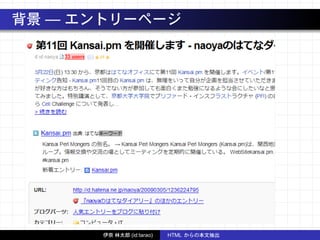
アルゴリズム — ブロックのつながり判定
本文が1 ブロックとは限らないので適度につなげる
• 高スコアのブロックが連続したらクラスタっぽい
• スコアの低いブロックがきたらクラスタの切れ目っぽい
(ただし直前のブロックのスコアの高さにも配慮)
例:
低 A
高 B
高 C
低 D
低 E
高 F
低 G ← 低いけれど F が超高スコアなので切れ目にしない
高 I
⇒ クラスタは {B, C}, {F, G, I}
伊奈 林太郎 (id:tarao) HTML からの本文抽出
23.
アルゴリズム — 傾斜配点
ブログなどで,コメントは本文より低い点にしたい
• 上にある方が本文っぽいということにする
• スコアは下にいくほど減衰
⇒ 下にいくほどクラスタの切れ目と見なされやすい
例:
低 A
高 B
高 C
低 D
低 E
低 F ← 減衰して低スコアに
低 G
低 I ← 減衰して低スコアに
⇒ クラスタは {B, C}
伊奈 林太郎 (id:tarao) HTML からの本文抽出