Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
美团点评技术团队
2,309 views
美团技术沙龙03 - 数据权限管理方案
AI-enhanced description
文档描述了数据权限管理方案,包括权限角色、用户、权限接口以及审批流程等内容。它提到不同安全级别的信息审查和审批路径。该方案涉及多个系统接口和角色配置,确保权限申请和审批的有效性。
Engineering
◦
Read more
5
Save
Share
Embed
Embed presentation
Download
Downloaded 158 times
1
/ 34
2
/ 34
3
/ 34
4
/ 34
5
/ 34
6
/ 34
7
/ 34
Most read
8
/ 34
9
/ 34
10
/ 34
Most read
11
/ 34
12
/ 34
13
/ 34
14
/ 34
15
/ 34
16
/ 34
17
/ 34
18
/ 34
19
/ 34
20
/ 34
21
/ 34
22
/ 34
23
/ 34
24
/ 34
Most read
25
/ 34
26
/ 34
27
/ 34
28
/ 34
29
/ 34
30
/ 34
31
/ 34
32
/ 34
33
/ 34
34
/ 34
More Related Content
PDF
Event Driven-Architecture from a Scalability perspective
by
Jonas Bonér
ODP
Introduction to BDD
by
Knoldus Inc.
PPT
Definition Of Done
by
Wei Zhu
PDF
Successfully Implementing BDD in an Agile World
by
SmartBear
PDF
Bdd Introduction
by
Skills Matter
DOC
Manoj resume
by
tekwissen
PDF
What is front-end development ?
by
Mahmoud Shaker
PPTX
Behavior Driven Development Testing (BDD)
by
Dignitas Digital Pvt. Ltd.
Event Driven-Architecture from a Scalability perspective
by
Jonas Bonér
Introduction to BDD
by
Knoldus Inc.
Definition Of Done
by
Wei Zhu
Successfully Implementing BDD in an Agile World
by
SmartBear
Bdd Introduction
by
Skills Matter
Manoj resume
by
tekwissen
What is front-end development ?
by
Mahmoud Shaker
Behavior Driven Development Testing (BDD)
by
Dignitas Digital Pvt. Ltd.
What's hot
PDF
Integrating Docker EE into Société Générale's Existing Enterprise IT Systems
by
Docker, Inc.
PPTX
[NDC17] Kubernetes로 개발서버 간단히 찍어내기
by
SeungYong Oh
PPTX
大型 Web Application 轉移到 微服務的經驗分享
by
Andrew Wu
PPTX
Defining tasks for User Stories
by
Martin Lapointe, M.T.I.
PDF
초보자를 위한 Git & GitHub
by
Yurim Jin
PDF
Docker Tutorial.pdf
by
MuhammadYusuf767705
PDF
Docker Advanced registry usage
by
Docker, Inc.
PDF
Patterns of a “good” test automation framework
by
Anand Bagmar
PDF
Agile Testing Framework - The Art of Automated Testing
by
Dimitri Ponomareff
PDF
Behavior Driven Development (BDD)
by
Ajay Danait
PPTX
Behavior driven development (bdd)
by
Rohit Bisht
PPTX
Acceptance criteria
by
Softheme
PDF
Ray: Enterprise-Grade, Distributed Python
by
Databricks
PDF
ArgoCD and Tekton: Match made in Kubernetes heaven | DevNation Tech Talk
by
Red Hat Developers
PDF
Docker-PPT.pdf for presentation and other
by
adarsh20cs004
PPTX
[발표자료] 오픈소스 기반 고가용성 Pacemaker 소개 및 적용 사례_20230703_v1.1F.pptx
by
ssuserf8b8bd1
PDF
User story and splitting workshop
by
Brian Sjoberg
PDF
OO Design and Design Patterns in C++
by
Ganesh Samarthyam
PPTX
Docker 101 - Nov 2016
by
Docker, Inc.
PDF
IT Consultant - Intellimatch/Recon/ERP
by
Sanjay Kumar
Integrating Docker EE into Société Générale's Existing Enterprise IT Systems
by
Docker, Inc.
[NDC17] Kubernetes로 개발서버 간단히 찍어내기
by
SeungYong Oh
大型 Web Application 轉移到 微服務的經驗分享
by
Andrew Wu
Defining tasks for User Stories
by
Martin Lapointe, M.T.I.
초보자를 위한 Git & GitHub
by
Yurim Jin
Docker Tutorial.pdf
by
MuhammadYusuf767705
Docker Advanced registry usage
by
Docker, Inc.
Patterns of a “good” test automation framework
by
Anand Bagmar
Agile Testing Framework - The Art of Automated Testing
by
Dimitri Ponomareff
Behavior Driven Development (BDD)
by
Ajay Danait
Behavior driven development (bdd)
by
Rohit Bisht
Acceptance criteria
by
Softheme
Ray: Enterprise-Grade, Distributed Python
by
Databricks
ArgoCD and Tekton: Match made in Kubernetes heaven | DevNation Tech Talk
by
Red Hat Developers
Docker-PPT.pdf for presentation and other
by
adarsh20cs004
[발표자료] 오픈소스 기반 고가용성 Pacemaker 소개 및 적용 사례_20230703_v1.1F.pptx
by
ssuserf8b8bd1
User story and splitting workshop
by
Brian Sjoberg
OO Design and Design Patterns in C++
by
Ganesh Samarthyam
Docker 101 - Nov 2016
by
Docker, Inc.
