Download as PDF, PPTX





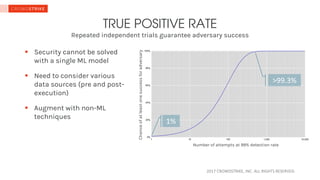
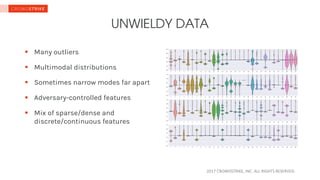




The document discusses the challenges of applying machine learning in information security, highlighting issues such as high false positive rates, the need for multiple models, and the impact of data distribution differences. It emphasizes the importance of combining various data sources and non-ML techniques for effective security measures. Additionally, it points out the complexities of data management, including retraining and labeling costs, as significant factors affecting machine learning success in this area.



































































