FMAچیست؟
•The FMA instructionset is an extension to the 128 and 256-bit Streaming SIMD
Extensions instructions.
•FMA perform fused multiply–add (FMA) operations.
•FMA4 operation has the form d = round(a · b + c)
•FMA3 operation has the form a = round(a · b + c)
the three-operand form (FMA3) requires that d be the same register as a, b or c
An FMA has only one rounding (it effectively keeps infinite precision for the
internal temporary multiply result), while an ADD + MUL has two
های برنامه کارگردش
Bandwidth Bound
numactl Memkind Cache mode
▷Simply run the whole
program in MCDRAM
▷No code modification
required
▷ Manually allocate
BW-critical memory to
MCDRAM
▷Memkind calls need to
be added.
▷ Allow the chip to figure
out how to use
MCDRAM
▷No code modification
required
مثال:دو ضرب سازیساده
ماتریس
#pragma omp parallel for
for (int i = 0; i < n; i++)
for (int j = 0; j < n; j++)
#pragma vector aligned
for (int k = 0; k < n; k++)
C[i*n+j]+=A[i*n+k]*B[k*n+j];
#pragma omp parallel for
for (int i = 0; i < n; i++)
for (int k = 0; k < n; k++)
#pragma vector aligned
for (int j = 0; j < n; j++)
C[i*n+j]+=A[i*n+k]*B[k*n+j];
Before: After:
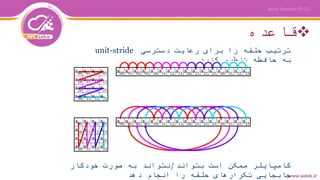
حلقه بندی قطعه:Unroll/Register
Blocking
for(int i = 0; i < m; i++) // Original code:
for (int j = 0; j < n; j++)
compute(a[i], b[j]); // Memory access is unit-stride in j
// Step 1: strip-mine outer loop
for (int ii = 0; ii < m; ii += TILE)
for (int i = ii; i < ii + TILE; i++)
for (int j = 0; j < n; j++)
compute(a[i], b[j]); // Same order of operation as original
// Step 2: permute and vectorize outer loop
for (int ii = 0; ii < m; ii += TILE)
#pragma simd
for (int j = 0; j < n; j++)
for (int i = ii; i < ii + TILE; i++)
compute(a[i], b[j]); //each vector in b[j] a total of TILE time
1
2
3
1
2
3
4
5
1
2
3
4
5
6
35.
روشLoop Fusion(ادغام
حلقه)
ها حلقهادغام بوسیله کش از مجدد استفاده
الینی پایپ پردازش فرآیند یک در
MyData* data = new MyData(n);
for (int i = 0; i < n; i++)
Initialize(data[i]);
for (int i = 0; i < n; i++)
Stage1(data[i]);
for (int i = 0; i < n; i++)
Stage2(data[i]);
MyData* data = new MyData(n);
for (int i = 0; i < n; i++) {
Initialize(data[i]);
Stage1(data[i]);
Stage2(data[i]);
}
اجانبی مثبت ثرات:،شوند می جابجا مراحل بین کمتری داده
کارایی افزایش ،حافظه به ارجاعات کاهش
1
2
3
4
5
6
7
8
9
10
1
2
3
4
5
6
7
8
9
10
11
FLOPsاز تعدادی
ها پردازندهAMDBobcat:
1.5 DP FLOPs/cycle: scalar SSE2 addition + scalar SSE2 multiplication every other cycle
4 SP FLOPs/cycle: 4-wide SSE addition every other cycle + 4-wide SSE multiplication every other cycle
AMD Jaguar:
3 DP FLOPs/cycle: 4-wide AVX addition every other cycle + 4-wide AVX multiplication in four cycles
8 SP FLOPs/cycle: 8-wide AVX addition every other cycle + 8-wide AVX multiplication every other cycle
ARM Cortex-A9:
1.5 DP FLOPs/cycle: scalar addition + scalar multiplication every other cycle
4 SP FLOPs/cycle: 4-wide NEON addition every other cycle + 4-wide NEON multiplication every other cycle
ARM Cortex-A15:
2 DP FLOPs/cycle: scalar FMA or scalar multiply-add
8 SP FLOPs/cycle: 4-wide NEONv2 FMA or 4-wide NEON multiply-add
Qualcomm Krait:
2 DP FLOPs/cycle: scalar FMA or scalar multiply-add
8 SP FLOPs/cycle: 4-wide NEONv2 FMA or 4-wide NEON multiply-add
IBM PowerPC A2 (Blue Gene/Q), per core:
8 DP FLOPs/cycle: 4-wide QPX FMA every cycle
SP elements are extended to DP and processed on the same units
IBM PowerPC A2 (Blue Gene/Q), per thread:
4 DP FLOPs/cycle: 4-wide QPX FMA every other cycle
SP elements are extended to DP and processed on the same units
Intel Xeon Phi (Knights Corner), per core:
16 DP FLOPs/cycle: 8-wide FMA every cycle
32 SP FLOPs/cycle: 16-wide FMA every cycle