IT Consultant - Intellimatch/Recon/ERP
by
Sanjay Kumar
More from 美团点评技术团队
PDF
美团点评技术沙龙14:美团四层负载均衡
by
美团点评技术团队
PDF
美团点评技术沙龙14:美团云对象存储系统
by
美团点评技术团队
PDF
美团点评技术沙龙14美团云-Docker平台
by
美团点评技术团队
PDF
美团点评技术沙龙13-酒旅Hybrid架构体系及演进
by
美团点评技术团队
PDF
美团点评技术沙龙13-前端工程化开发方案app-proto介绍
by
美团点评技术团队
PDF
美团点评技术沙龙13-点评Titans框架的设计和实践
by
美团点评技术团队
PDF
美团点评沙龙12-LBS空间搜索架构的优化历程
by
美团点评技术团队
PDF
美团点评沙龙012-从零到千万量级的实时物流平台架构实践
by
美团点评技术团队
PDF
美团点评沙龙012-初创电商的物流摸索
by
美团点评技术团队
PDF
美团点评沙龙 飞行中换引擎--美团配送业务系统的架构演进之路
by
美团点评技术团队
PDF
美团点评技术沙龙011 - 团购系统流量和容量评估实践
by
美团点评技术团队
PDF
美团点评技术沙龙011 - 客户端用户体验数据量化
by
美团点评技术团队
PDF
美团点评技术沙龙011 - 移动app兼容性测试工具Spider
by
美团点评技术团队
PDF
美团点评技术沙龙010-美团Atlas实践
by
美团点评技术团队
PDF
美团点评技术沙龙010-点评RDS系统介绍
by
美团点评技术团队
PDF
美团点评技术沙龙010-Redis Cluster运维实践
by
美团点评技术团队
PDF
美团点评技术沙龙010-美团数据库自动化运维系统构建之路
by
美团点评技术团队
PDF
美团点评技术沙龙09 - 美团外卖中的单量预估及列表优化
by
美团点评技术团队
PDF
美团点评技术沙龙09 - 美团配送智能调度实践
by
美团点评技术团队
PDF
美团点评技术沙龙09 - 外卖O2O的用户画像实践
by
美团点评技术团队
美团点评技术沙龙14:美团四层负载均衡
by
美团点评技术团队
美团点评技术沙龙14:美团云对象存储系统
by
美团点评技术团队
美团点评技术沙龙14美团云-Docker平台
by
美团点评技术团队
美团点评技术沙龙13-酒旅Hybrid架构体系及演进
by
美团点评技术团队
美团点评技术沙龙13-前端工程化开发方案app-proto介绍
by
美团点评技术团队
美团点评技术沙龙13-点评Titans框架的设计和实践
by
美团点评技术团队
美团点评沙龙12-LBS空间搜索架构的优化历程
by
美团点评技术团队
美团点评沙龙012-从零到千万量级的实时物流平台架构实践
by
美团点评技术团队
美团点评沙龙012-初创电商的物流摸索
by
美团点评技术团队
美团点评沙龙 飞行中换引擎--美团配送业务系统的架构演进之路
by
美团点评技术团队
美团点评技术沙龙011 - 团购系统流量和容量评估实践
by
美团点评技术团队
美团点评技术沙龙011 - 客户端用户体验数据量化
by
美团点评技术团队
美团点评技术沙龙011 - 移动app兼容性测试工具Spider
by
美团点评技术团队
美团点评技术沙龙010-美团Atlas实践
by
美团点评技术团队
美团点评技术沙龙010-点评RDS系统介绍
by
美团点评技术团队
美团点评技术沙龙010-Redis Cluster运维实践
by
美团点评技术团队
美团点评技术沙龙010-美团数据库自动化运维系统构建之路
by
美团点评技术团队
美团点评技术沙龙09 - 美团外卖中的单量预估及列表优化
by
美团点评技术团队
美团点评技术沙龙09 - 美团配送智能调度实践
by
美团点评技术团队
美团点评技术沙龙09 - 外卖O2O的用户画像实践
by
美团点评技术团队
美团技术沙龙03 - 数据权限管理方案
1.
数据权限管理方案 技术工程部-数据组-曹娜 邮箱:caona02@meituan.com
2.
! u ! u ! u
/ / ! u !
3.
! u ! u ! u
/ / ! u !
4.
! ! ! ! ! A A B !
5.
(RBAC)! ! User! / ! Role! Permission! m-n
! m-n ! ! !!! !
6.
! ! A! B! ……..! A! B! ……..! A! C! ……..! !
7.
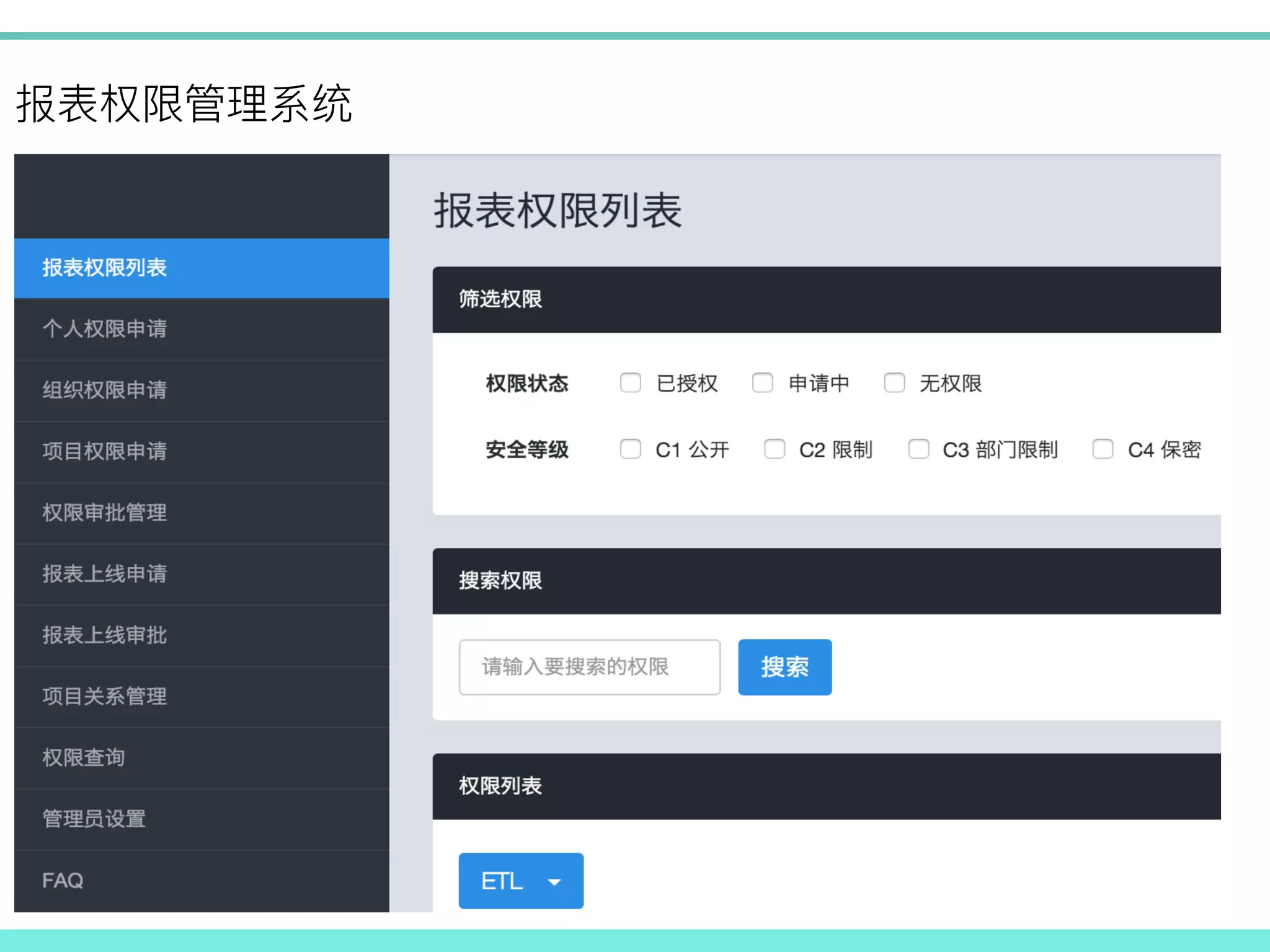
/ ! 权限创建 接口人 权限角色用户A 创建大象 权限请求 权限请求 用户-角色配置 接口人 角色-权限配置 接口人 权限接口 人 创建角色 邮件 授权 单点 单点 单点 大象 大象+邮件 权限请求 ! ! ! !
