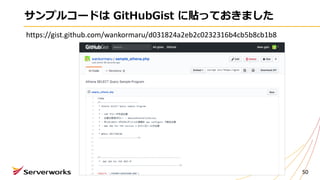
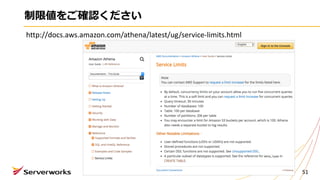
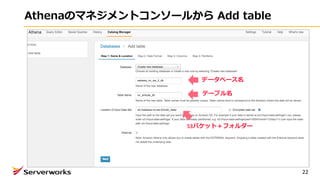
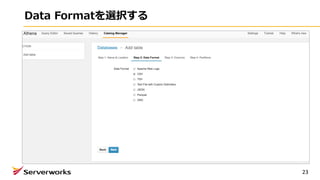
⾃⼰紹介
l すぎたに たかき
l2016/09 SWX JOIN
l カスタマーサポート課
l ⼤阪オフィス & おうち 勤務
l 技術
l AWSまだまだ勉強ちゅう!
l プログラミング⼤好き(たぶん)
l pythonも勉強ちう!
l プライベート
l 無類のイヌ好き
l 泳ぐ〜 (週2〜3回...2,000m/回)
2
うろちょろしてるコミュニティー
39
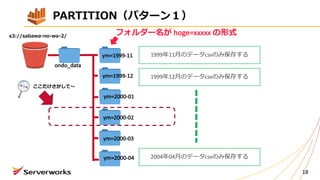
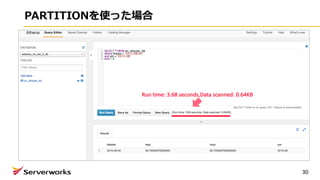
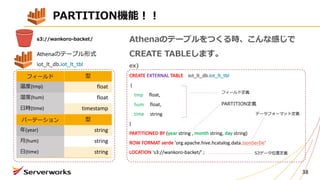
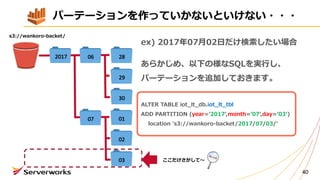
ALTER TABLE iot_lt_db.iot_lt_tbl
ADDPARTITION (year=ʼ2017',month=ʼ07',day=ʼ02')
location 's3://wankoro-backet/2017/07/02/'
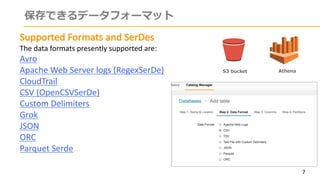
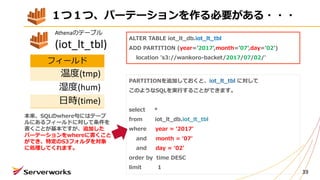
フィールド
温度(tmp)
湿度(hum)
⽇時(time)
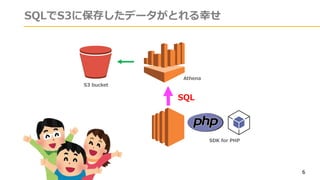
Athenaのテーブル
(iot_lt_tbl)
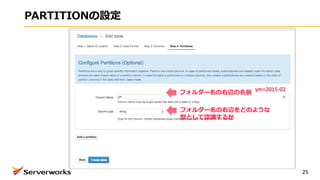
PARTITIONを追加しておくと、iot_lt_tbl に対して
このようなSQLを実⾏することができます。
select *
from iot_lt_db.iot_lt_tbl
where year = ʻ2017ʼ
and month = ʻ07ʼ
and day = ʻ02ʼ
order by time DESC
limit 1
本来、SQLのwhere句にはテーブ
ルにあるフィールドに対して条件を
書くことが基本ですが、追加した
パーテーションをwhereに書くこと
ができ、特定のS3フォルダを対象
に処理してくれます。
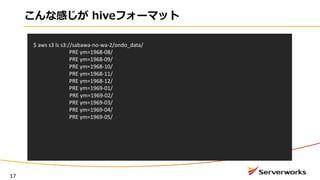
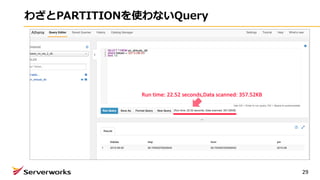
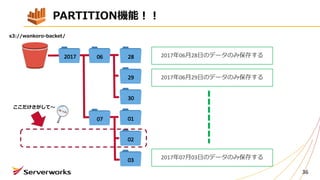
1つ1つ、パーテーションを作る必要がある・・・
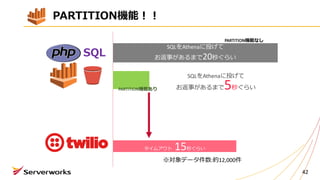
PARTITION機能!!
41
select * fromiot_lt_db.iot_lt_tbl
where time
BETWEEN date '2017-07-02' AND date '2017-07-03ʼ
order by time desc
limit 1
select * from iot_lt_db.iot_lt_tbl
order by time desc
limit 1
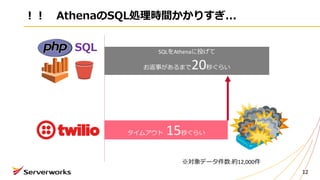
約20秒
約17秒
ちなみにこんな検索条件をつけても、RDSではないので速くなりません〜
※対象データ件数:約12,000件














![MSCK REPAIR TABLE
27
MSCK REPAIR TABLE [テーブル名]
実際のパーテーションを作る感じ・・(?)](https://image.slidesharecdn.com/2athenapub-170814084326/85/2-AWS-SDK-for-PHP-Athena-27-320.jpg)
![作成されたPARTITIONの確認
28
SHOW PARTITIONS [テーブル名]
作成されたPARTITION
これがSQLのWHERE句に記述できる](https://image.slidesharecdn.com/2athenapub-170814084326/85/2-AWS-SDK-for-PHP-Athena-28-320.jpg)








![aws configure を実⾏ (作ったIAMユーザのクレデンシャル情報を登録)
47
[sabawano-wa@ip-10-0-0-142 ~]$ cd ~
[sabawano-wa@ip-10-0-0-142 ~]$ aws configure --profile=sabawa-no-wa
AWS Access Key ID [None]: AKIAHOGEHOGEHOGEHOGEH
AWS Secret Access Key [None]: hoge123HOGE456/hoge123HOGE456/123HOGE456/
Default region name [None]: us-east-1
Default output format [None]: json](https://image.slidesharecdn.com/2athenapub-170814084326/85/2-AWS-SDK-for-PHP-Athena-47-320.jpg)
![AWS SDK for PHP v3 のインストール
48
Requirements : PHP >= 5.5.0
[sabawano-wa@ip-10-0-0-142 ~]$ cd ~/athena_test
[sabawano-wa@ip-10-0-0-142 ~]$ curl -sS https://getcomposer.org/installer | php
[sabawano-wa@ip-10-0-0-142 ~]$ php composer.phar require aws/aws-sdk-php](https://image.slidesharecdn.com/2athenapub-170814084326/85/2-AWS-SDK-for-PHP-Athena-48-320.jpg)