTables(id1,id2) { if (id1>=100) return
"testdb:user2"; else if (id2<=100) return "testdb:user1"; else return
"testdb:user1;testdb:user2"; }
7,测试地址和返回值
http://localhost:8081/dal/shard2/users_ByRange3int.txt?SHARDING_KEY1=2&SHARDI
NG_KEY2=102 【返回】{"testdb:user2":[{"id":101,"other":"刘胜
"}],"testdb:user1":[{"id":4,"other":"赵军"}]}
http://localhost:8081/dal/shard2/users_ByRange3int.txt?SHARDING_KEY1=3&SHARDI
NG_KEY2=99 【返回】{"testdb:user1":[{"id":4,"other":"赵军"}]}
http://localhost:8081/dal/shard2/users_ByRange3int.txt?SHARDING_KEY1=100&SHAR
DING_KEY2=102 【返回】{“testdb:user2”:[{“id”:101,“other”:“刘胜”}]}
问题:
有没有发现上面实现上的小花招?是否需要改进?](https://image.slidesharecdn.com/20130626dal51h-130703025849-phpapp01/85/20130626-DAL-5-33-320.jpg)
![34
5 例7:读写分离(不同库不同表)
0,场景
按单一字段进行分片,分片字段不区分int和String类型,其他字段需要区分。
允许多个写库以及不同表名。允许多个读库以及不同表名。
5,配置(dal_sharding文件)
GET.rwsplit_GetNoId3 = select username,other from {SHARDING_TABLES}
where username like '{name}%'
GET.rwsplit_GetNoId3.js = function getTables() { return
"testdb:user1;testdb:user2"; }
PUT.rwsplit_GetNoId3 = update {SHARDING_TABLES} set username=username
where username like '{name}%'
PUT.rwsplit_GetNoId3.js = function getTables() { return
"twitter:user_1;twitter:user_2"; }
7,测试地址和返回值
http://localhost:8081/dal/shard2/rwsplit_GetNoId3.txt?name=lius 【返回】
{"testdb:user2":[{"username":"lius2","other":"刘胜
2"}],"testdb:user1":[{"username":"lius","other":"刘胜"}]}
http://localhost:8081/dal/shard2/rwsplit_GetNoId3.txt?name=lius&METHOD=PUT 【
返回】{"twitter:user_2":0,"twitter:user_1":1}](https://image.slidesharecdn.com/20130626dal51h-130703025849-phpapp01/85/20130626-DAL-5-34-320.jpg)
![35
5 例8:交易表按七日翻滚
0,场景
交易表按照交易时间(日期)进行分片,不同日期的交易数据,记录在不同库不同表中。
每周一/二/三/…/日的交易数据,分别记录在日表trans_1/trans_2/…/trans_7中。
客户端根据需要提交SHARDING_KEY1和SHARDING_KEY2参数值。
5,配置(dal_sharding文件)
GET.trans7_GetNoId3 = select * from {SHARDING_TABLES} where id>0
GET.trans7_GetNoId3.js = function getTables() { var day = new Date().getDay(); return
"testdb:trans_"+day; }
PUT.trans7_PutNoId3 = insert into {SHARDING_TABLES} (`id`, `dtime`, `content`) VALUES ('{id}',
'{dtime}', '{content}‘)
PUT.trans7_PutNoId3.js = function getTables() { var day = new Date().getDay(); return
"testdb:trans_"+day; }
7,测试地址和返回值
http://localhost:8081/dal/shard2/trans7_GetNoId3.txt 【返回】
{"testdb:trans_4":[{"id":1,"content":"交易信息4-
1","dtime":"20130404000001"},{"id":2,"content":"交易信息4-
2","dtime":"20130404000002"}]}
http://localhost:8081/dal/shard2/trans7_PutNoId3.txt&id=99&dtime=20130606000099&content=Ne
wTrans99](https://image.slidesharecdn.com/20130626dal51h-130703025849-phpapp01/85/20130626-DAL-5-35-320.jpg)




![41
5+例9:普通SQL单列分片全局优先查询
0,场景
(同例1)区别在于,客户端提交SHARDING_FIRST参数值为true,按顺序依次查询各表;有
结果就返回。且返回的Map中最多只有一项。
5,配置(dal_sharding文件)
GET.users_GetNoId3= select username,other from {SHARDING_TABLES} where
username like '{name}%'
GET.users_GetNoId3.js= function getTables() { return “testdb:user1;testdb:user2;
twitter:user_1;twitter:user_2”; }
7,测试地址和返回值
http://localhost:8081/dal/shard2/users_GetNoId.txt?name=lius&SHARDING_FIRST=tr
ue
【true时】{"twitter:user_1":[{"username":"lius_1","other":"刘胜_1"}]}
【false时】{"twitter:user_2":[],"twitter:user_1":[{"username":"lius_1","other":"刘胜
_1"}],"testdb:user2":[{"username":"lius2","other":"刘胜
"}],"testdb:user1":[{"username":"lius","other":"刘胜"}]}](https://image.slidesharecdn.com/20130626dal51h-130703025849-phpapp01/85/20130626-DAL-5-40-320.jpg)