8.
! u ! u ! u
/ / ! u !
9.
! • ! ! • ! !
10.
! ! ! ! ! ! !
11.
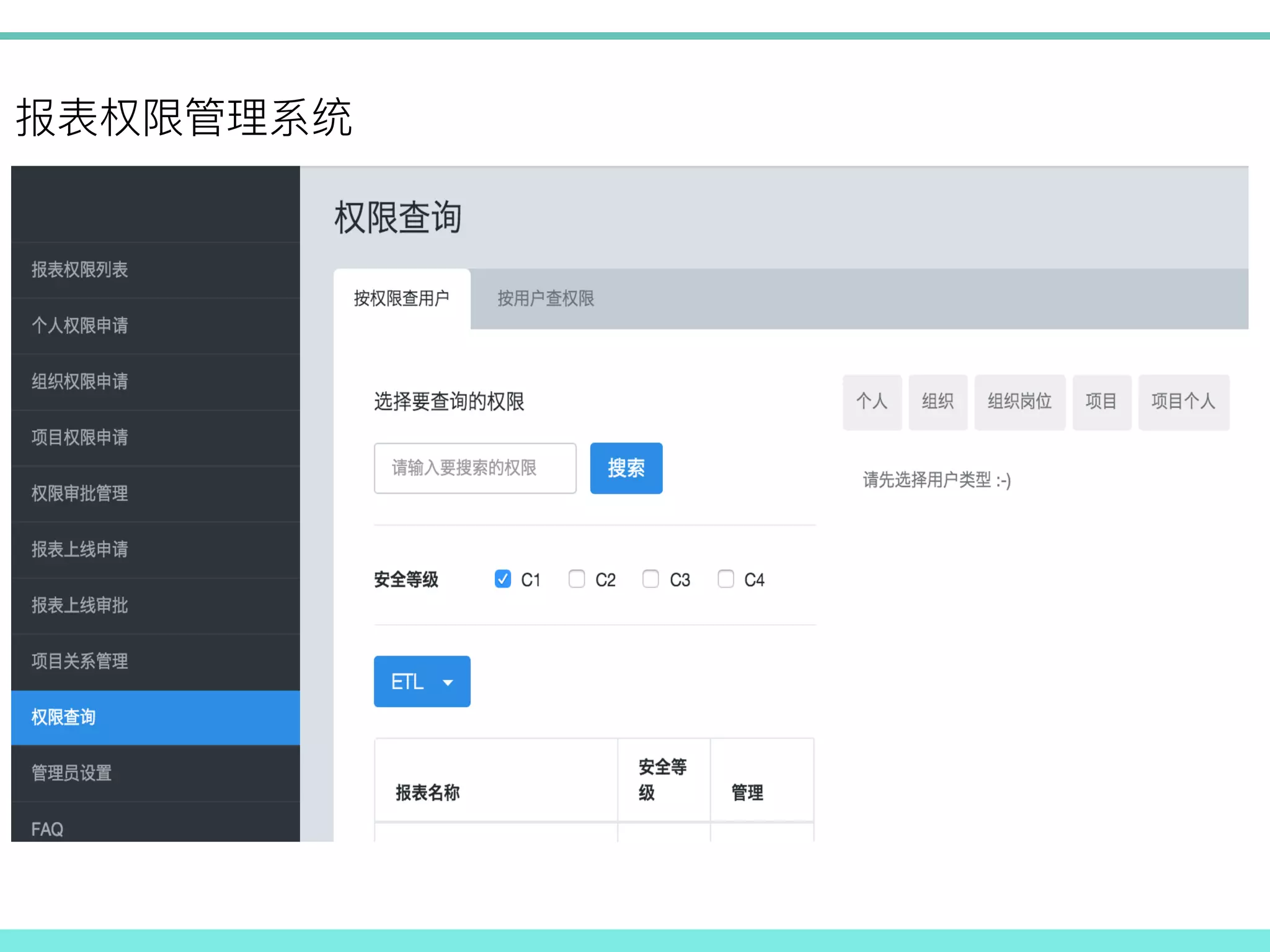
! ! ! / ! ! ! m:n
! m:n ! ! ! !! ! ! ! 1:1 ! m:n !
12.
/ ! 权限请求 系统入口 系统 审批 授权 系统
13.
!
14.
! UPM
15.
! u ! u ! u
/ / ! u !
16.
!
17.
! ! ! ! ! ! ! 3 5
18.
