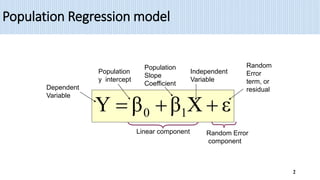
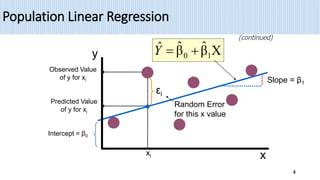
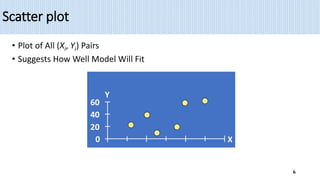
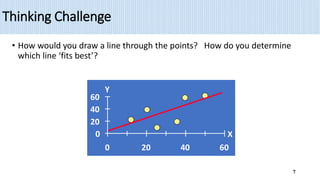
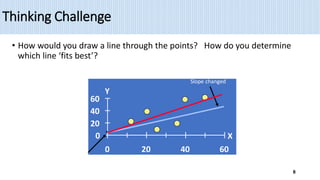
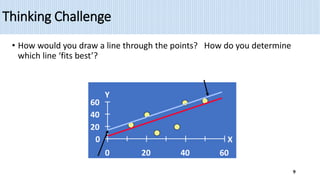
1) Simple linear regression models the relationship between a dependent variable (Y) and a single independent variable (X) as a linear equation. It finds the line of best fit to the data and uses this to estimate or predict future values of Y based on X.
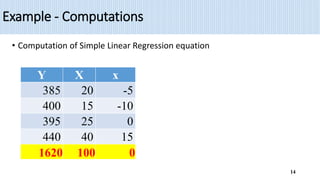
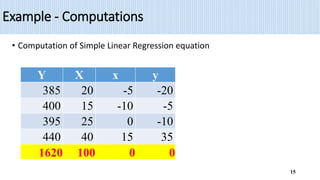
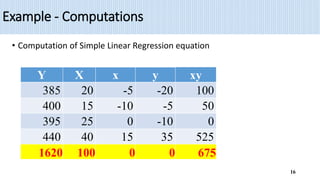
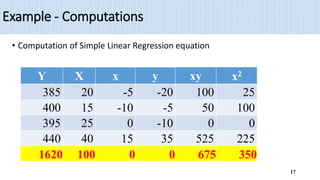
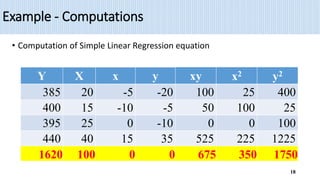
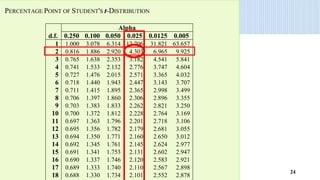
2) The document provides an example of using simple linear regression to model the relationship between weekly sales (Y) and advertising expenditures (X) for a retail merchant. It estimates the regression equation and uses this to predict sales for a given expenditure level.
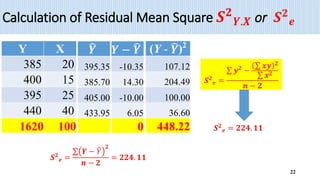
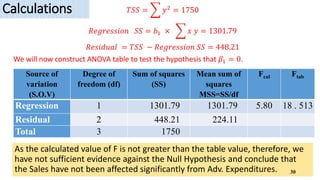
3) Key outputs of the simple linear regression analysis are presented, including estimating the regression coefficients, testing their significance, calculating confidence intervals and analyzing the variance (ANOVA).