![44
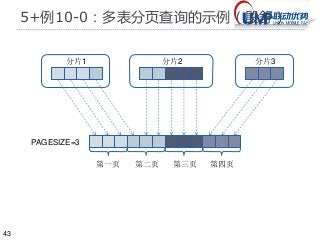
5+例10-0:多表分页查询的测试(刘胜)
测试环境:
共4个分表,各分表记录条数分别为4,4,2,2(范围0..11/共12条)
共4个分页,每页大小3。
测试结果:
http://localhost:8081/dal/shard3/MySqlPage.txt?PAGESIZE=3&PAGENUM=1
第1页:{"testdb:user1":[{"id":1},{"id":2},{"id":3}]}
第2页:{"testdb:user2":[{"id":101},{"id":102}],"testdb:user1":[{"id":4}]}
第3页:{"twitter:user_1":[{"id":1}],"testdb:user2":[{"id":103},{"id":104}]}
第4页:{"twitter:user_2":[{"id":2},{"id":4}],"twitter:user_1":[{"id":3}]}
表范围/条第1页第2页第3页第4页
全局行序号0..11/12 0..3/3 3..5/3 6..8/3 9..11/3
testdb:user1 0..3/4 0..2/3 3..3/1
testdb:user2 4..7/4 0..1/2 2..3/2
twitter:user_1 8..9/2 0..0/1 1..1/1
twitter:user_2 10..11/2 0..1/2
各分页总记录数共3条共3条共3条共3条](https://image.slidesharecdn.com/20130626dal51h-130703025849-phpapp01/85/20130626-DAL-5-43-320.jpg)
![45
5+例10-1:多表分页(MySql)
0,场景
按多表的总记录数,计算各分表的分页参数;分页和排序字段一致,不做全局排序。
3,确定uri对应的Dalet类,修改dal_rest配置
/dal/shard3/{sqlid} = com.bs3.app.dal.engine.Dalet4Sharding4Page
4,确定Dalet4ShardingPaged类对应的配置,修改beans2配置
com.bs3.app.dal.engine.Dalet4Sharding4Page = com/umpay/v3/dal/dal_sharding.properties
5,定义sqlid对应的sql和js语句,修改dal_sharding配置
GET.MySqlPage = select id from {SHARDING_TABLES} where 1=1 limit {LIMIT_OFFSET},{LIMIT_ROWS}
GET.MySqlPage.js = function getTables() { return "testdb:user1;testdb:user2;twitter:user_1;twitter:user_2"; }
GET.MySqlPage.count = select COUNT(*) from {SHARDING_TABLES} where 1=1
7,使用HTTP来测试
http://localhost:8081/dal/shard3/MySqlPage.txt?PAGESIZE=3&PAGENUM=1
第1页:{"testdb:user1":[{"id":1},{"id":2},{"id":3}]}
http://localhost:8081/dal/shard3/MySqlPage.txt?PAGESIZE=3&PAGENUM=2
第2页:{"testdb:user2":[{"id":101},{"id":102}],"testdb:user1":[{"id":4}]}
http://localhost:8081/dal/shard3/MySqlPage.txt?PAGESIZE=3&PAGENUM=3
第3页:{"twitter:user_1":[{"id":1}],"testdb:user2":[{"id":103},{"id":104}]}
http://localhost:8081/dal/shard3/MySqlPage.txt?PAGESIZE=3&PAGENUM=4&SHARDING_COOKIE
S=4_4_2_2 【注:缓存每个分片记录数】
第4页:{"twitter:user_2":[{"id":2},{"id":4}],"twitter:user_1":[{"id":3}]}](https://image.slidesharecdn.com/20130626dal51h-130703025849-phpapp01/85/20130626-DAL-5-44-320.jpg)
![46
5+例10-2:多表分页(MySql多预编译)
0,场景
按多表的总记录数,计算各分表的分页参数;分页和排序字段一致,不做全局排序。
3,确定uri对应的Dalet类,修改dal_rest配置
/dal/shard3/{sqlid} = com.bs3.app.dal.engine.Dalet4Sharding4Page
4,确定Dalet4ShardingPaged类对应的配置,修改beans2配置
com.bs3.app.dal.engine.Dalet4Sharding4Page = com/umpay/v3/dal/dal_sharding.properties
5,定义sqlid对应的sql和js语句,修改dal_sharding配置
GET.psql_MySqlPage = select id from {SHARDING_TABLES} where 1=1 limit {LIMIT_OFFSET},{LIMIT_ROWS}
GET.psql_MySqlPage.js = function getTables() { return "testdb:user1;testdb:user2;twitter:user_1;twitter:user_2"; }
GET.psql_MySqlPage.count = select count(*) from {SHARDING_TABLES} where 1=1
7,使用HTTP来测试
http://localhost:8081/dal/shard3/psql_MySqlPage.txt?PAGESIZE=5&PAGENUM=1
{"testdb:user2":[{"id":101}],"testdb:user1":[{"id":1},{"id":2},{"id":3},{"id":4}]}
http://localhost:8081/dal/shard3/psql_MySqlPage.txt?PAGESIZE=5&PAGENUM=2
{"twitter:user_2":[],"twitter:user_1":[{"id":1},{"id":3}],"testdb:user2":[{"id":102},{"id":103},{"id":104}]}
http://localhost:8081/dal/shard3/psql_MySqlPage.txt?PAGESIZE=5&PAGENUM=3&SHARDING_CO
OKIES=4_4_2_2
{"twitter:user_2":[{"id":2},{"id":4}]}](https://image.slidesharecdn.com/20130626dal51h-130703025849-phpapp01/85/20130626-DAL-5-45-320.jpg)