Download to read offline



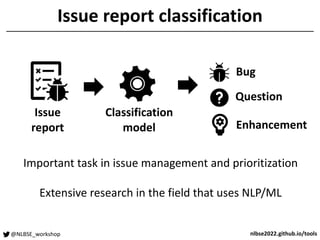
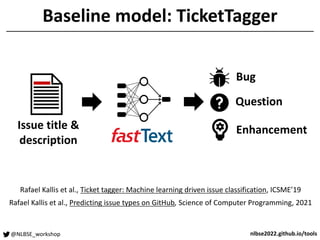





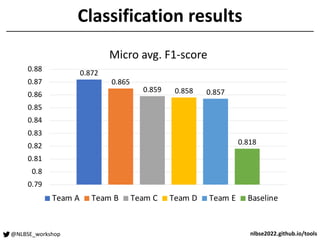
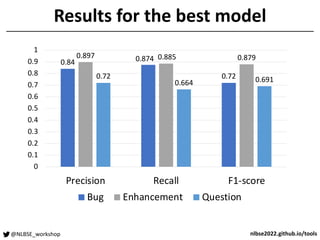





The document outlines a tool competition focused on developing accurate models for issue classification, with a baseline model based on a dataset of over 800,000 issue reports from GitHub. Five teams participated in the competition, evaluated based on their classification accuracy using metrics like precision, recall, and F1-score. Team rankings showed varying performances, with specific emphasis on model training challenges and future improvements discussed in a panel session.















