![مثال:دو ضرب سازی ساده
ماتریس
#pragma omp parallel for
for (int i = 0; i < n; i++)
for (int j = 0; j < n; j++)
#pragma vector aligned
for (int k = 0; k < n; k++)
C[i*n+j]+=A[i*n+k]*B[k*n+j];
#pragma omp parallel for
for (int i = 0; i < n; i++)
for (int k = 0; k < n; k++)
#pragma vector aligned
for (int j = 0; j < n; j++)
C[i*n+j]+=A[i*n+k]*B[k*n+j];
Before: After:](https://image.slidesharecdn.com/04memorytrafficfundamentalsofparallelismandcodeoptimization-www-200426101339/85/04-memory-traffic_fundamentals_of_parallelism_and_code_optimization-www-astek-ir-copy-27-320.jpg)



![حلقه بندی قطعه:Cache
Blocking
for (int i = 0; i < m; i++) // Original code:
for (int j = 0; j < n; j++)
compute(a[i], b[j]); // Memory access is unit-stride in j
// Step 1: strip-mine inner loop
for (int i = 0; i < m; i++)
for (int jj = 0; jj < n; jj += TILE)
for (int j = jj; j < jj + TILE; j++)
compute(a[i], b[j]); // Same order of operation as original
// Step 2: permute
for (int jj = 0; jj < n; jj += TILE)
for (int i = 0; i < m; i++)
for (int j = jj; j < jj + TILE; j++) compute(a[i], b[j]);
// Re-use to j=jj sooner
1
2
3
1
2
3
4
5
1
2
3
4
5](https://image.slidesharecdn.com/04memorytrafficfundamentalsofparallelismandcodeoptimization-www-200426101339/85/04-memory-traffic_fundamentals_of_parallelism_and_code_optimization-www-astek-ir-copy-32-320.jpg)

![حلقه بندی قطعه:Unroll/Register
Blocking
for (int i = 0; i < m; i++) // Original code:
for (int j = 0; j < n; j++)
compute(a[i], b[j]); // Memory access is unit-stride in j
// Step 1: strip-mine outer loop
for (int ii = 0; ii < m; ii += TILE)
for (int i = ii; i < ii + TILE; i++)
for (int j = 0; j < n; j++)
compute(a[i], b[j]); // Same order of operation as original
// Step 2: permute and vectorize outer loop
for (int ii = 0; ii < m; ii += TILE)
#pragma simd
for (int j = 0; j < n; j++)
for (int i = ii; i < ii + TILE; i++)
compute(a[i], b[j]); //each vector in b[j] a total of TILE time
1
2
3
1
2
3
4
5
1
2
3
4
5
6](https://image.slidesharecdn.com/04memorytrafficfundamentalsofparallelismandcodeoptimization-www-200426101339/85/04-memory-traffic_fundamentals_of_parallelism_and_code_optimization-www-astek-ir-copy-34-320.jpg)
![روشLoop Fusion(ادغام
حلقه)
ها حلقه ادغام بوسیله کش از مجدد استفاده
الینی پایپ پردازش فرآیند یک در
MyData* data = new MyData(n);
for (int i = 0; i < n; i++)
Initialize(data[i]);
for (int i = 0; i < n; i++)
Stage1(data[i]);
for (int i = 0; i < n; i++)
Stage2(data[i]);
MyData* data = new MyData(n);
for (int i = 0; i < n; i++) {
Initialize(data[i]);
Stage1(data[i]);
Stage2(data[i]);
}
اجانبی مثبت ثرات:،شوند می جابجا مراحل بین کمتری داده
کارایی افزایش ،حافظه به ارجاعات کاهش
1
2
3
4
5
6
7
8
9
10
1
2
3
4
5
6
7
8
9
10
11](https://image.slidesharecdn.com/04memorytrafficfundamentalsofparallelismandcodeoptimization-www-200426101339/85/04-memory-traffic_fundamentals_of_parallelism_and_code_optimization-www-astek-ir-copy-35-320.jpg)




![سازهای ذخیرهStreaming
#pragma omp parallel for
for (int i = 1; i < height-1; i++)
#pragma omp simd
#pragma vector nontemporal
for (int j = 1; j < width-1; j++) out[i*width + j] =
-in[(i-1)*width + j-1] -in[(i-1)*width + j] - in[(i-1)*width + j+1]
-in[(i)*width + j-1] + 8*in[(i)*width + j] - in[(i)*width + j+1]
-in[(i+1)*width + j-1] -in[(i+1)*width+ j] - in[(i+1)*width+ j+1];
1
2
3
4
5
6
7
8](https://image.slidesharecdn.com/04memorytrafficfundamentalsofparallelismandcodeoptimization-www-200426101339/85/04-memory-traffic_fundamentals_of_parallelism_and_code_optimization-www-astek-ir-copy-40-320.jpg)