Download to read offline






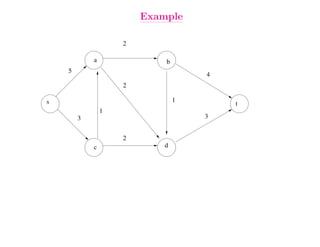
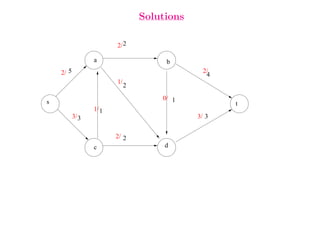






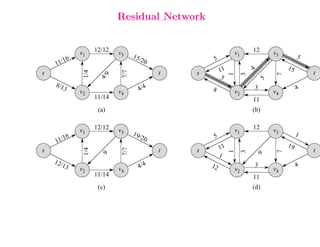
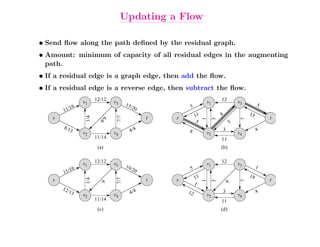
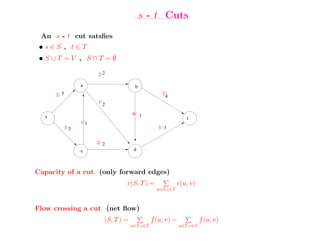

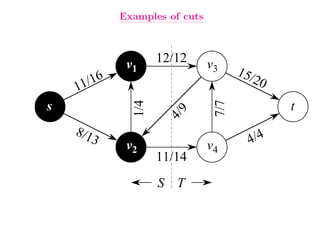



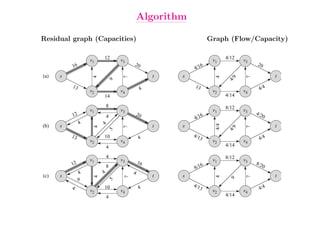
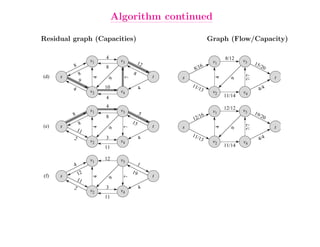



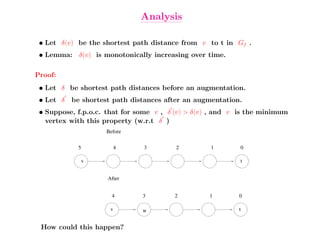
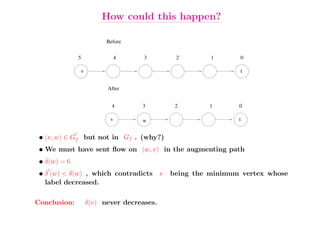







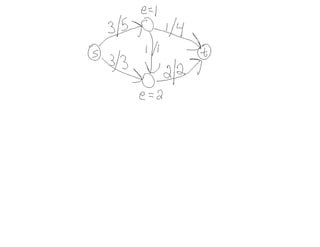




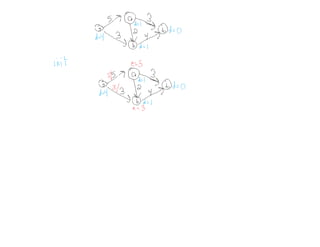
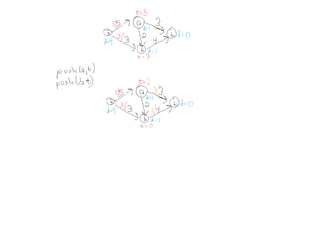
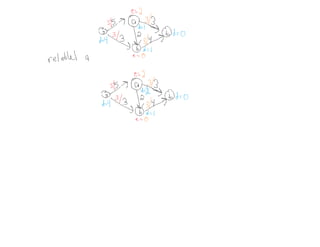
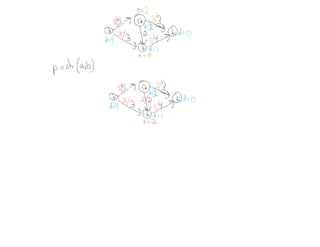
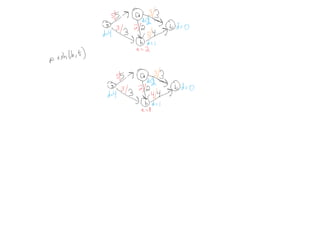
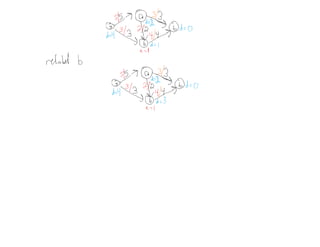
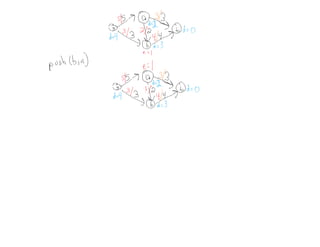
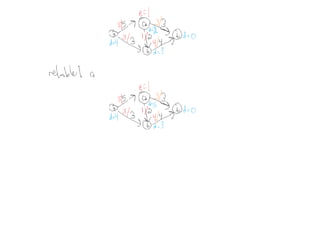
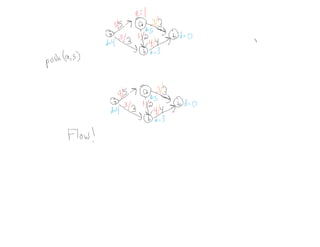














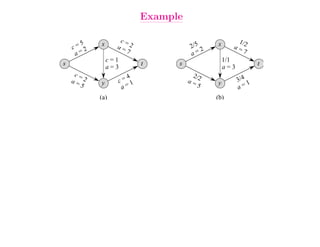






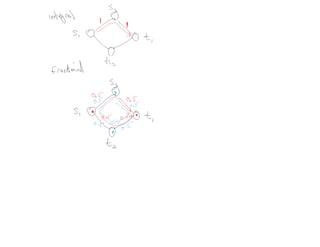

This document summarizes key concepts related to network flows, including maximum flows, minimum cost flows, and multicommodity flows. It provides an example of modeling internet routing as a maximum flow problem. It then describes the Ford-Fulkerson algorithm for finding maximum flows and some of its properties, including that the maximum flow equals the minimum cut. It discusses how the algorithm works by finding augmenting paths in the residual graph and updating the flow. Finally, it analyzes the running time of Ford-Fulkerson and describes how using shortest augmenting paths leads to a polynomial time algorithm.















