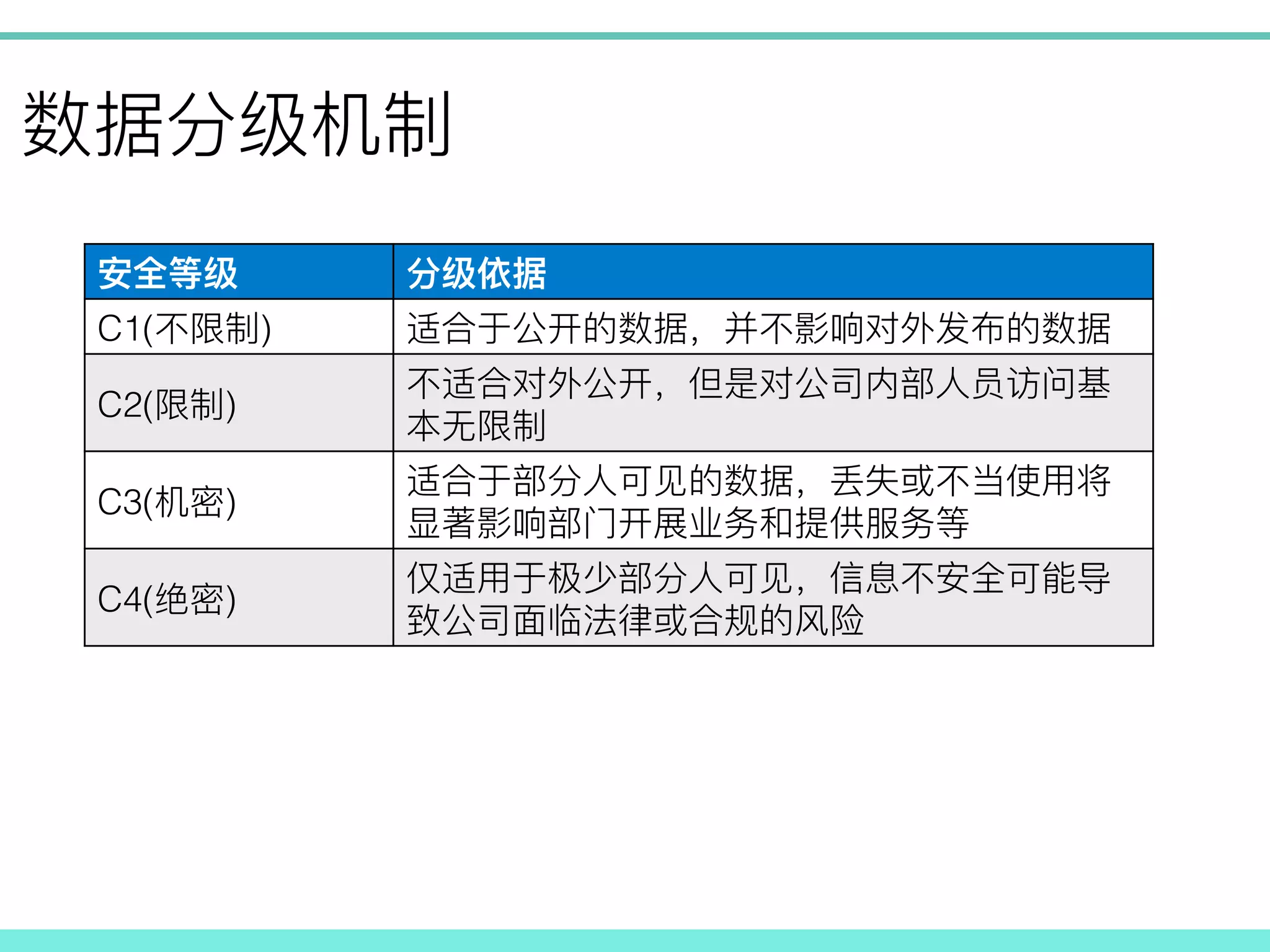
! C1( )! ! C2(
)! ! C3( )! ! C4( )! !
19.
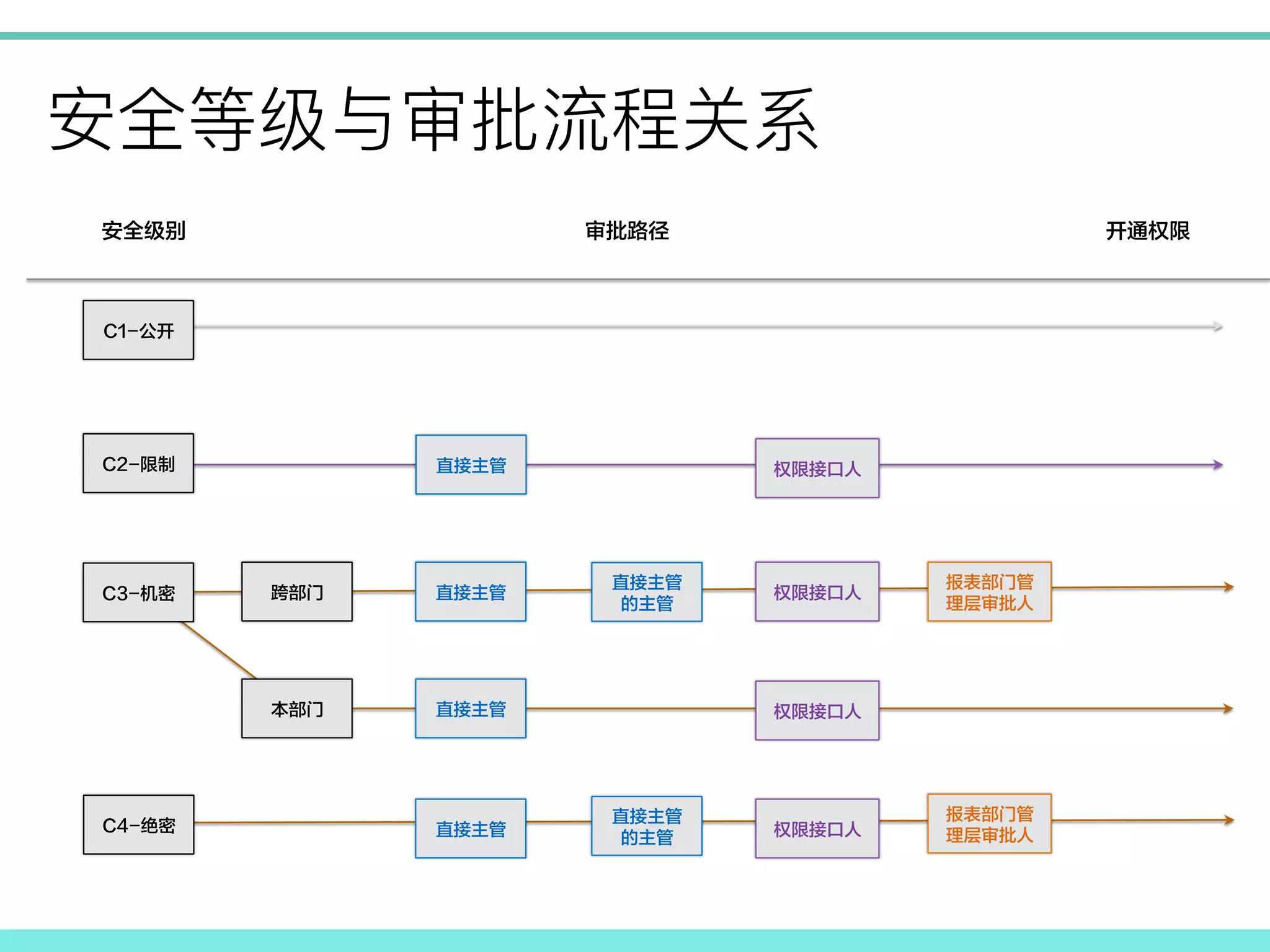
! C1-公开 C2-限制 C3-机密 C4-绝密 安全级别 审批路径 直接主管 直接主管 直接主管 的主管 权限接口人 报表部门管 理层审批人 权限接口人 权限接口人 报表部门管 理层审批人 直接主管 权限接口人 跨部门 本部门 直接主管 直接主管 的主管 开通权限
20.
