常见的数据存储
传统的数据库系统
Oracle
DB2、SQL Server
MySQL、PosgreSQL
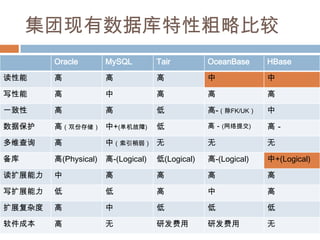
分布式数据库
Google Spanner & BigTable & MegaStore
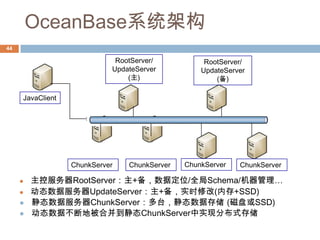
OceanBase、Hbase
缓存服务器 & KeyValue Store
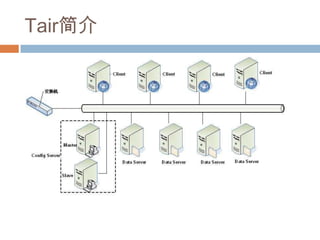
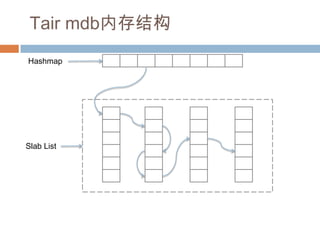
Tair
MemcacheD
Redis
5.
数据库的主要特性
ACID
原子性(Atomicity)
完整性(Consistency)
隔离性 (Isolation)
持久性 (Durability)
Relation & SQL
Structured Query Language (即SQL)
A Relational Model of Data for Large Shared Data
Banks (By Edgar Codd)
Cache的基本概念
Cache的定义
Cachingis a temp location where I store data in (data
that I need it frequently) as the original data is
expensive to be fetched, so I can retrieve it faster. 台
湾的翻译为“快取”,大陆为“缓存”
Cache的特征
有Backend的内容
处理的效率比走Backend要快
与Backend的内容之间可能会不一致
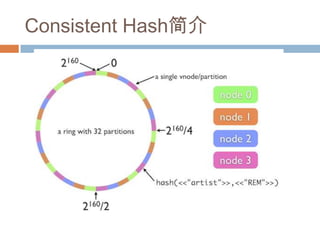
Cache的本质
Through Relaxing Consistency to Improve Scalability
34.
Cache的设计考虑
缓存的一致性维护问题
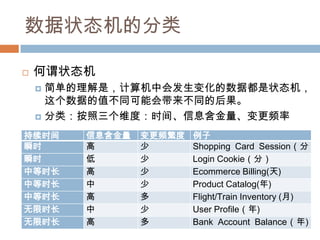
数据的具体读写比
商品信息?库存信息?用户信息?账户余额?
Backend数据变更频率
业务对一致性的要求
使用何种缓存策略
Write Through Vs Write Back Vs Write Back with
Compensate