Downloaded 17 times





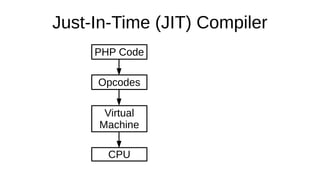
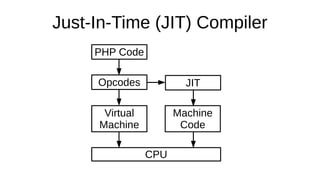








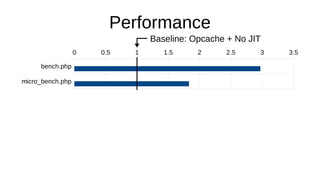
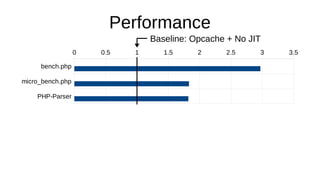
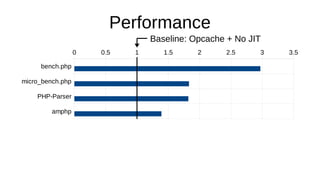
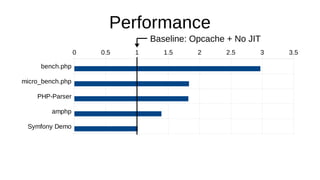
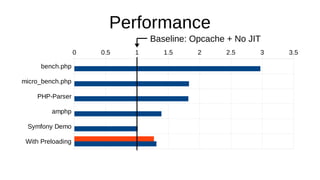


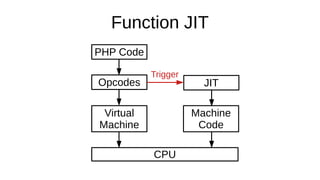












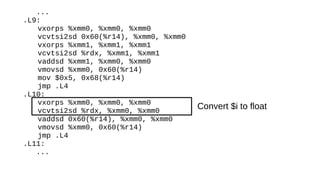
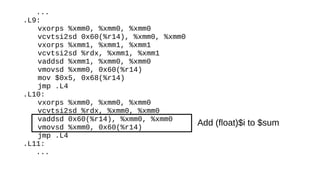
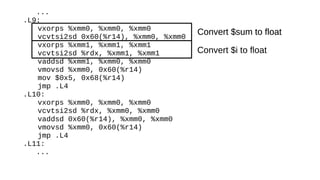


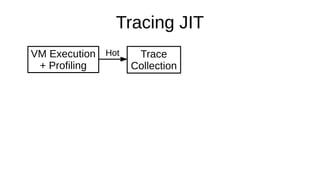
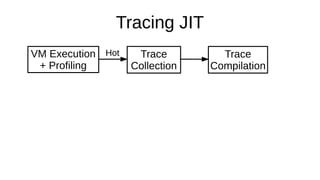
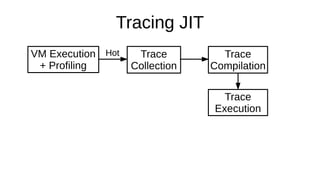
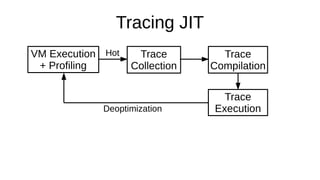







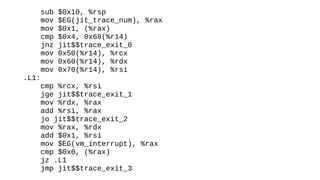
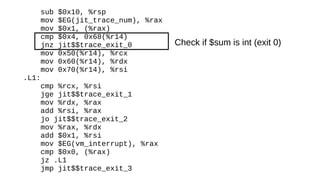
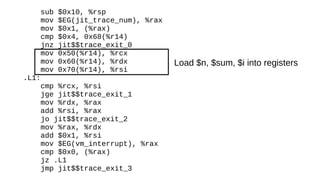
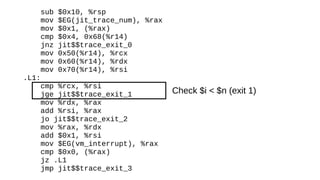
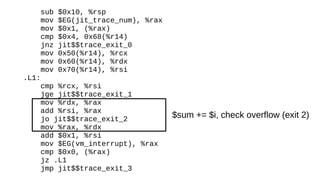
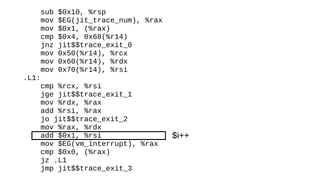
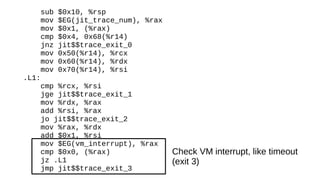
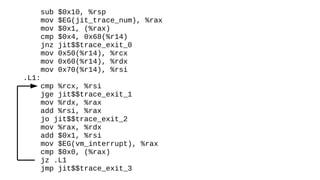

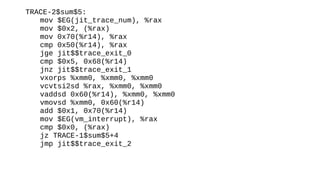


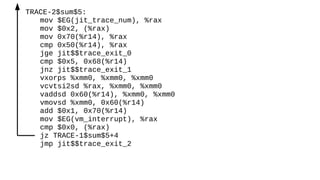








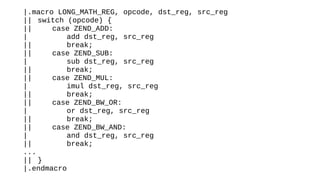








The document discusses the Just-In-Time (JIT) compiler that was introduced in PHP 8. It provides a brief history of JIT in PHP, explaining that early prototypes showed that the rest of PHP was too slow to benefit from JIT. It then discusses how optimizations from JIT were integrated into opcache without needing a full JIT. It provides information on configuring and using the JIT compiler, and shows performance improvements on benchmarks. It also provides an example of how a function is compiled to machine code by the JIT compiler.











































