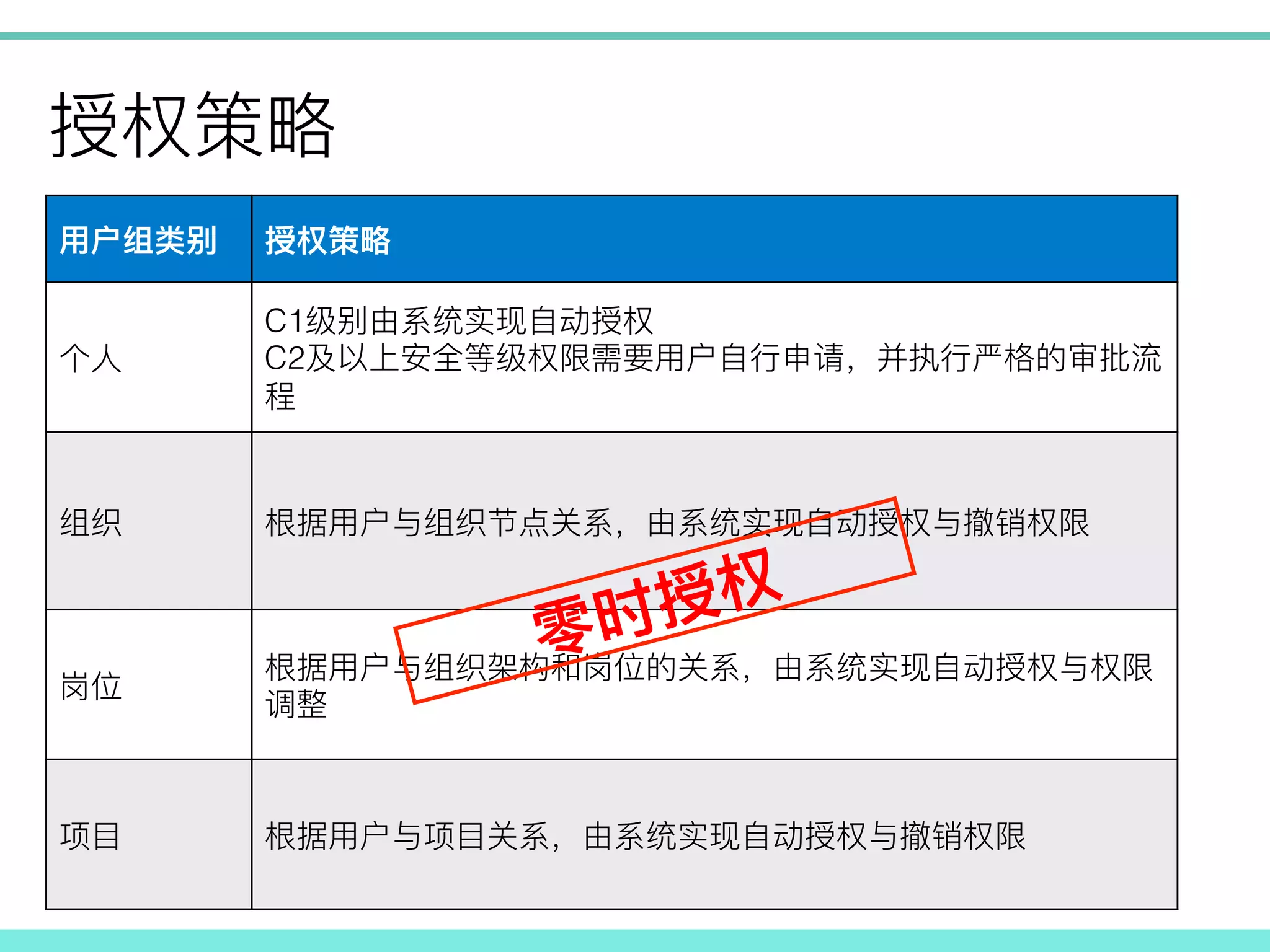
! ! C1 ! C2 ! ! ! ! ! !
!
21.
- ! 需求方 权限创建 接口人 权限 角色
用户 创建 上线 授权 JIRA 上线申请 大象 权限请求 权限请求 用户-角色配置 接口人 角色-权限配置 接口人 权限接口 人 创建角色 权限请求 邮件 授权 大象 大象+邮件 UPMUPM
22.
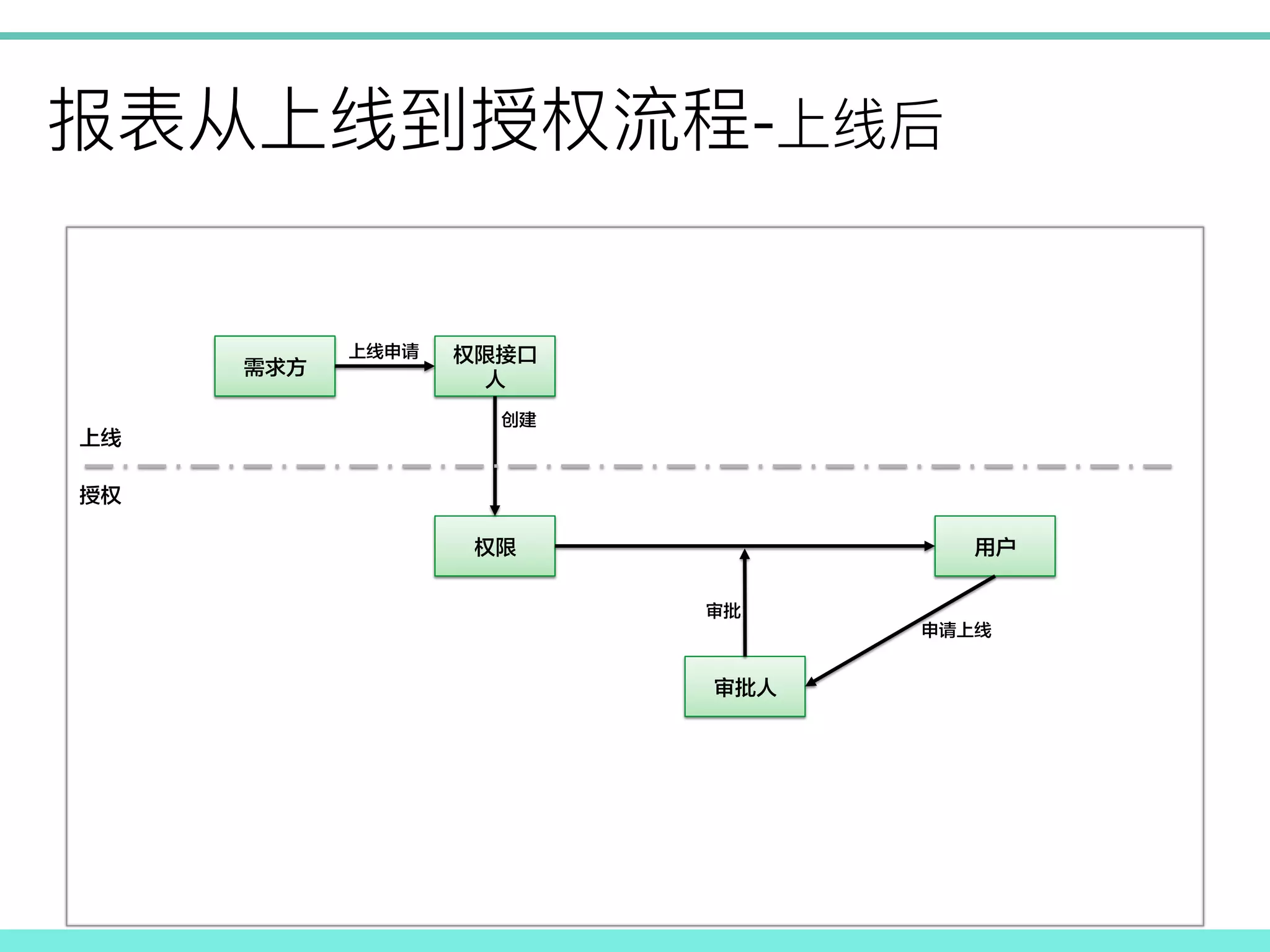
- ! 需求方 权限接口 人 权限 用户 创建 上线 授权 上线申请 审批人 审批 申请上线
23.
! UPM log
24.
!
25.
!
26.
/ !
27.
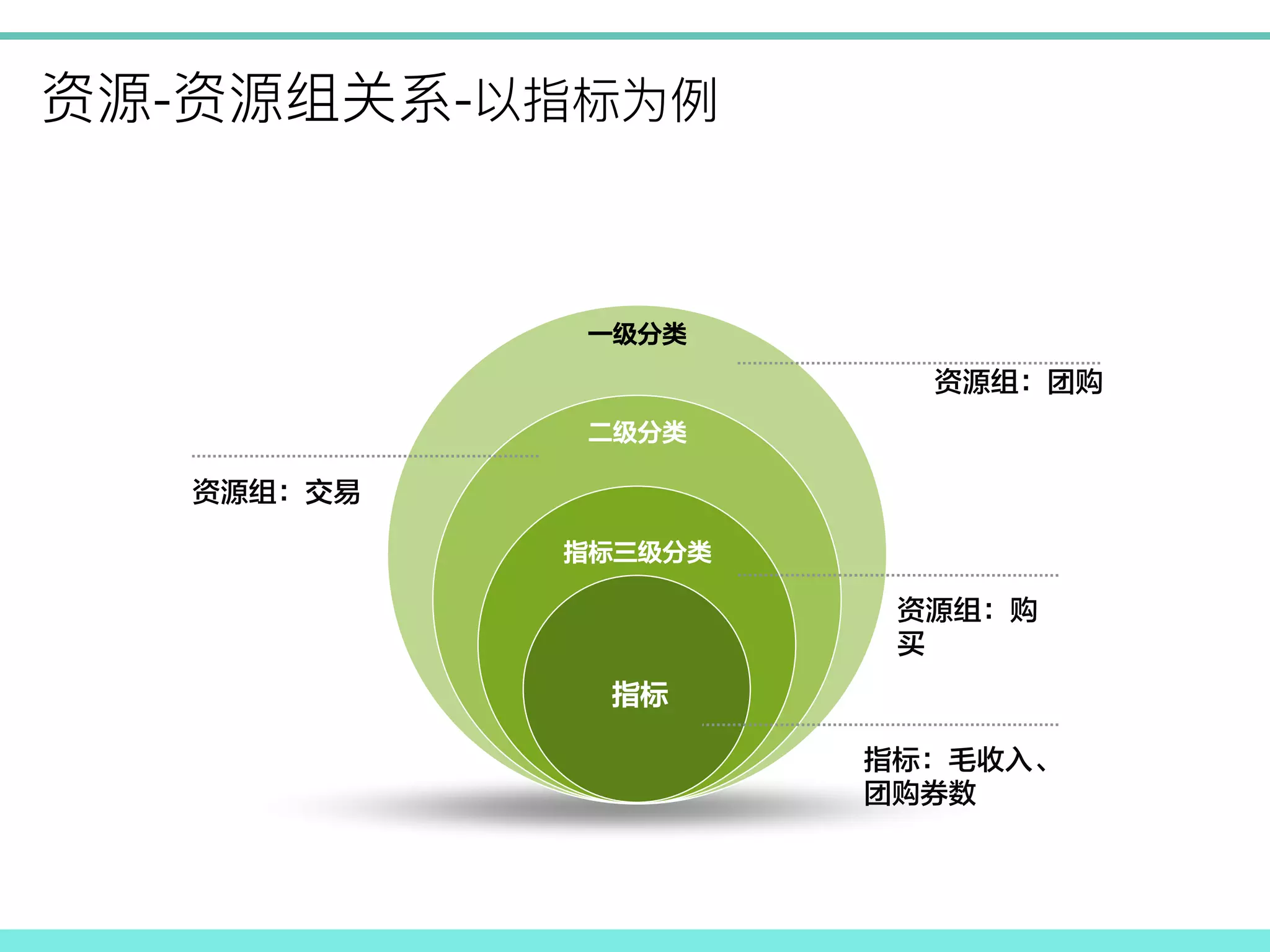
- - ! 一级分类 二级分类 指标三级分类 指标 资源组:团购 资源组:交易 资源组:购 买 指标:毛收入、 团购券数
28.
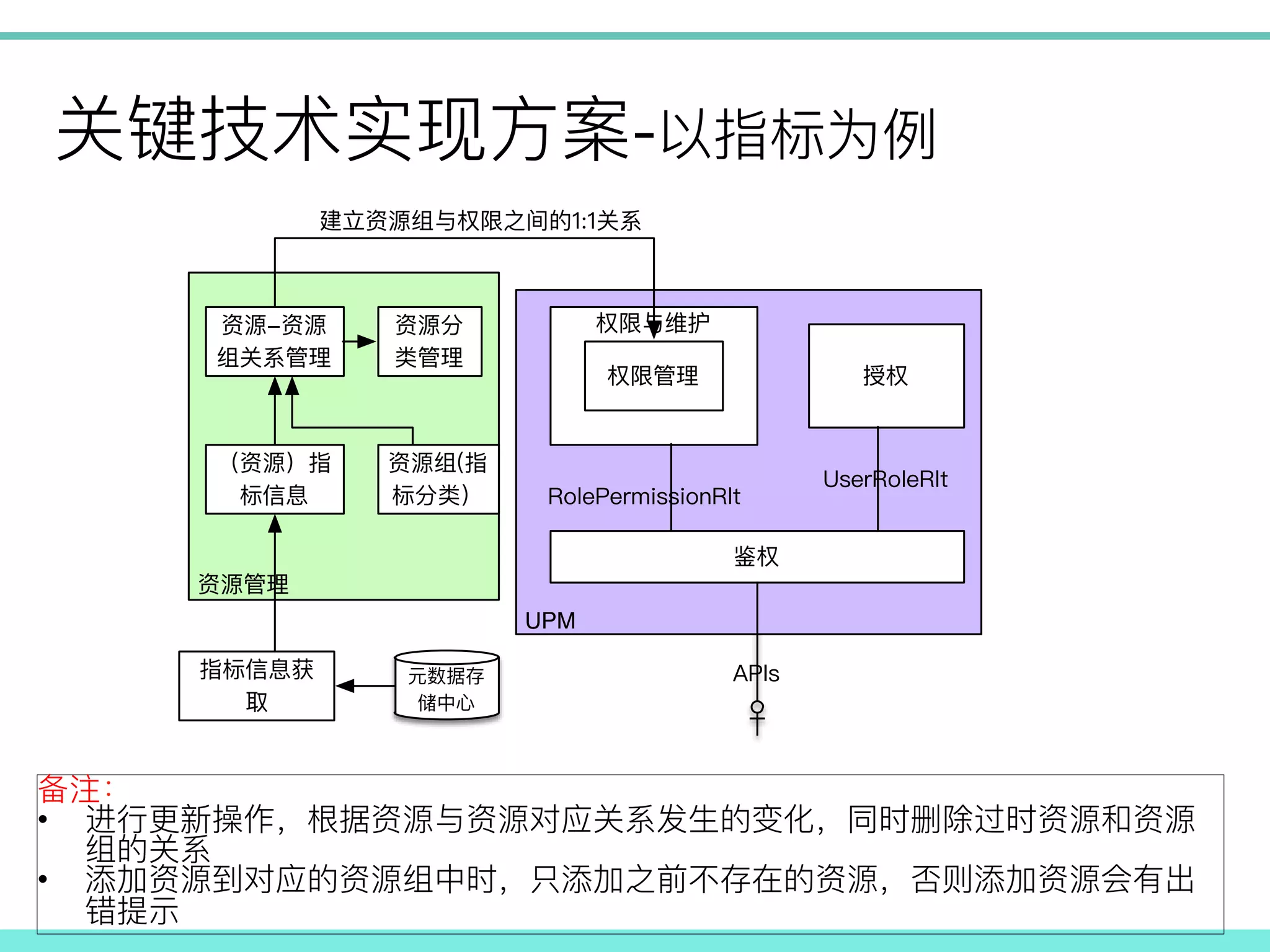
- ! ! • ! • ! UPM
29.
/ !
30.
! UPM
31.
UserRoleContext ! • ! •
! -
32.
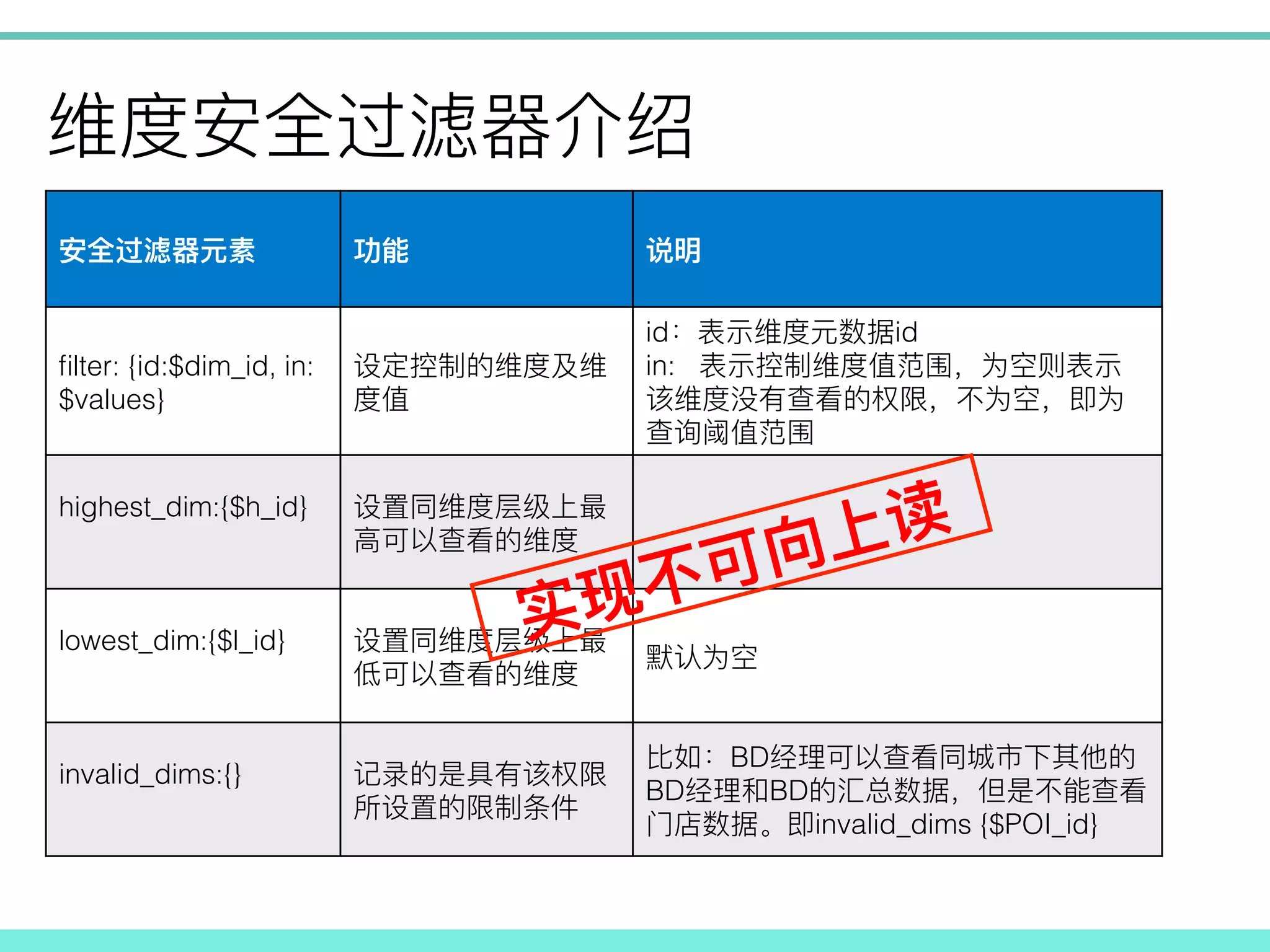
! filter: {id:$dim_id, in: $values}
! ! id id! in: ! highest_dim:{$h_id}! ! ! lowest_dim:{$l_id} ! ! ! ! invalid_dims:{}! ! ! BD BD BD invalid_dims {$POI_id}!
33.
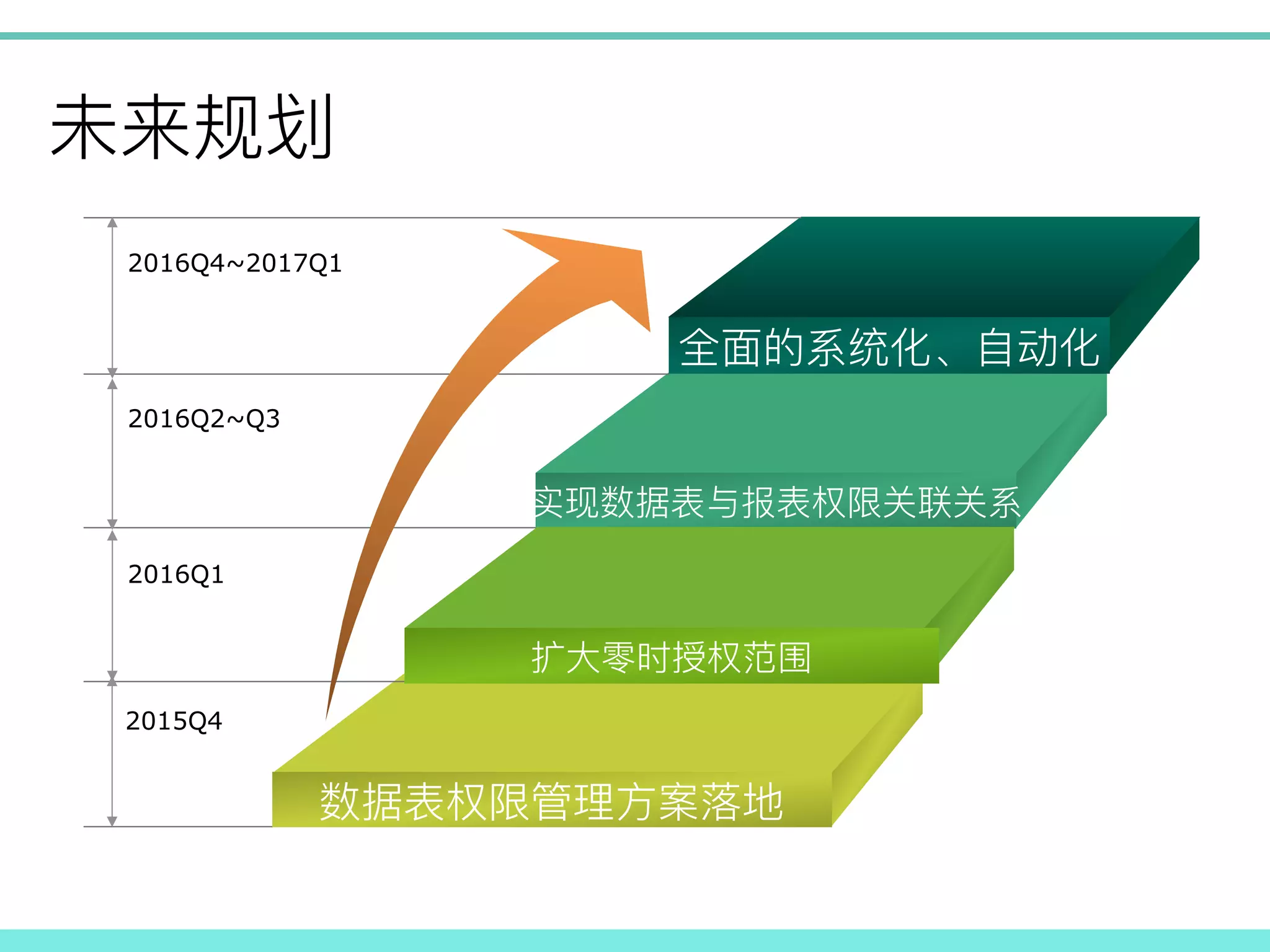
! 2016Q4~2017Q1 2016Q2~Q3 2016Q1 2015Q4
34.
QA!
Download


































![[NDC17] Kubernetes로 개발서버 간단히 찍어내기](https://cdn.slidesharecdn.com/ss_thumbnails/ndc-170529041601-thumbnail.jpg?width=640&height=640&fit=bounds)












![[발표자료] 오픈소스 기반 고가용성 Pacemaker 소개 및 적용 사례_20230703_v1.1F.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/pacemaker20230703v1-230704025923-34e1a3f3-thumbnail.jpg?width=640&height=640&fit=bounds)























